Researchers from Zhejiang University have released R1-Onevision, a 7B parameters multimodal reasoning model that processes and analyzes visual inputs with unprecedented logical precision, capable of understanding complex mathematical, scientific, and engineering problems across domains. R1-Onevision marks a measurable advance in multimodal reasoning capabilities, with state-of-the-art performance metrics outperforming GPT-4o in maths.
The model specifically bridges the critical gap between visual perception and logical deduction through a novel formal language-driven approach. This integration transforms pixel-based information into structured representations that can be systematically reasoned about, creating new possibilities for AI applications in education, research, and engineering fields where complex visual reasoning is essential.
The researchers have open-sourced the R1-Onevision dataset, benchmark, and model. All resources are available through GitHub, Hugging Face, and an interactive web demo.

Model Technical Architecture
R1-Onevision is built upon the Qwen2.5-VL-Instruct architecture and was developed using the open-source LLama-Factory library with specific technical parameters optimized for reasoning tasks.
This diagram illustrates the R1-Onevision model development pipeline, divided into two main phases:
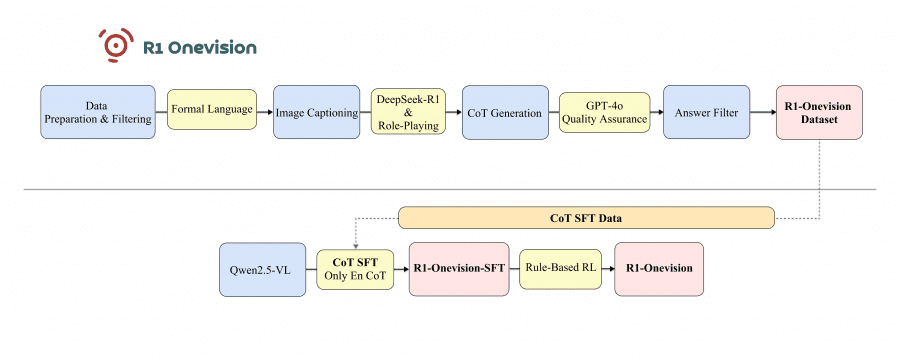
The upper section shows the dataset creation process: starting with data preparation and filtering, followed by formal language transformation, image captioning, and Chain-of-Thought (CoT) generation using DeepSeek-R1 and role-playing techniques. The process continues with quality assurance performed by GPT-4o and answer filtering, ultimately producing the R1-Onevision Dataset.
The lower section depicts the model training workflow: beginning with Qwen2.5-VL as the base model, applying Chain-of-Thought Supervised Fine-Tuning (CoT SFT) using the dataset created above, resulting in R1-Onevision-SFT. This is further enhanced through Rule-Based Reinforcement Learning (RL) to produce the final R1-Onevision model. The dotted lines indicate the flow of CoT SFT data from the dataset to the training process.
Dataset
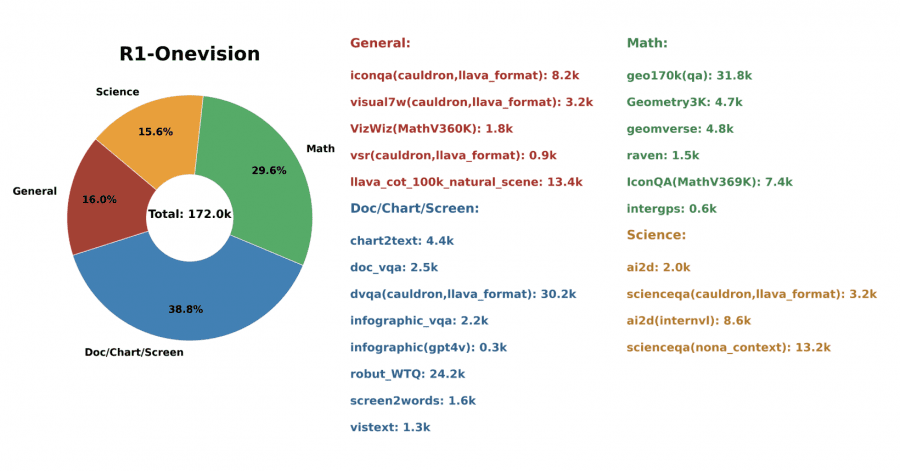
The R1-Onevision dataset was methodically constructed to enable robust multimodal reasoning. The development team curated diverse sources spanning natural images, OCR samples, charts, text-image pairs, mathematics, science, and logical reasoning problems.
The dataset creation process follows a four-phase methodology. First, various image types were collected and filtered for quality and relevance to reasoning tasks. Second, these images underwent formal annotation using a combination of tools: GPT-4o for generating descriptive captions and translating visuals into formal representations, Grounding DINO for providing spatial object coordinates, and EasyOCR for extracting text from images.
In the third phase, the DeepSeek-R1 model generated initial Chain-of-Thought reasoning based on the formal caption representations. This was enhanced through a role-playing approach that simulated visual understanding through iterative refinement. Finally, quality control was applied using GPT-4o to filter out reasoning paths containing logical errors or inconsistencies.
The resulting dataset contains structured entries with unique identifiers, image paths, ground truth values, data sources, conversational elements, validity filters, and quality assessment metrics—all designed to support comprehensive training for multimodal reasoning tasks.
Results and Comparisons
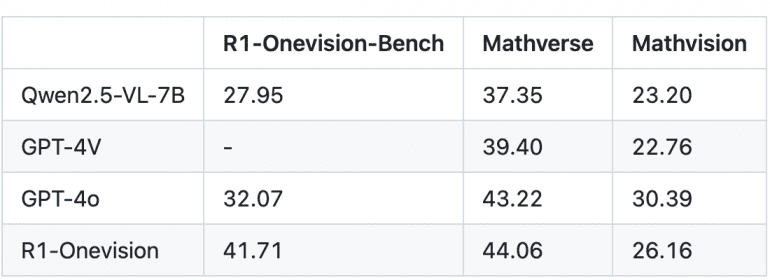
R1-Onevision demonstrates superior performance across multiple benchmarks when compared to leading models including GPT-4o, GPT-4V, and Qwen2.5-VL-7B:
- On R1-Onevision-Bench: R1-Onevision achieved 41.71, significantly outperforming GPT-4o (32.07) and Qwen2.5-VL-7B (27.95)
- On Mathverse: R1-Onevision scored 44.06, surpassing GPT-4o (43.22), GPT-4V (39.40), and Qwen2.5-VL-7B (37.35)
- On Mathvision: R1-Onevision reached 26.16, performing between GPT-4o (30.39) and GPT-4V (22.76)
The model demonstrates particular strengths in pattern recognition, mathematical problem-solving, geometric reasoning, physics calculations, circuit analysis, and algorithmic challenges. Documented examples show its ability to systematically work through complex reasoning chains to arrive at accurate conclusions across diverse problem domains.
These results validate the effectiveness of the formal language-driven visual reasoning approach and the rule-based reinforcement learning framework in enhancing multimodal reasoning capabilities beyond what was previously possible with existing models.
Future Development
The R1-Onevision team is actively pursuing several development initiatives to further enhance the model’s capabilities. Advanced AI techniques are being explored, including deeper integration of domain-specific rules with learning processes and expansion of training data with more general content alongside specialized multimodal reasoning Chain-of-Thought examples.
Accessibility improvements form another key focus area, with ongoing work to develop multilingual support through Chinese reasoning data integration and the creation of a more efficient 3B parameter version designed for resource-limited environments. These developments aim to make advanced multimodal reasoning more widely available across different languages and computational contexts.