
Researchers from the Shanghai Artificial Intelligence Laboratory have developed MinerU, a cutting-edge open-source solution for precise document content extraction. MinerU is designed to extract and structure content from diverse document types, including academic papers, textbooks, and financial reports, by accurately identifying and parsing elements such as text, formulas, tables, and images. This automated extraction process converts complex PDFs into machine-readable formats like Markdown and JSON, making it easier to integrate document content into downstream NLP tasks and knowledge bases.
Supported document types:
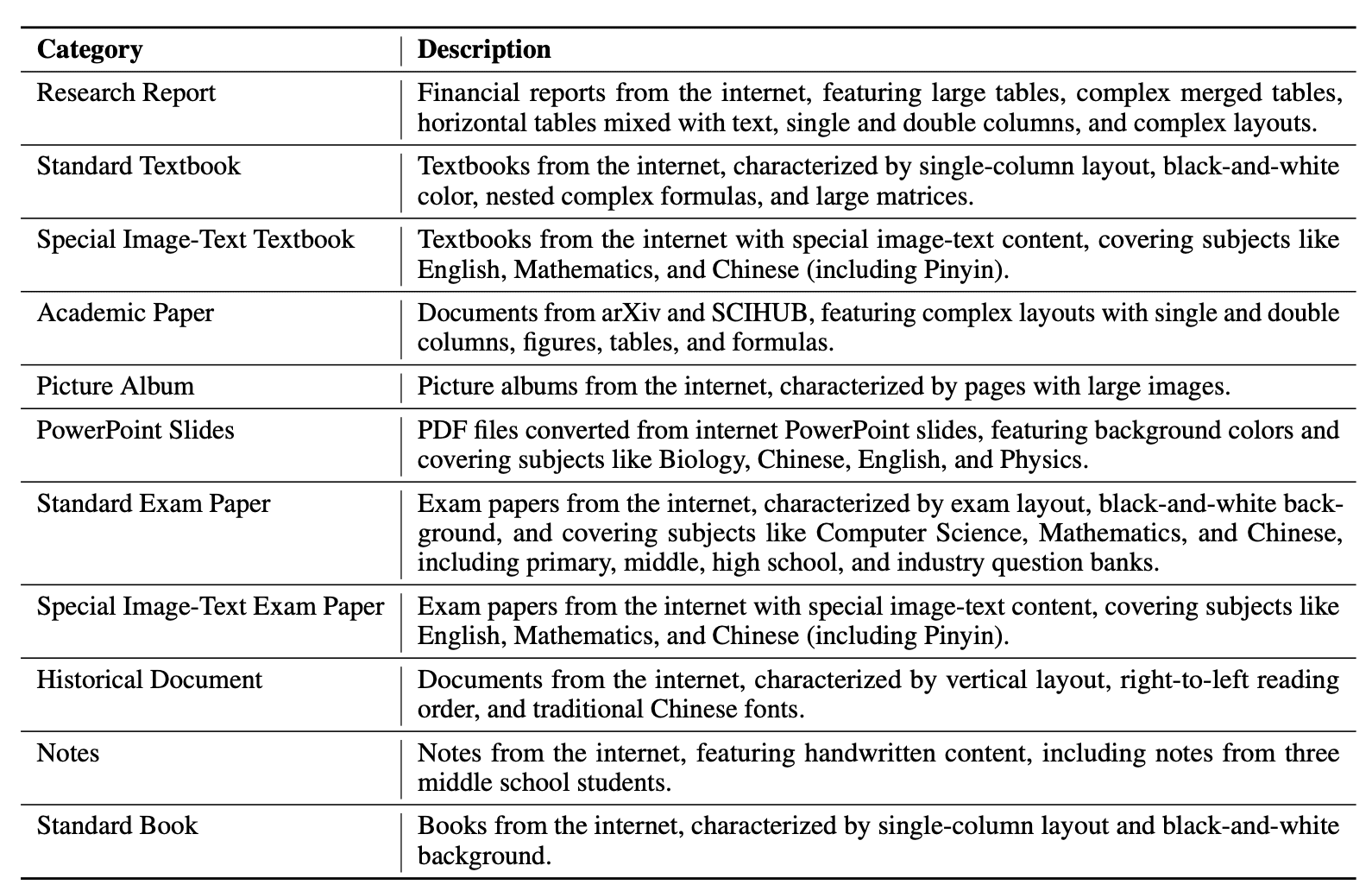
By the numbers:
- 11 distinct document categories in the evaluation dataset
- 24,157 inline formulas and 1,829 displayed formulas annotated for training
- Up to 93.3% AP50 on academic paper layout detection, surpassing previous SOTA
As large language models (LLMs) and retrieval-augmented generation (RAG) systems evolve, high-quality document extraction becomes crucial for enhancing training data and knowledge bases.
Model Architecture

MinerU employs a sophisticated multi-module approach, leveraging the PDF-Extract-Kit models as its foundation. At its core, the system integrates several state-of-the-art deep learning models, each fine-tuned for specific document parsing tasks. Layout detection utilizes a LayoutLMv3-based model, fine-tuned on diverse document types to accurately identify structural elements. For formula detection, the team implemented a custom-trained YOLOv8-based model, pushing the boundaries of object detection in document analysis.
Formula recognition is handled by the UniMERNet model, known for its robustness in handling complex mathematical expressions. Table recognition combines the strengths of TableMaster and StructEqTable, addressing the challenges of diverse table structures. Optical Character Recognition (OCR) is powered by the Paddle-OCR integration, ensuring high-quality text extraction. This ensemble of specialized models, working in concert, enables MinerU to handle the intricacies of varied document types with unprecedented accuracy.
AI Document Extraction Results and Comparison
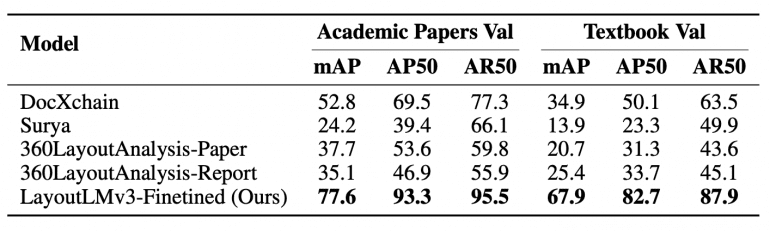
- Layout detection: 77.6% mAP on academic papers (vs. 52.8% for DocXchain)
- Formula detection: 87.7% AP50 on academic papers (vs. 60.1% for Pix2Text-MFD)
- Formula recognition: 0.968 CDM score (comparable to commercial Mathpix at 0.951)
Open Code
MinerU’s GitHub repository provides researchers and practitioners with complete processing pipeline, pre-trained models, diverse evaluation datasets, extensible architecture for further improvements.
The team plans to:
- Enhance core components with iterative model updates;
- Optimize inference speed for real-time applications;
- Develop a comprehensive benchmark for diverse document types.
MinerU represents a significant leap in open-source document extraction technology, offering state-of-the-art performance across varied document types and laying the groundwork for improved LLM training and RAG system development.







