
Researchers from UC San Diego and NVIDIA found a way to represent images in a continuous manner by learning an implicit function that allows presenting images in an arbitrary resolution.
Using self-supervised learning researchers train an encoder deep neural network that generates continuous representations of images originally presented in discrete pixel space. They propose a self-supervised super-resolution learning framework that learns how to generate a continuous representation. As shown in the diagram below, a training image is randomly down-sampled to obtain an input-ground truth mapping for that image, where the input is the lower resolution image. Using the encoder network the low-resolution input is encoded into the LIIF continuous representation. Researchers used L1 loss to optimize and train the encoder network.
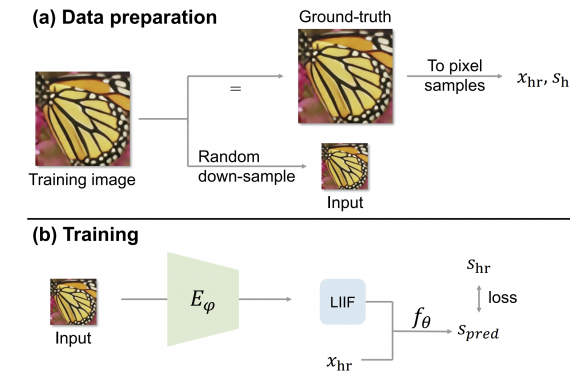
The DIV2K dataset was used to evaluate the performance of the proposed method. Using around 1000 high-resolution images, researchers trained their network and compared it to existing methods. Results showed that the proposed LIIF method outperforms existing methods on several datasets and moreover showed that the improvement margin increases for out-of-distribution samples e.g. resolutions more than x4. To further verify the effectiveness of the LIIF representation, researchers used it for learning with size-varied ground truths.
The implementation of the new method was open-sourced and it is available on Github. More details about the training and the experiments can be read in the paper.


