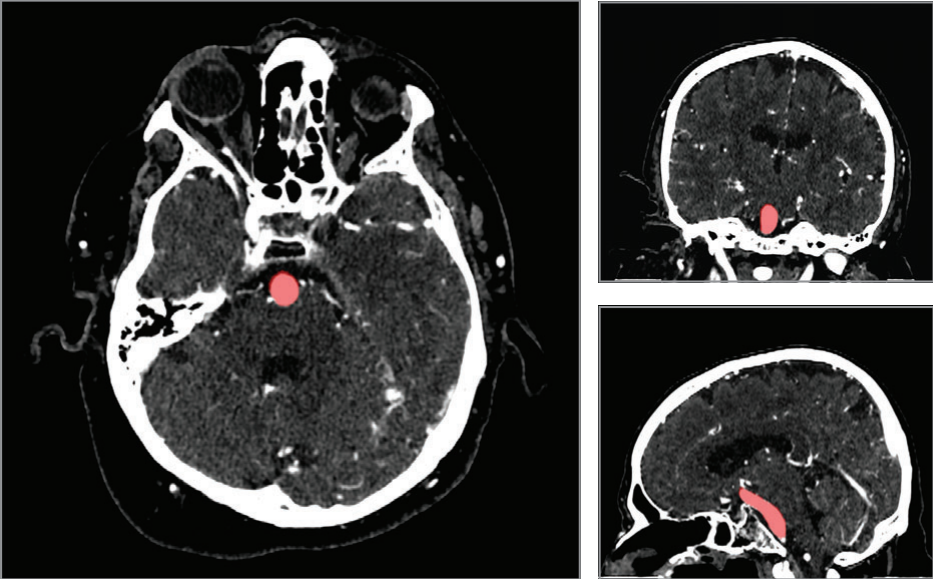
Группа исследователей машинного обучения, возглавляемая Эндрю Ыном, разработала модель, которая диагностирует внутричерепные аневризмы на снимках компьютерной томографической ангиографии (КТА) головы. Датасет содержал 818 обследований от 662 уникальных пациентов с 328 обследованиями КТА (40,1%), содержащих по крайней мере 1 внутричерепную аневризму и 490 обследований (59,9%) без внутричерепных аневризм.

Проблема
Диагностика неразорвавшихся аневризм является критически важной клинической задачей: внутричерепные аневризмы встречаются у 1-3% населения и составляют более 80% нетравматических субарахноидальных кровоизлияний, угрожающих жизни. Компьютерная томографическая ангиография (КТА) — это первичная, малоинвазивная методика визуализации, используемая в настоящее время для диагностики, наблюдения и предоперационного планирования внутричерепных аневризм. Но интерпретация требует много времени даже для обученных по специальностям нейрорадиологов. Низкий уровень соглашения между различными экспертами создает дополнительную проблему для надежной диагностики.
Учитывая потенциальный катастрофический исход пропущенной аневризмы с риском разрыва, крайне желателен инструмент автоматического обнаружения, который надежно обнаруживает и повышает эффективность работы медицинских сотрудников. Разрыв аневризмы приводит к летальному исходу у 40% пациентов и приводит к необратимой неврологической инвалидности у двух третей выживших, поэтому точное и своевременное обнаружение имеет первостепенное значение.
Архитектура модели
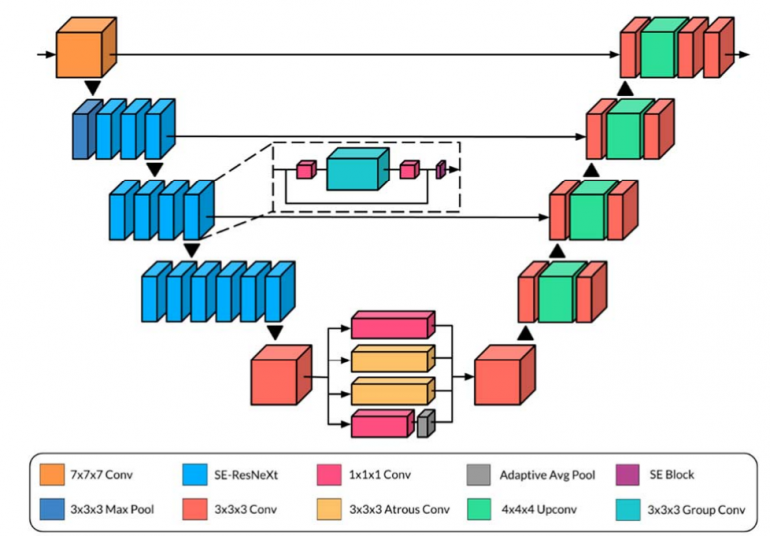
В этом исследовании была разработана 3D-CNN под названием HeadXNet для сегментации внутричерепных аневризм с КТ. HeadXNet — это CNN со структурой энкодер-декодер, где энкодер служит для кодирования полного объема информации с изображения в более низкую размерность, а декодер расширяет это кодирование до объема сегментации с полным разрешением. Энкодер состоит из 50-слойной SE-ResNeXt сети, и декодер представляет собой последовательность из обратных сверток 3 × 3. Аналогично UNet, остаточные соединения используются в 3 слоях энкодера для передачи выходов непосредственно в декодер. Энкодер был предварительно обучен на датасете Kinetics-600, большой коллекции видео на YouTube, размеченной человеческими действиями; после предварительной подготовки энкодера, последние 3 сверточных блока и выходной слой softmax на 600 выходов были удалены. На их место были добавлены слой spatial pyramid pooling и декодер.
Результаты
Без аугментации, медицинские специалисты достигли чувствительности микросреднего уровня 0,831, специфичности 0,960 и точности 0,893. С аугментацией, специалисты достигли чувствительности микроусреднего уровня 0,890, специфичности 0,975 и точности 0,932. Базовая модель имела чувствительность 0,949, специфичность 0,661 и точность 0,809.





