InCoder-32B-Thinking: Open-Source Code Generation Model for Microcontrollers, GPU Kernel Optimization, and RTL Design
7 April 2026

InCoder-32B-Thinking: Open-Source Code Generation Model for Microcontrollers, GPU Kernel Optimization, and RTL Design
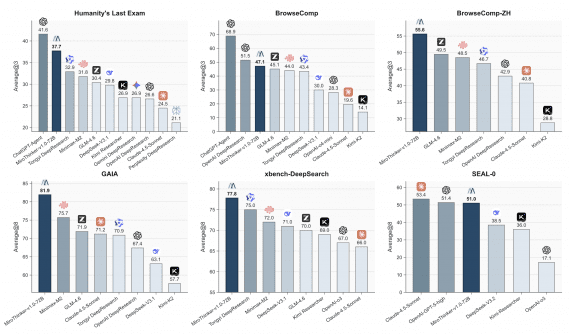
A research team from Beihang University, Shanghai Jiao Tong University, the University of Manchester, and IQuest Research has published InCoder-32B-Thinking — a language model with an extended chain-of-thought reasoning for…