COSNet — это нейросетевая модель для unsupervised сегментации объектов на видео. Исследователи используют механизм глобального со-внимания, чтобы вычленить корреляцию между кадрами видеозаписи. COSNet обходит текущие state-of-the-art подходы в задаче unsupervised сегментации объектов на видеозаписи. Предыдущие подходы фокусировались на том, чтобы выучивать представления объектов переднего плана по движениям на коротких промежутках времени.
Слои со-внимания в COSNet захватывают глобальные корреляции и контекст сцены. Это возможно благодаря тому, что со-внимание считается совместно и объединяется в единое пространство признаков. COSNet обучалась на парах видеокадров, что позволило естественно расширить обучающую выборку. На этапе сегментации модель со-внимания кодирует необходимую информацию через обработку нескольких кадров одновременно. Такой способ обучения позволяет модели лучше запоминать часто встречающиеся объекты на переднем плане. Исследователи предлагают унифицированный end-to-end фреймворк с разными вариациями со-внимания.
Концепт со-внимания
Получая на вход кадр, механизм со-внимания заимствует информацию из нескольких реферальных кадров. Это необходимо, чтобы более точно определить объекты переднего плана.

Архитектура нейросети
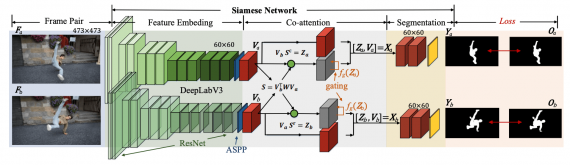
COSNet основывается на архитектуре сиамской нейросети. Внутри сиамской нейросети заложен модуль со-внимания. Со-внимание кодирует корреляции между кадрами. Это позволяет модели аттендиться (фокусировать внимание) на связных частях кадра, чтобы затем определять объекты на переднем фоне.
На вход модели поступает пара кадров, которые отправляют в модуль извлечения признаков. Затем механизм со-внимания считает внимание для двух представлений кадров. Выход модуля со-внимания конткатенируется, чтобы в итоге выдать сегментированные объекты.

Тестирование модели
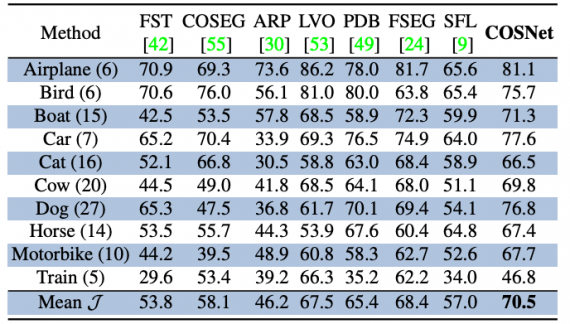
Исследователи проверили модель на трех датасетах для unsupervised видео сегментации: DAVIS16, FBMS и YoutubeObjects. Ниже можно сравнить результаты COSNet и альтернативных подходов на датасете YoutubeObjects. В среднем COSNet более точно сегментирует объекты разных классов по сравнению с остальными подходами.