Понимание сцены — один из святых граалей сomputer vision. Проводится множество исследований, чтобы достичь абсолютного понимания того, что происходит на картинке. Получение любой дополнительной информации из изображения позволяет продвинуться по этой стезе.
Главный акцент в ранних работах был в основном на простых задачах, так как было необходимо достичь некоторого минимального уровня описания и понимания сцены. Однако, в последние годы решаются все более и более сложные проблемы (по крайней мере частично).
Задача и подзадачи
Мы видим значительное продвижение в области получения 3D-информации из плоского изображения. Недавняя работа DeepMind AI продемонстрировала возможности рендеринга трехмерного изображения из двумерного. Решение таких задач расширяет границы человеческого понимания о изображениях.
Исследователи из французского института INRIA и FAIR предложили метод распознавания сложных человеческих поз. В своей работе они представляют технику глубокого обучения, с помощью которой им удалось получить 3х-мерное поверхностное представление человеческого тела из двумерной картинки. Как было упомянуто выше, восприятие сцены и контекста, бьется на небольшие подзадачи:
- детектирование,
- классификация,
- локализация и так далее.
Новый метод оценки позы, описанный в этой работе, рассматривает данные проблемы в качеств предпосылок, и он основывается на решении этих подзадач. Помимо предлагаемой архитектуры для обучения поверхностного представления человеческого тела, авторы создали крупный набор данных, который задает преобразование из картинки в поверхностное представление. Они вручную проаннотировали более 50 тысячи изображение из COCO датасета.
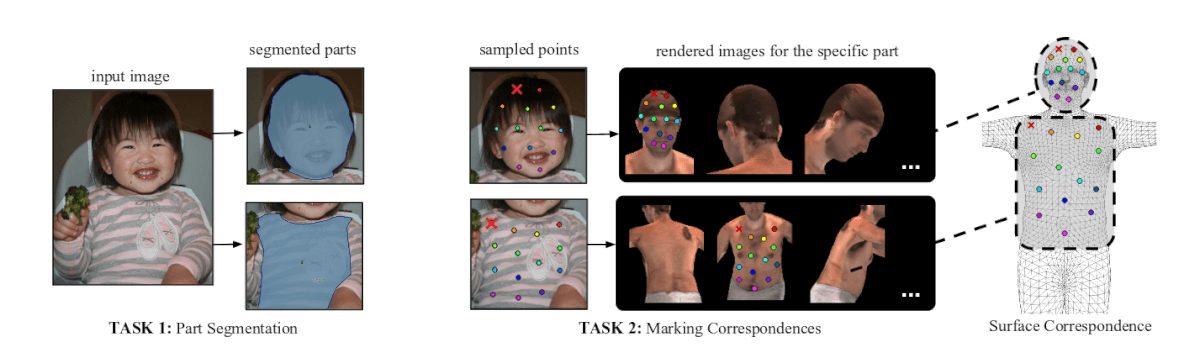
COCO-DensePose датасет
Наличие большого и качественного набора данных очень важно для обучения с учителем. Задачи требуют отличной друг от друга маркировки данных, и очень часто это представляет собой узкое место в процессе моделирования. По этой причине исследователи создали аннотированный набор данных картинку-в-поверхность, взяв 50000 изображений из набора данных COCO. Они ввели новый набор данных под названием COCO-DensePose вместе с оценочными метриками. Новый набор данных создается путем внедрения “умного” конвейера аннотаций, позволяющего максимально уменьшить потребность в человеческих усилиях. Аннотация включает в себя сегментирование изображения, маркировку соответствий с использованием модели SMPL для получения UV-полей.
Архитектура сети
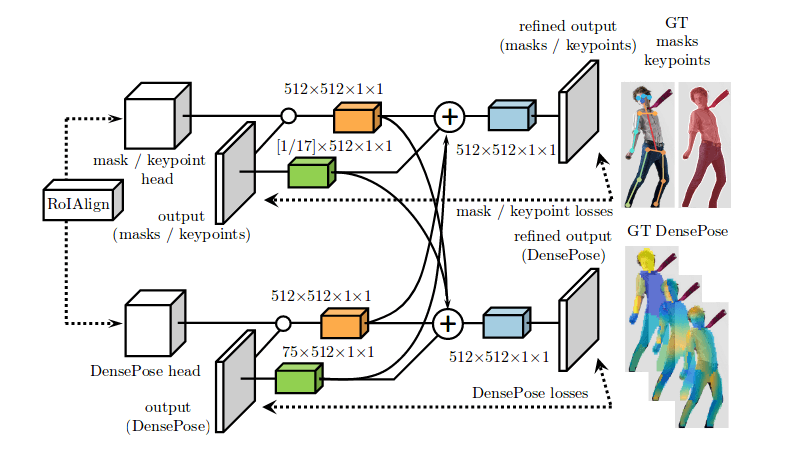
Чтобы решить проблему оценки поверхности человеческого тела из плоских 2D-изображений, авторы представляют проблему, как регрессию координат поверхности тела в пикселе изображения. Вручную аннотируя датасет, они используют архитектуру глубокой нейронной сети — MaskRCNN, которая обучается с учителем. Они объединяют сеть Mask-RCNN с DenseReg (Dense Regression System) для получения соответствий между RGB-изображением и 3D-моделью поверхности тела.
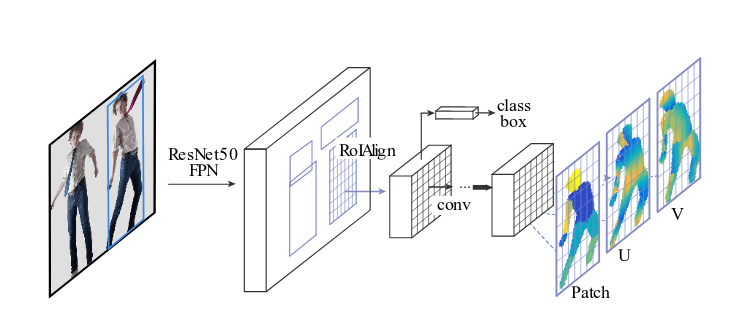
Первая архитектура, которая используется, представляет собой полностью сверточную сеть (FCNN), объединяющую классификацию и регрессию. Первая часть выполняет сегментацию изображения, классифицируя пиксели на один из нескольких классов: фон или конкретная область тела. Таким образом, грубая оценка соответствия координат поверхности передается второй части, которая занимается регрессией для абсолютных значений координат.
В первой части используется пиксельная кросс-энтропийная функция потерь. Вторая, то есть регрессия абсолютных значений координат, определяется как отображение пикселя в точку в двумерной системе координат, заданной параметризацией каждой части (части тела человека). Фактически вторая часть действует, как поправка к классификации первой части. Поэтому регрессионные потери учитываются только в том случае, если пиксель находится в пределах определенной части. Наконец, каждый пиксель отображается в U, V координаты параметризации каждой части тела (в этом случае каждая из 25 определенных частей тела).

Авторы улучшили метод, введя регрессию по областям. Они вводят FCNN поверх ROI-pooling, которая целиком посвящена двум задачам: классификация и формировании базы регрессии, которая определяет, что это за область, и предсказывает координаты области.
Окончательная архитектура состоит из каскада proposing regions-of-interest (ROI), извлекающий особенности области посредством ROI pooling и предоставляющий результаты в соответствующие ветки.
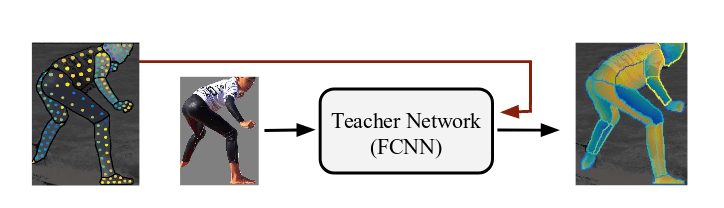
Cross-modal supervision
Дальнейшее улучшение достигается за счет введения cross-modal supervision. Слабый supervion сигнал определяется путем аннотации небольшого подмножества пикселей на каждом обучающем экземпляре. Обучение сети таком образом допустимо, если исключить потери пикселей, которые не имеют соответствия в тренировочном датасете (ground-truth correspondance), при подсчете функции потерь для пикселей.
Однако для дальнейшего усиления supervision сигнала исследователи предлагают кросс-модальный подход с сетью-учителем, которая занимается отображением разреженной аннотированной поверхности на полностью аннотированную поверхность человеческого тела.
Оценка и выводы
Сравнение с другими методами приведено в таблицах ниже. Стоит отметить, что сравнение между этим подходом и предыдущим подходом должно быть тщательно рассмотрено, поскольку новый метод использует новый набор данных, который они создали — DensePose-COCO.
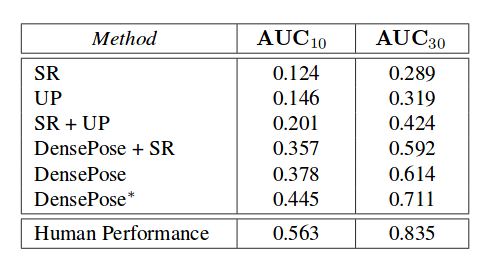
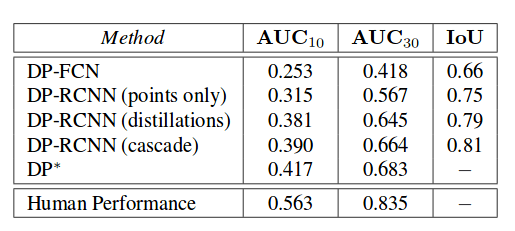
 Качественная и количественная оценки показывают, что метод способен с высокой точностью определять координаты поверхности тела, способен обрабатывать большое количество окклюзий и различные позы. Более того, результаты показывают, что полностью сверточный подход уступает данному новому методу.
Качественная и количественная оценки показывают, что метод способен с высокой точностью определять координаты поверхности тела, способен обрабатывать большое количество окклюзий и различные позы. Более того, результаты показывают, что полностью сверточный подход уступает данному новому методу.