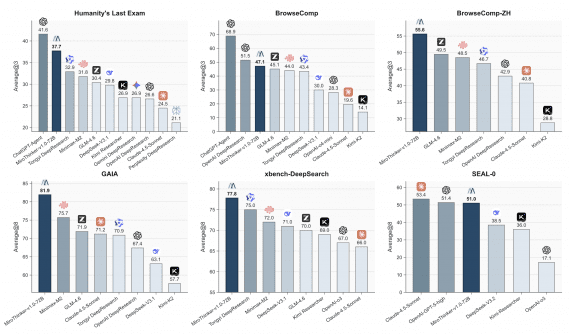
Baichuan-M3: открытая медицинская модель, которая ведёт приём как настоящий врач и обходит GPT-5.2 на тестах
10 февраля 2026

Baichuan-M3: открытая медицинская модель, которая ведёт приём как настоящий врач и обходит GPT-5.2 на тестах
Команда исследователей из китайской компании Baichuan представила Baichuan-M3 — открытую медицинскую языковую модель, которая вместо традиционного режима «вопрос-ответ» ведет полноценный клинический диалог, активно собирая анамнез и принимая взвешенные медицинские решения.…