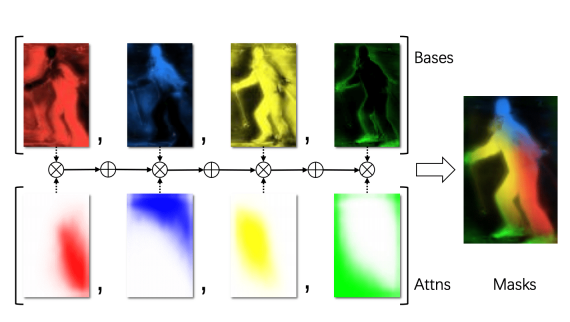
Wan-Move: открытая альтернатива Kling 1.5 Pro для контролируемой генерации движений на видео
13 декабря 2025

Wan-Move: открытая альтернатива Kling 1.5 Pro для контролируемой генерации движений на видео
Команда исследователей из Tongyi Lab (Alibaba Group), Университета Цинхуа и Гонконгского университета представила Wan-Move — новый подход к точному контролю движения в генеративных видео-моделях. В отличие от существующих методов, которые…