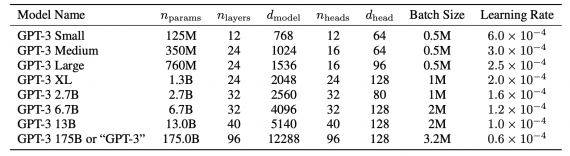
OpenAI анонсировали GPT-3, авторегрессионную языковую модель с 175 миллиардами параметров. Размер модели в 10 раз превышает размер предыдущей самой крупной языковой модели. Исследователи протестировали GPT-3 для few-shot обучения. Модель способна генерировать примеры новостных статей, которые сложно отличить от написанных людьми.
Прошлые исследования показали, что обучение модели на большом общем корпусе и дообучение ее на требуемой задаче дает значительный прирост при решении задач NLP. Архитектура таких моделей универсальна для решения любых задач. Несмотря на это, модель все еще необходимо дообучать на специфичных для задачи датасетах в тысячи и десятки тысяч примеров. При этом люди способны обучаться новой языковой задаче на основе пары примеров или инструкций. Исследователи показывают, что масштабирование языковых моделей улучшает способность модели к few-shot обучению. Кроме того, в некоторых случаях few-shot GPT-3 выдает сравнимые результаты с дообученной state-of-the-art моделью.
Few-shot обучение предполагает, что модель обучается решать задачу на основе пары примеров. В случае с GPT-3 эти примеры напрямую внедряли в входные тексты. GPT-3 хорошо справляется с такими задачами, как перевод, вопрос-ответ и cloze. При этом модель справляется с задачи, которые требуют рассуждения, как использование нового слова в предложении, арифметика с числами из трех цифр и unscrambling слов.
Тестирование работы модели
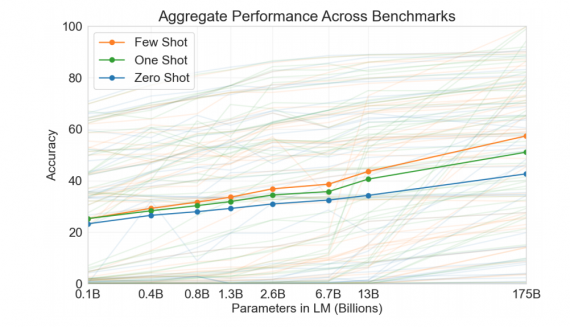
Исследователи сравнили модели разных размеров, которые обучались в разных сеттингах: few-shot, one-shot и zero-shot. Результаты модели при zero-shot обучении стабильно растут с увеличением размера модели.