Scene understanding is one of the holy grails of computer vision. A lot of research has been done towards the ultimate goal of understanding a scene given an image. Inferring any kind of additional information helps to forge ahead the human understanding of images. Throughout the recent past, researchers have focused mostly on simpler tasks in order to provide some (satisfactory) level of scene description and understanding. However, in the past few years more and more complex problems have been tackled and solved (to some extent at least) starting from object detection and classification, segmentation, object localization, scene classification all the way up to contextual reasoning.
We have seen remarkable advancement in inferring 3D information out of 2D data. Recent work from Google DeepMind AI showed that it is able to render 3D scene out of flat 2D images. Addressing this kind of problems pushes the boundaries of human understanding in images even more. Researchers from the French Institute for Research in Computer Science (INRIA) and FAIR have proposed a method for dense human pose estimation from images. In their paper, they propose a Deep Learning method that infers a 3D, surface-based representation of the human body out of a single flat image. As I mentioned before, scene or context understanding in images has been addressed by addressing smaller sub-problems such as object detection, classification localization etc. The novel dense pose estimation method proposed in this work involves these problems as prerequisites and it builds gradually on top of their outcome.
Besides the proposed architecture for learning a surface-based representation of the human body, the authors create a large-scale ground-truth dataset with image-to-surface correspondences manually annotated using 50 thousand images from the COCO Dataset.
Dataset
Having a rich, high-quality labeled dataset of sufficient size is crucial in supervised learning. Different problems require different labeling of the data and very often this represents a bottleneck in the modeling process. For this reason, the researchers created an annotated dataset with image-to-surface correspondences by taking the 50K images from the COCO Dataset. They introduce a new dataset called COCO-DensePose along with evaluation metrics as another contribution. The new dataset is created by introducing a smart annotation pipeline enabling to decrease the need for human effort as much as possible. The annotation includes segmenting the image, marking correspondences using SMPL model to obtain UV fields.
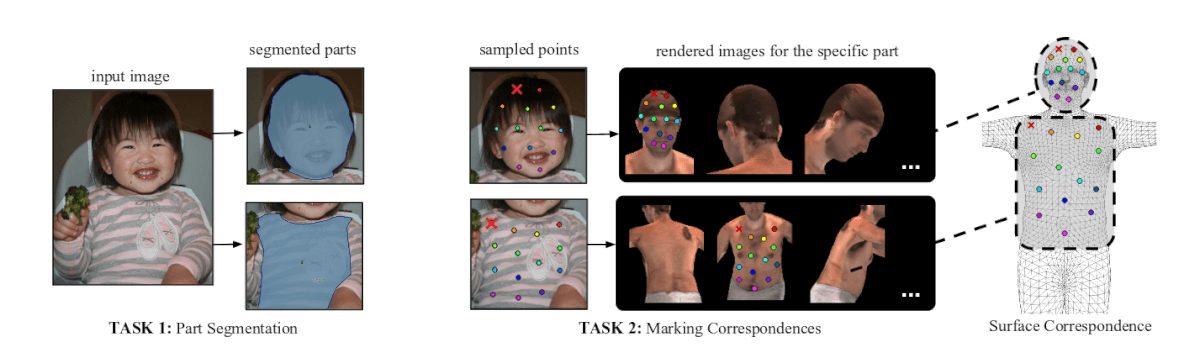
Method
To address the problem of human body surface estimation out of flat 2D images, the authors propose mapping the problem as regressing body surface coordinates at an image pixel. By manually annotating a dataset, they exploit a deep neural network architecture — Mask-RCNN trained in a completely supervised manner. They combine the Mask-RCNN network within a DenseReg (Dense Regression System) to obtain the correspondences between the RGB image and a 3D body surface model.
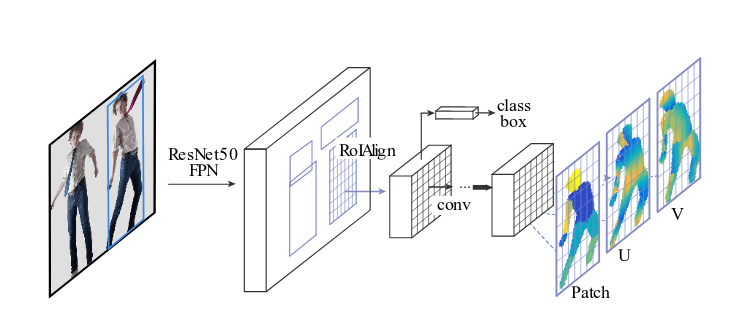
The first and simpler architecture that is employed is a fully convolutional network (FCN), combining classification and regression. The first part is doing segmentation of the image by classifying the pixels to one of the several classes: background or a specific region of the body. In this way, a coarse estimate of the surface coordinate correspondences is given to the second part which regresses the exact coordinates. The first part is trained using pixel-wise cross-entropy loss. The second part i.e. regression of the exact coordinates is defined as mapping each pixel to a point in a 2D coordinate system given by the parametrization of each piece (part of a human body). In fact, the second part acts as a correction to the classification of the first part. Therefore, the regression loss is taken into account only if the pixel is within the specific part. Finally, each pixel is mapped to U, V coordinates of the parametrization of each body part (in this case each of the 25 defined body parts).

The authors improve the method by introducing region-based regression. They introduce a fully convolutional network (as discussed above) on top of ROI-pooling that is entirely devoted to the two tasks, generating a classification and a regression head that provide the part assignment and part coordinate predictions.
The final architecture consists of a cascade of proposing regions-of-interest (ROI), extracting region-adapted features through ROI pooling and providing the results to a region-specific branch.
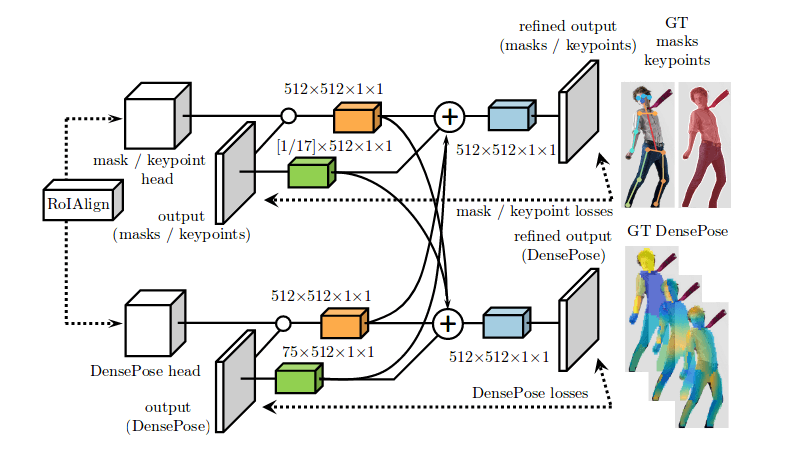
Cross-modal supervision
The method is further improved by introducing a cross-modal supervision. A weak supervision signal is defined by annotating over a defined small subset of image pixels at each training sample. Training a network architecture in this way is still possible by not including the loss of the pixels that do not have ground-truth correspondence in the pixel-wise loss calculation.
However, to further amplify the supervision signal they propose a cross-modal supervision approach with a teacher network that learns the mapping from a sparse annotated surface to a fully annotated human body surface. They argue that this kind of “in-painting” of the supervision signal is, in fact, efficient and improves the overall results.
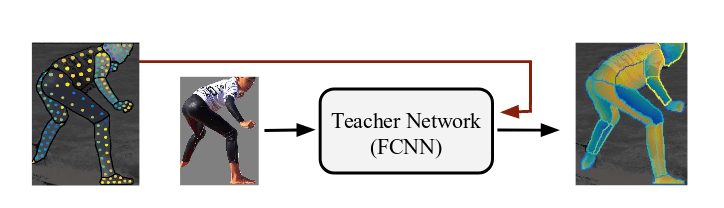
Evaluation and conclusions
The comparison with other methods is given in the tables below. It is worth to note that the comparison between this approach and the previous approach has to be taken carefully since the new method makes use of the new dataset that they created — DensePose-COCO.
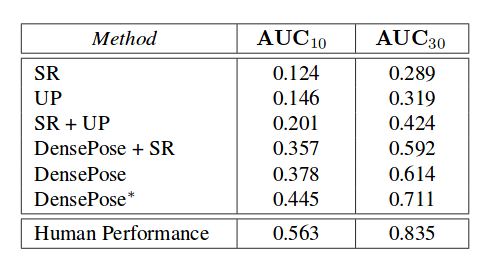
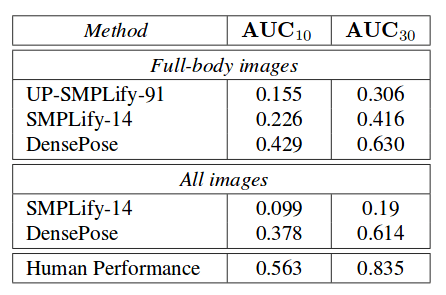
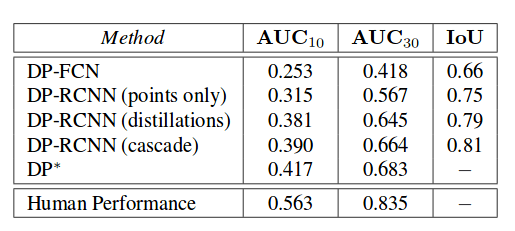

The qualitative and quantitative evaluation show that the method is able to infer body surface coordinates with high accuracy, it is able to handle large amounts of occlusion, pose variation and scale. Moreover, the results show that a fully convolutional approach underperforms compared with the newly proposed ROI-based method trained in a cross-modal supervision manner.