
Сравниваем подходы Random Forest, Poisson Regression и Ranking Methods
Внимание болельщиков приковано к представлению длиною в месяц — чемпионату мира по футболу 2018. Некоторые команды уже провели стартовые матчи в России, стадионы готовы, все пребывают в ожидании захватывающего турнира. Тем временем, букмекеры, футбольные эксперты, бывшие игроки и болельщики пытаются спрогнозировать результат — кто же станет обладателем драгоценного кубка на этот раз. Как мы уже видели в прошлом, шумиха вокруг чемпионата привнесла множество интересных и “инновационных” способов предсказания исходов матчей и победителя кубка мира. Одним из таких предсказателей был осьминог Пол — известный головоногий моллюск, который предсказывал результаты матчей чемпионата мира FIFA 2014. Точные предсказания во время чемпионата мира 2010 привлекли к нему всеобщее внимание общественности, его прозвали “оракулом из мира животных”.
Ученые тоже не теряли времени и постарались дать свои прогнозы, основанные на научном методе и данных из мира футбола. Недавно исследователи из Технического университета Дортмунда и Гентского университета представили метод предсказания результатов матчей чемпионата мира, основанный на алгоритме машинного обучения под названием random forest (“случайный лес”). Они сравнивали три разные модели: модели пуассоновской регрессии (poisson regression), методы случайных лесов (ranking forests) и методы ранжирования (ranking methods). Ученые выяснили, что подход, основанный на random forest, дает более достоверные прогнозы по сравнению с двумя другими.
Данные
Подход основывается на данных с прошлых чемпионатов мира, начиная с турнира 2004-го года и вплоть до турнира 2014-го. Исследователи составили базу данных, включающую информацию о командах и забитых мячах на прошедших 4-х кубках. Для описания команд в базе данных имеются переменные пяти типов:
экономические факторы, спортивные факторы, преимущество при игре дома, структура команды и тренерский фактор. Идея заключается в использовании 16-ти переменных для моделирования предстоящей игры и прогнозирования счета, представляющего переменную ответной реакции (response variable). Фактически они используют количество забитых голов как переменную ответной реакции и реструктурируют базу данных соответствующим образом (в данном случае число голов при игре команды A против команды B — другие переменные, представляющие другие факторы). Таблица ниже демонстрирует данные, структурированные подобным образом.
Факторы
Ключ к успешному моделированию и высокой прогностической силе (predictive power) это правильный выбор прогностических переменных (predictive variables),
то есть факторов, которые потенциально способны повлиять на результат игры (хотя мы все знаем, что результат футбольного матча тяжело предсказать). Как уже было сказано, авторы поделили факторы, которые они выбрали для исследования и о которых собирали информацию на 5 групп.
Экономические факторы:
- GDP на душу населения (Внутренний валовый продукт на момент проведения чемпионата)
- Численность населения страны
Спортивные факторы:
- Букмекерские ставки из центрального агентства ставок в Германии
- Ранг страны в соответствии с системой ранжирования FIFA
Преимущество при игре дома:
- Хозяин (Является ли страна принимающей страной или нет)
- Континент (Находится ли рассматриваемая страна на том же континенте, что и принимающая страна)
- Конфедерация (Конфедерация, которой страна принадлежит)
Структура команды:
- Максимальное число игроков одного клуба в сборной.
- Средний возраст
- Количество игроков, играющих в лиге чемпионов и в европейской лиге
- Количество игроков из-за рубежа
Тренер команды:
- Возраст
- Срок полномочий (Время, проведенное в качестве тренера)
- Национальность
Методы
Random forest
В своей работе исследователи применяют метод random forest, используя введенные 16 прогностических переменных и число забитых мячей как переменную ответной реакции.
Чтобы предотвратить overfitting (переобучение) тренировочных данных, они строят деревья в случайном лесу, подлежащие обрезке (pruning), а каждый листовой узел (leaf node) соответствует распределению переменной ответной реакции — количество голов в виде простого boxplot (диаграмма размаха, “ящик с усами”).
Прежде чем просто запустить алгоритм для создания случайного леса, они проводят анализ значимости переменной, чтобы определить вклад каждой из прогностических переменных в конечный результат. Для построения графика значимости переменной, к деревьям в лесу применяется основанный на перестановках подход (permutation-based approach). Таким образом, оказывается, что игроки Rank, Oddset и CL являются наиболее важными переменными, несущими наибольшую прогностическую силу. Диаграмма из столбцов показывает ранжированные по прогностической силе переменные.
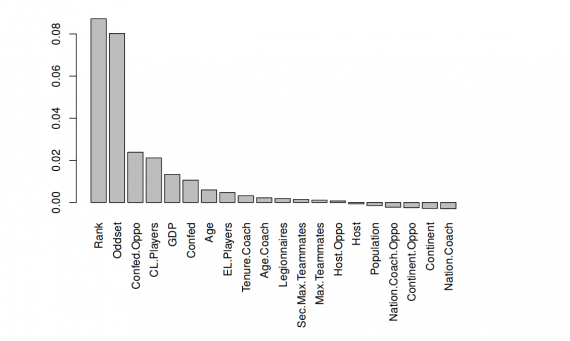
Регрессия
Аналогично методу random forest авторы используют регрессию Лассо для предсказания результатов, обеспечивая выбор переменных. Они определяют расстояние или разницу между значениями прогнозируемых переменных и пытаются спрогнозировать счет в каждом матче (количество забитых голов для каждой команды).
Методы ранжирования
Кроме того, исследователи используют модель Пуассона, чтобы получить рейтинг команд, который отражает её текущие возможности. Они используют рейтинг FIFA для определения важности матча, придавая большее значение недавним играм.
Прогнозы
В итоге, они объединяют три уже упомянутых метода, используя общую процедуру:
- Формирование набора тренировочных данных, включающего три чемпионата мира из четырех.
- Подгонка каждого из методов к тренировочным данным.
- Предсказание результатов чемпионата мира с использованием каждого метода.
- Повторение шагов 1–3 таким образом, чтобы каждый из четырех чемпионатов был один раз оставшимся (необработанным).
- Сравнение спрогнозированного и реального результата для каждого из методов.
Метод leave-one-out гарантирует, что каждый матч в базе данных один раз является частью тестируемого набора (test set).
Сравнение трех методов а также их сравнение с букмекерскими прогнозами приведены в таблице.

Наконец, поскольку каждый хочет знать победителя, предсказание метода random forest: Испания! Подход дает небольшое преимущество Испании перед Бразилией и действующим чемпионом Германией. Исследователи запускают симуляцию и прогнозируют результаты группового этапа, конкретные матчи ⅛-й и получают вероятность достижения определенных этапов турнира для каждой команды.
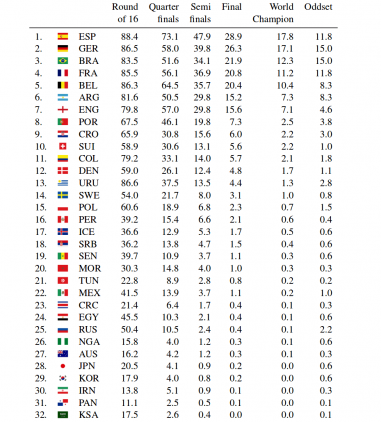
Судя по тому что тренер сборной Испании был уволен перед началом ЧМ, сборная Германии должна стать первой в списке.
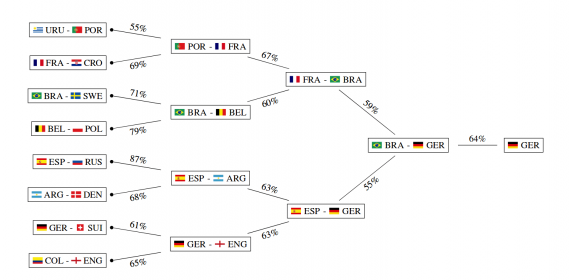
Прогоняя 100000 симуляций, исследователи представляют наиболее вероятное течение турнира. Согласно наиболее вероятному курсу, не испанская, а немецкая сборная станет обладателем кубка мира. Как показано на диаграмме, симуляция предсказывает в финале матч между Бразилией и Германией.
Наиболее вероятная итоговая сетка чемпионата:
Предсказанные результаты группового этапа:
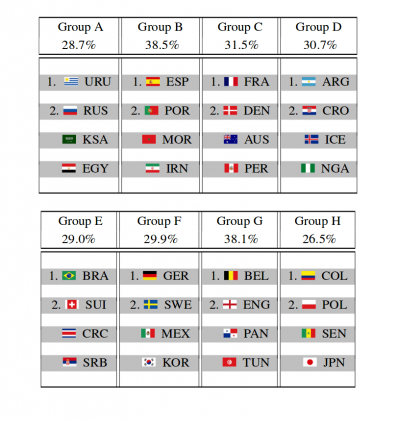
P.S Ни сборная Испании, ни сборные Бразилии и Германии не смогли победить в своих первых матчах на турнире. Остаются ли они фаворитами на ваш взгляд?
Оригинал — Dane Mitrev, перевод — Карим Боршигов



