SelFlow — это нейросетевая модель, которая предсказывает последовательность передвижений объекта на видеозаписи. Нейросеть обучается как с учителем, так и без. По точности предсказаний SelFlow обходит state-of-the-art алгоритмы на 4-х задачах.
Оптический поток — это последовательность передвижений объектов на видеозаписи. Предложенный метод борется с проблемой предсказания для заблокированных пикселей (occlusion). С помощью простой сверточной нейросети исследователи используют информацию с нескольких кадров, чтобы предсказание оптического потока было более гладкое.
Предсказание оптического потока — это основная задача для части систем компьютерного зрения. Несмотря на предыдущие исследования, существующие подходы плохо справляются с ситуацией, когда часть пикселей затерты. Стандартные алгоритмы минимизируют энергетическую функцию, чтобы визуально схожие пиксели ассоциировались друг с другом. Это необходимо для распространения предсказаний модели с не затертых пикселей на затертые. Недостаток такого подхода — временные затраты на обучение модели. Как альтернатива есть CNN, которые в end-to-end формате обучаются предсказывать оптический поток на размеченных данных. Недостаток полностью supervised подхода — ресурсы, которые тратятся на разметку данных для обучения. Исследователи предлагают SelFlow как оптимальную модель, не требующую значительных временных затрат и затрат на разметку.
Как это работает изнутри
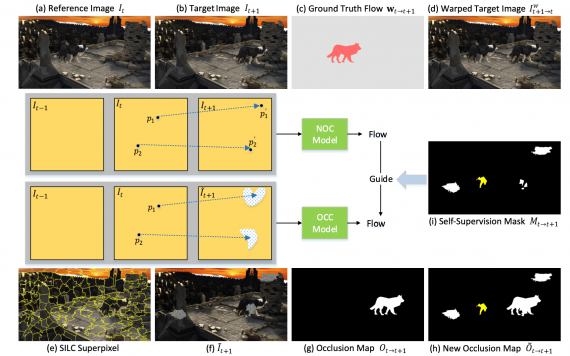
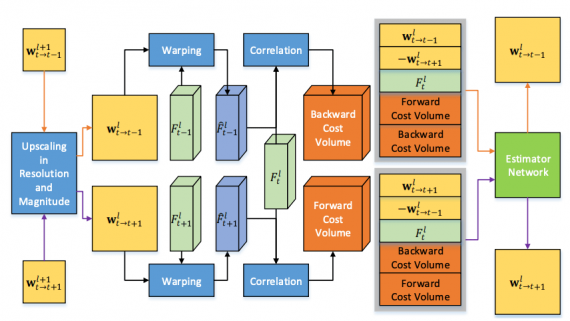
В SelFlow обучаются последовательно две сверточные нейросети с одинаковой архитектурой: NOC и OCC. Первая обучается предсказывать оптический поток для всех пикселей. Предсказания из первой модели используются для обучения OCC, которая предсказывает оптический поток для затертых пикселей. Нейросеть основывается на PWC-Net архитектуре.
Пайплайн работы модели состоит из следующих шагов:
- Сначала обучается NOC модель с стандартной фотометрической функцией потерь. Функция потерь измеряет разницу между входным изображением (a) и целевым изображением (d) и опирается на карту затертых пикселей (g);
- Затем искажаются случайно выбранные суперпиксели из целевого изображения (b);
- В итоге предсказания оптического потока из NOC модели используются для обучения OCC модели
Self-supervised подход выучивает оптический поток для статичных и динамичных сцен.
Сравнение с state-of-the-art
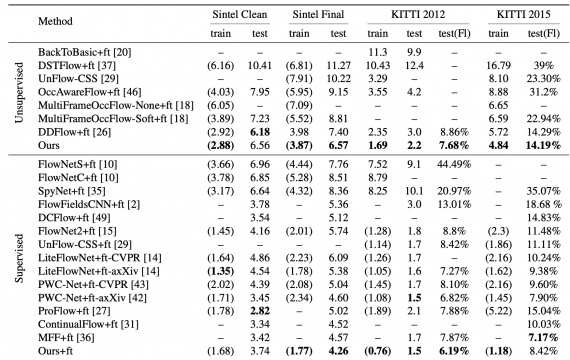
Исследователи сравнили работу модели с предыдущими подходами, которые обучаются с учителем и без. Метрикой была точность. Подходы сравнивались на четырех задачах: MPI Sintel, KITTI 2012 and 2015.