WordCraft — это среда для тестирования общих знаний о мире у RL-агентов. Среда основывается на видеоигре Little Alchemy 2. Особенности WordCraft заключаются в ее легковесности и в том, что она содержит семантику реального мира. Исследователи оценили методы для обучения представлениям в среде. Кроме того, они предложили метод для интеграции графов знаний с RL-агентом.
Описание проблемы
Способность быстро решать широкий спектр задач реального мира требует наличие здравого представления о мире. Однако проблема интеграции корпуса на естественном языке с RL-агентами остается актуальной. Отчасти это из-за отсутствия легковесных сред для симуляции, которые достаточно полно отражают семантику реального мира. Исследователи создали WordCraft, чтобы облегчить обучение агентов общим знаниям о мире.
Как устроена среда
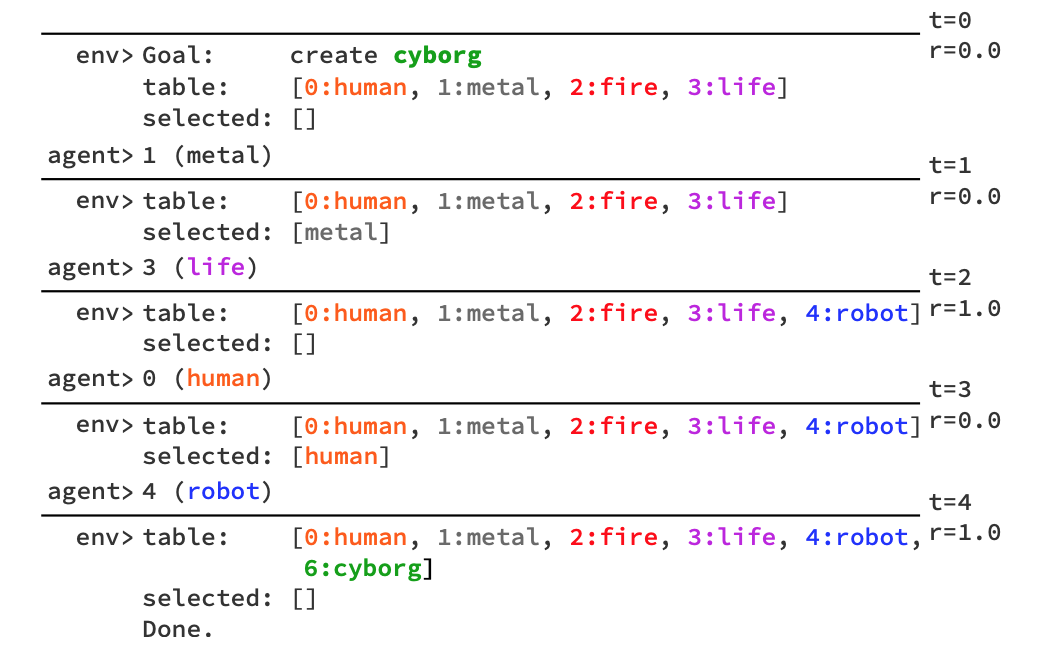
RL-среда WordCraft основывается на видеоигре Little Alchemy 2. Little Alchemy 2 — это простая ассоциативная игра. Игрок получает начальный набор из четырех предметов. Из этого начального набора игрок должен собрать как можно больше новых предметов. Каждый новый предмет может быть создан через объединение двух других предметов. Например, объединение “луны” и “бабочки” дает “моль”. Всего 700 предметов и 3,417 возможных комбинаций предметов.
Решение игры без попытки попробовать все возможные комбинации требует наличия знаний о взаимосвязях между общими концептами. WordCraft — это упрощенная версия Little Alchemy 2:
- Интерфейс у среды текстовый, а не графический, как в Little Alchemy 2;
- Вместо одной открытой задачи, в WordCraft множество простых задач. Каждая задача создается через случайное семплирование целевого предмета, составных предметов и отвлекающих предметов
Задача агента — выбрать, из каких предметов состоит целевой предмет. Сложность задачи регулируется с помощью двух показателей:
- Количества отвлекающих предметов;
- Количества промежуточных предметов, которые должны быть созданы, перед тем как будет возможность создать целевой предмет
Тестирование алгоритмов в среде
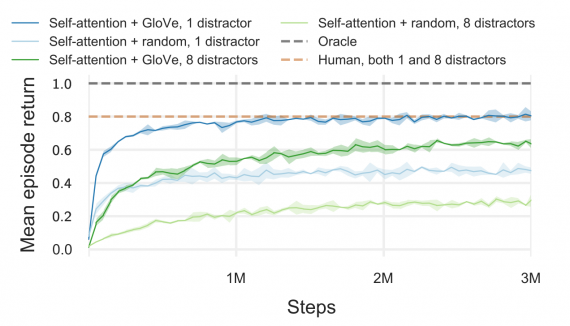
Исследователи тестировали алгоритмы обучения представлениям в среде на задаче zero-shot обобщения. Набор рецептов поделили на обучающую (80%) и тестовую (20%) выборки. В качестве модели использовали TorchBeast имплементацию IMPALA.