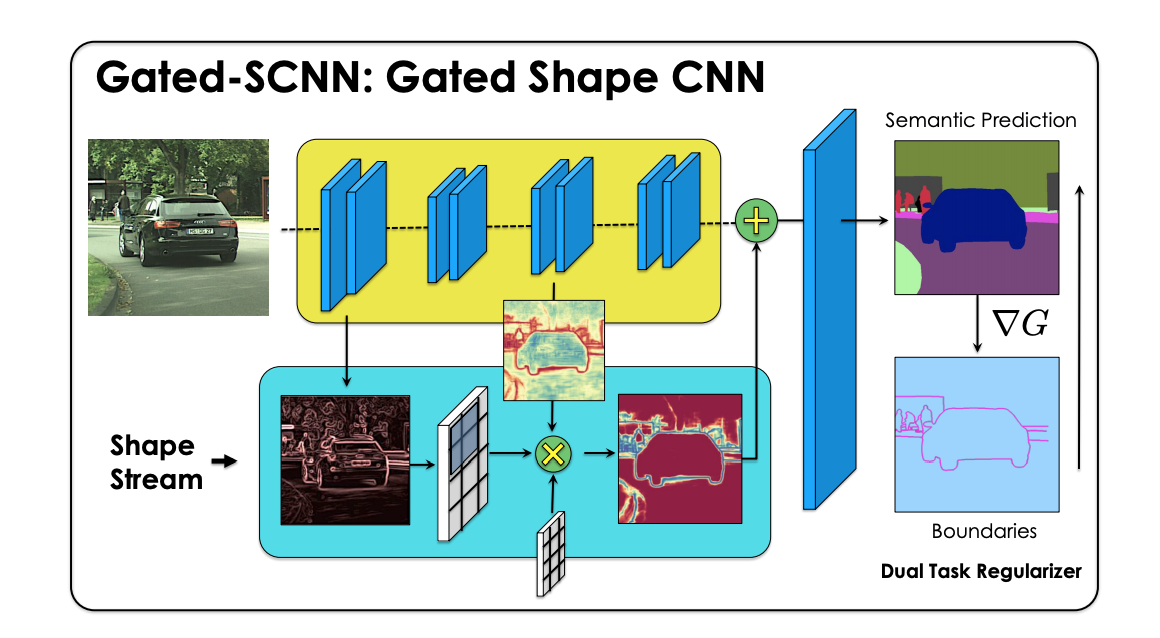
Gated-SCNN — это двухпоточная сверточная нейросеть для семантической сегментации изображений. GSCNN обходит state-of-the-art архитектуры на 2-4% на задаче Cityscapes. Архитектура была разработана исследователями из NVIDIA.
Текущие state-of-the-art методы для сегментации изображений создают плотное представление изображения. В таких представлениях одновременно хранится информация о цвете форме и текстуре объекта, и они обрабатываются в глубокой сверточной нейросети. Это подход неоптимальный, потому что представления хранят в себе слишком разнообразную информацию об объекте. В GSCNN обработка изображения делится в два параллельных потока: информация о форме объекта кодируется в отдельном потоке.
Суть архитектуры в том гейтах нового типа, которые объединяют промежуточные слои двух потоков. Эксперименты показывают, что такие особенности структуры позволяют выдавать более точные предсказания о границах объекта. Более тонкие и маленькие по размеру объекты распознаются лучше.
Что внутри нейросети
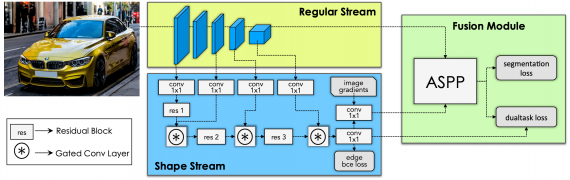
Архитектура состоит из двух потоков:
- Обычный поток (regular stream), который представляет собой любую модель для семантической сегментации;
- Поток кодирования формы объекта (shape stream), в котором через набор residual blocks, Gated Convolutional Layers (GCL) и обучение с учителем обрабатывается информация о форме объекта
Совместная модель затем комбинирует информацию из двух потоков с помощью модуля Atrous Spatial Pyramid Pooling (ASPP). Чтобы границы объекта были точнее, исследователи вводят регуляризатор Dual Task Regularizer
Оценка работы модели
В качестве базовой модели исследователи брали предобученную нейросеть DeepLabV3+. Это state-of-the-art архитектура для задачи семантической сегментации. Внутри DeepLabV3+ используются ResNet-50, ResNet-101 и WideResNet как базовые модели.
Модели обучаются на датасете Cityscapes. Все эксперименты проводятся на том же наборе данных. Датасет состоит из изображений 27 городов. В обучающей выборке — 2975 изображений, в валидационной — 500, а в тестовой — 1525.

Для сравнения, на изображении с большим количеством людей базовая модель распознает столбы как часть толпы. В то время как GSCNN распознает объекты корректно.









