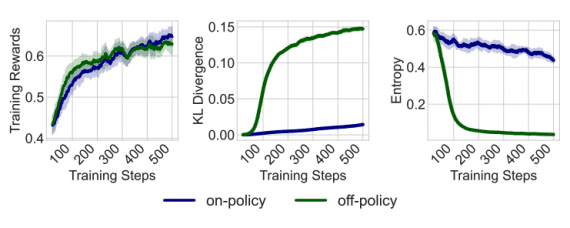
Microsoft has introduced the VASA-1 platform, which transforms a person’s image and audio recording with speech into a video with synchronized lip and head movements. The algorithm operates in real-time at a speed of 40 frames per second.
In the long run, Microsoft sees VASA-1 as a step towards creating realistic avatars that mimic human movements and emotions. According to the company, this could help improve educational levels, enhance accessibility for people with communication difficulties, and offer friendly or therapeutic support to those in need.
The platform includes a head movement generation model that operates in the hidden space of the face. The generated videos convey a full range of emotions, as well as features of various facial expressions and natural head movements. The technology allows users to control the generation process, including adjusting the sequence of movements, gaze direction, distance to the head, and emotions using numerical parameters. Additionally, the platform enables working with content that was not included in the training dataset, such as artistic photos, singing audio recordings, and non-English speech.
VASA-1 generates videos at a resolution of 512 x 512 at a speed of 45 frames per second in batch processing standalone mode and can support speeds of up to 40 frames per second in live streaming mode. Microsoft claims that the algorithm outperforms other methods in this area when tested through extensive experiments, including comparisons based on a completely new set of metrics. The platform works with two types of audio recordings: regular speech and singing.
Considering the risk of creating deepfakes using the technology, Microsoft is not releasing VASA-1 as a product or API at this time.