Сегментация людей на фотографии в сложных условиях
23 августа 2018

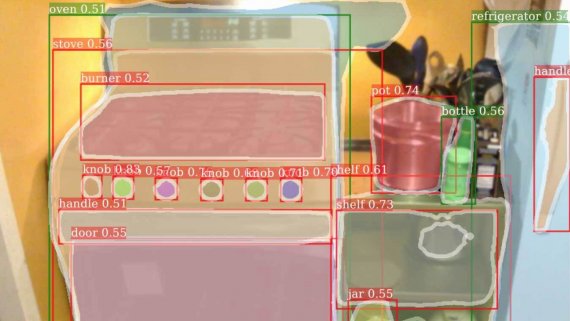
Сегментация людей на фотографии в сложных условиях
Понимание сцены — один из святых граалей сomputer vision. Проводится множество исследований, чтобы достичь абсолютного понимания того, что происходит на картинке. Получение любой дополнительной информации из изображения позволяет продвинуться по…