Команда исследователей из китайской компании Baichuan представила Baichuan-M3 — открытую медицинскую языковую модель, которая вместо традиционного режима «вопрос-ответ» ведет полноценный клинический диалог, активно собирая анамнез и принимая взвешенные медицинские решения. Модели и веса доступны на Hugging Face, исходный код платформы оценки и примеры проектов опубликованы на GitHub под коммерческой лицензией Apache 2.0.
Следующий шаг в медицинском ИИ
Представьте типичную ситуацию: вы приходите к врачу с жалобой на головную боль. Обычная медицинская ИИ-модель просто выдаст готовый список возможных причин и стандартные рекомендации. Baichuan-M3 же поведёт себя как опытный терапевт — начнёт методично выяснять детали: когда именно началась боль, какого она характера, есть ли сопутствующие симптомы, какие лекарства вы принимаете, были ли подобные эпизоды раньше. Только собрав достаточно клинической информации, модель сделает обоснованный вывод.
Идея активного клинического диалога появилась в медицинском ИИ не сегодня. В начале 2024 года Google DeepMind представила AMIE (Articulate Medical Intelligence Explorer) — систему, специально оптимизированную для диагностических бесед и сбора анамнеза, которая в исследовании с актёрами-пациентами превзошла врачей первичного звена по 30 из 32 осей клинической оценки. Однако AMIE оставалась закрытой исследовательской моделью без публичных весов и без результатов на стандартных воспроизводимых бенчмарках. Baichuan-M3 идёт тем же путём, но делает это открыто и с измеримыми результатами.
Модель демонстрирует три ключевые способности, которые отличают её от большинства предшественников.
- Активный сбор информации — M3 не ждёт, когда пациент сам расскажет все подробности, а проактивно задаёт правильные диагностические вопросы;
- Модель использует многоэтапное рассуждение, связывая разрозненные симптомы в логичную диагностическую картину точно так же, как это делают врачи;
- Baichuan-M3 оснащена продвинутым алгоритмом контроля медицинских галлюцинаций, который активно проверяет каждое утверждение, чтобы не генерировать потенциально опасную дезинформацию.
Трёхэтапная методика обучения врачебному мышлению
Создание Baichuan-M3 — это не простое дообучение языковой модели на медицинских текстах, а сложный процесс, имитирующий подготовку настоящих врачей. Исследователи разработали уникальную трёхэтапную методику, которая позволяет модели освоить различные аспекты клинической практики без взаимного конфликта задач.
На первом этапе команда создала узкоспециализированных экспертов через Task-Specific Reinforcement Learning (TaskRL). Одного «врача» обучали исключительно клиническим опросам — умению собирать симптомы и анамнез пациента. Второго специализировали на консультировании по вопросам здоровья и общих медицинских рекомендациях. Третий эксперт фокусировался на фундаментальном медицинском рассуждении и диагностической логике. Каждый получал награды только за свою узкую специализацию, что позволило избежать конфликтов целей, типичных для многозадачного обучения.
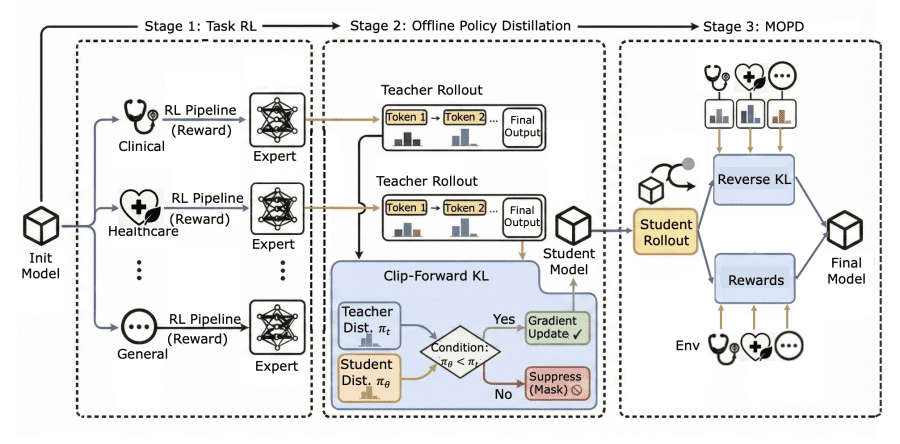
Второй этап представлял собой процесс «объединения знаний» через Offline Policy Distillation, где создавалась модель-студент, способная учиться у всех экспертов одновременно. Здесь применялся специальный алгоритм Clip-Forward-KL, который позволяет модели перенимать лучшие качества каждого учителя, не теряя при этом уже изученных навыков. Это критически важно, поскольку стандартные подходы часто приводят к «забыванию» предыдущих знаний при освоении новых.
Финальный этап включал Multi-Teacher Online Policy Distillation (MOPD) — настройку объединённой модели в реальной клинической среде. На этой стадии модель начинала получать обратную связь от множественных учителей одновременно, учась балансировать различные аспекты медицинской практики и адаптировать своё поведение под конкретные клинические сценарии.
Алгоритм SPAR: пошаговое совершенствование медицинского диалога
Для обучения навыкам врачебного опроса исследователи разработали алгоритм SPAR (Step-Penalized Advantage with Relative baseline), который кардинально отличается от традиционных подходов. Если обычные методы обучения с подкреплением оценивают медицинский диалог целиком — как хороший или плохой, то SPAR анализирует эффективность каждой реплики в отдельности.
Алгоритм работает в две фазы, создавая естественную учебную программу. Первая фаза фокусируется на исправлении критических ошибок — повторов в вопросах, нарушений логической последовательности, некорректных медицинских утверждений. Вторая фаза занимается тонкой шлифовкой стиля общения и профессионализма, обучая модель деликатности в обращении с чувствительными темами и точности медицинской терминологии.
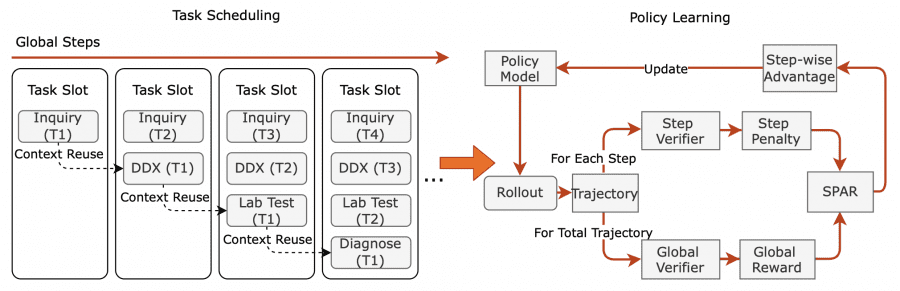
Такой подход позволяет модели точно понимать, какие конкретные фразы в диалоге способствовали успешной диагностике, а какие привели к проблемам или путанице. Это создаёт гораздо более точную обратную связь для обучения по сравнению с глобальными оценками эффективности консультации.
Fact-Aware Reinforcement Learning
Одна из самых серьёзных проблем современных медицинских ИИ — склонность генерировать правдоподобно звучащие, но фактически неверные утверждения. В медицине такие «галлюцинации» могут иметь смертельные последствия, поэтому Baichuan-M3 оснащена продвинутым алгоритмом Fact-Aware Reinforcement Learning.
Алгоритм работает как тщательный факт-чекер в режиме реального времени. Каждый ответ модели автоматически разбирается на отдельные медицинские утверждения — от симптомов и диагнозов до рекомендаций по лечению. Затем каждое утверждение проверяется через поиск в авторитетных медицинских источниках и базах данных. Наконец, модель получает дифференцированную обратную связь: награды за проверенные факты и штрафы за неточности. Для оценки этой технологии авторы используют метрику HealthBench-Hallu — подход, при котором длинные ответы разбиваются на атомарные медицинские утверждения и каждое из них независимо проверяется по авторитетным источникам.
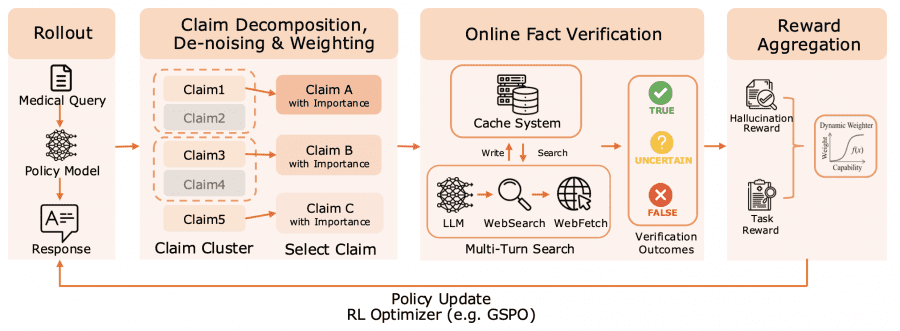
Ключевая особенность алгоритма — он учитывает клиническую важность каждого утверждения. Ошибка в постановке диагноза или назначении лечения повлечёт значительно больший штраф, чем неточность в общих рекомендациях по здоровому образу жизни. Это помогает модели сосредоточиться на наиболее критически важных аспектах медицинской практики.
Впечатляющие результаты клинических испытаний
Команда протестировала Baichuan-M3 на нескольких строгих бенчмарках, включая специально созданный для этого исследования ScanBench — симулятор приёма у врача. Этот тест воспроизводит полный цикл врачебной консультации, проводя модель через все этапы: от первичного опроса пациента и сбора анамнеза до назначения необходимых анализов и постановки финального диагноза.

На критически важном этапе клинического опроса M3 набрала 74.9 балла, значительно опередив GPT-5.2-High с результатом 62.5 балла и человека-врача с показателем 54.6 балла. Особенно поразительной оказалась способность модели к безопасной медицинской стратификации — выявлению «красных флагов» и критических симптомов, требующих немедленного внимания. Здесь M3 продемонстрировала результат 75.8 баллов против 48.3 балла у следующей лучшей модели и 40.1 балла у врачей-людей.
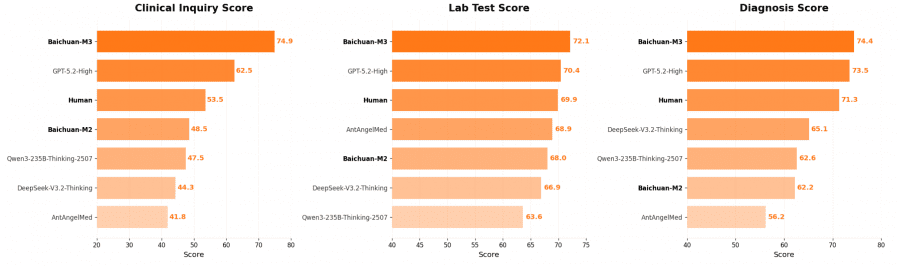
На авторитетном медицинском бенчмарке HealthBench модель показала результат 65.1 балла, превзойдя GPT-5.2-High с результатом 63.3. Особенно впечатляют результаты на сложной версии HealthBench-Hard, где M3 достигла 44.4 балла против 42.0 у GPT-5.2-High. При этом уровень медицинских галлюцинаций составил всего 3.5% — значительно ниже показателей конкурентов. Это означает, что M3 одновременно точнее в диагностике, и безопаснее в использовании.
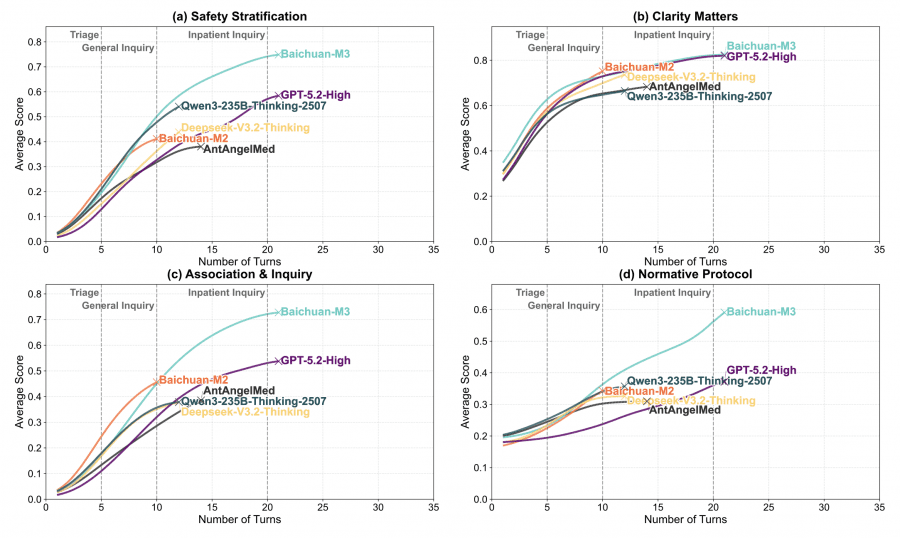
Особенно интересным оказался анализ эффективности модели в зависимости от длины диалога. В то время как простые медицинские ИИ-модели теряют фокус после нескольких вопросов, Baichuan-M3 демонстрирует стабильный рост эффективности. В долгих консультациях модель показывает почти двукратное преимущество в категории «Association & Inquiry», достигая высоких результатов там, где общие модели вроде Deepseek и Qwen значительно отстают.
Эффективный инференс
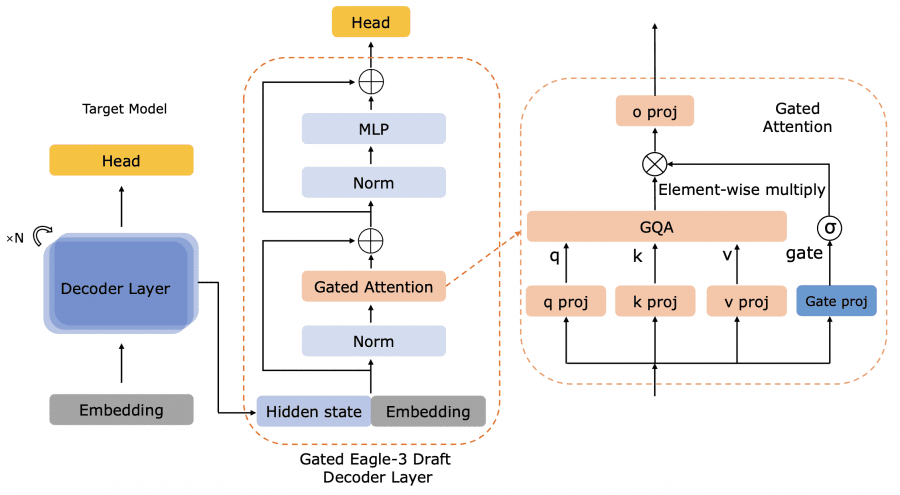
Понимая, что даже самая совершенная модель бесполезна без возможности эффективного развёртывания, команда предложила несколько оптимизаций. Алгоритм Gated Eagle-3 представляет собой улучшенную версию спекулятивного декодирования, которая ускоряет генерацию медицинских ответов на 12% по сравнению с базовой реализацией Eagle-3. Модуль Gated-Attention обеспечивает динамическое и управляемое регулирование обмена информацией между различными компонентами модели. Параллельно была создана специальная техника INT4 квантования с самогенерируемой калибровкой для Mixture-of-Experts, позволяющая сжать модель без потери диагностической точности.
Ограничения современной версии и планы развития
Текущая версия Baichuan-M3 работает исключительно с текстовыми эпизодическими сценариями, что означает её неспособность вести долгосрочное медицинское наблюдение пациентов или анализировать изображения вроде рентгеновских снимков или МРТ. Команда разработчиков уже планирует устранение этих ограничений в будущих версиях, добавляя мультимодальные возможности и расширяя способности работы с длинным контекстом для ведения медицинских карт пациентов.
Влияние на будущее медицины
Направление, в котором движется Baichuan-M3, — это не просто пассивный справочник медицинских знаний, а активный участник диагностического процесса. Это особенно критично в контексте глобальной нехватки медицинских кадров, где такие модели могут существенно повысить качество первичной медицинской помощи.
Решение сделать значительную часть проекта открытой создаёт уникальные возможности для медицинского сообщества. Исследователи по всему миру получают доступ к передовым технологиям для разработки специализированных решений, адаптированных под особенности национальных систем здравоохранения, местные медицинские протоколы и специфические потребности различных групп пациентов.
Исследование демонстрирует фундаментальный сдвиг парадигмы: будущее медицинского ИИ лежит не в создании всё более совершенных поисковых систем по медицинским базам данных, а в точном моделировании самого процесса врачебного мышления. Baichuan-M3 показывает, что искусственный интеллект может освоить не только медицинские знания, но и искусство их применения в сложных клинических ситуациях. Основные достижения проекта включают в себя:
- Проактивное ведение медицинского диалога — модель активно собирает анамнез, задавая правильные вопросы в нужной последовательности
- Надёжный контроль медицинской информации — технология проверки фактов минимизирует риск опасных галлюцинаций
Реальное превосходство Baichuan-M3 над предшественниками складывается из трёх факторов одновременно. Относительно собственного предшественника Baichuan-M2 прогресс очевиден: +28 пунктов на HealthBench-Hard и снижение галлюцинаций вдвое. Относительно GPT-5.2-High преимущество скромнее по цифрам, но принципиально по условиям — Baichuan-M3 открыта под коммерческой лицензией Apache 2.0, тогда как GPT-5.2 развернуть локально нельзя. Относительно AMIE от Google — системы, которая ещё в 2024 году показала превосходство над врачами в диалоговом опросе, — прямое сравнение невозможно: Google не публиковала результаты AMIE на HealthBench, а сама AMIE остаётся закрытой. Baichuan-M3 — первая модель этого класса, которую можно скачать, развернуть и независимо проверить, что само по себе меняет правила игры для медицинского сообщества.