Realistic garment reconstruction is notoriously a complex problem and its importance is undeniable in many research work and applications, such as accurate body shape and pose estimation in the wild (i.e., from observations of clothed humans), realistic AR/VR experience, movies, video games, virtual try-on, etc. For the past decades, physics-based simulations have been setting the standard in movie and video game industries, even though they require hours of labor by experts.
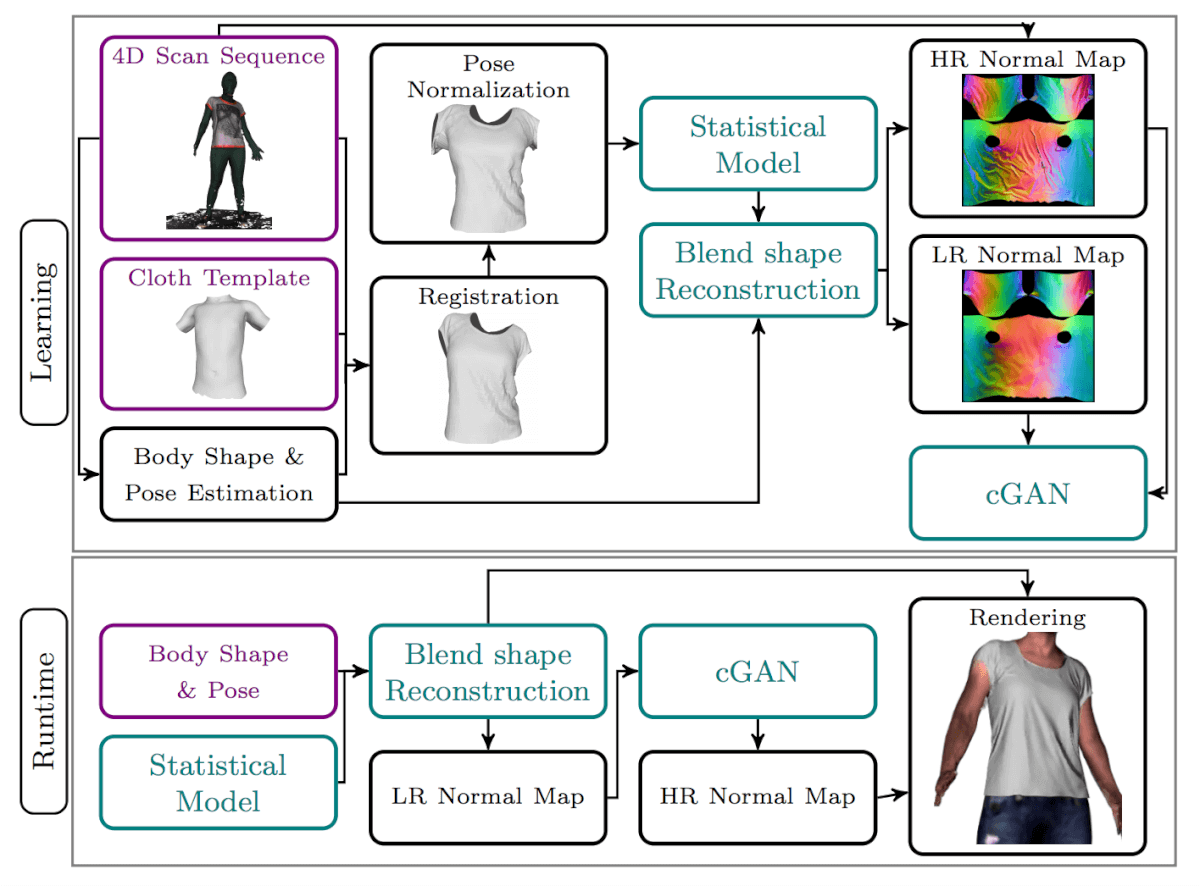
FAIR present a novel approach called Deep wrinkles to generate accurate and realistic clothing deformation from real data capture. It consists of two complementary modules:
- A statistical model is learned from 3D scans of clothed people in motion, from which clothing templates are precisely non-rigidly aligned.
- Fine geometric details are added to normal maps generated using a conditional adversarial network whose architecture is designed to enforce realism and temporal consistency.
The goal is to recover all observable geometric details. Assuming the finest details are captured at sensor image pixel resolution and are reconstructed in 3D, all existing geometric details can then be encoded in a normal map of the 3D scan surface at the lower resolution as shown in figure below.

Cloth deformation is model by learning a linear subspace model that factors out body pose and shape. However, our model is learned from real data.
By the way, Neurohive is creating new app for business photos based on neural network. We are going to release it in September.
The strategy ensures deformations are represented compactly and with high realism. First, we compute robust template-based non-rigid registrations from a 4D scan sequence, then a clothing deformation statistical model is derived and finally, a regression model is learned to pose retargeting.
Data Preparation
Data capture: For each type of clothing, 4D scan sequences are captured at 60 fps (e.g., 10.8k frames for 3 min) of a subject in motion, and dressed in a full-body suit with one piece of clothing with colored boundaries on top. Each frame consists of a 3D surface mesh with around 200k vertices yielding very detailed folds on the surface but partially corrupted by holes and noise. In addition, capturing only one garment prevents occlusions where clothing normally overlaps (e.g., waistbands) and items of clothing can be freely combined with each other.
Registration. The template of clothing T is defined by choosing a subset of the human template with consistent topology. T should contain enough vertices to model deformations (e.g., 5k vertices for a T-shirt). The clothing template is then registered to the 4D scan sequence using a variant of
non-rigid ICP based on grid deformation.
Statistical model
The statistical model is computed using linear subspace decomposition by PCA. Poses of all n registered meshes are factored out from the model by pose-normalization using inverse skinning. Each registration Ri can be represented by a mean shape M and vertex offsets oi, such that Ri = M+ oi, where the mean shape M belongs to R3*v is obtained by averaging vertex positions. Finally, each Ri can be compactly represented by a linear blend shape function
B,
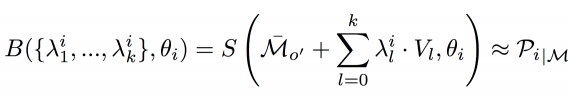
Pose-to-shape prediction
Predictive model f is learned that that takes as inputs joint poses and outputs a set of k shape parameters (A). This allows powerful applications where deformations are induced by the pose. To take into account deformation dynamics that occur during human motion, the model is also trained with pose velocity, acceleration, and shape parameter history.
Architecture
The goal is to recover all observable geometric details. Assuming the nest details are captured at sensor image pixel resolution and are reconstructed in 3D all existing geometric details can then be encoded in a normal map of the 3D scan surface at a lower resolution. To automatically add fine details on the fly to reconstructed clothing, the generative adversarial network is proposed to leverage normal maps.
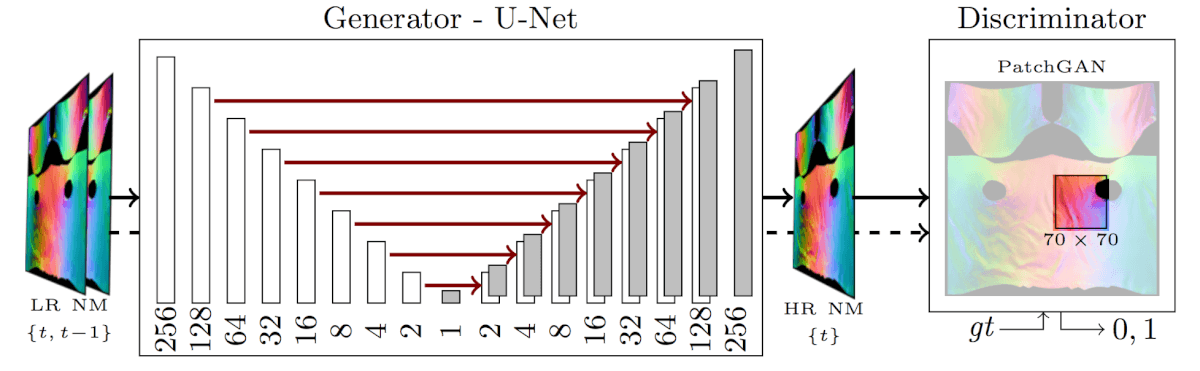
The proposed network is based on a conditional Generative Adversarial Network (cGAN) inspired by image transfer. A convolution batchnorm-ReLu structure and a U-Net is used in the generative network since it transferred all the information across the network layers and the overall structure of the image to be preserved. Temporal consistency is achieved by extending the L1 network loss term. For compelling animations, it is not only important that each frame looks realistic, but also no sudden jumps in the rendering should occur. To ensure a smooth transition between consecutively generated images across time, we introduce an additional loss L(loss) to the GAN objective that penalizes discrepancies between generated images at t and expected images (from training dataset) at t – 1:
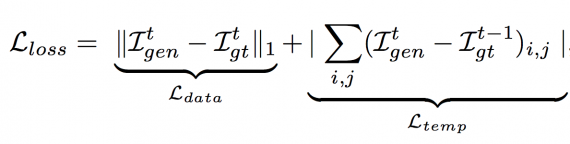
where L(data) helps to generate images near to ground truth in an L1 sense (for less blurring). The temporal consistency term L(temp) is meant to capture global fold movements over the surface.
The cGAN network is trained on a dataset of 9213 consecutive frames. The first 8000 images compose the training data set, the next 1000 images the test data set and the remaining 213 images the validation set. Test and validation sets contain poses and movements not seen in the training set. The U-Net auto-encoder is constructed with 2 x 8 layers, and 64 filters in each of the first convolutional layers. The discriminator uses patches of size 70 x 70. L(data) weight is set to 100, L(temp) weight is 50, while GAN weight is 1. The images have a resolution of 256 x 256, although our early experiments also showed promising results on 512 x 512.
Result
DeepWrinkles is an entirely data-driven framework to capture and reconstruct clothing in motion out from 4D scan sequences. The evaluations show that high-frequency details can be added to low-resolution normal maps using a conditional adversarial neural network. The temporal loss is also introduced to the GAN objective that preserves geometric consistency across time, and show qualitative and quantitative evaluations on different datasets.









