Human pose estimation is a fundamental problem in Computer Vision. Deriving a 3D Human pose out of single RGB image is needed in many real-world application scenarios, especially within the fields of autonomous driving, virtual reality, human-computer interaction, and video surveillance.
However, the task of recovering a 3D human pose from a single 2D image represents a big challenge, mostly due to the inherent geometric ambiguities in 2D images. Different viewpoints, occlusions, and diverse appearances introduce additional difficulties in solving this task.
In the past few years, the problem of 3D human pose estimation has been tackled using convolutional deep neural networks. Being able to learn high-dimensional, non-linear mappings taking into account the spatial nature of the data, convolutional neural networks have been used to directly regress 3D human poses from 2D features or 2D pose predictions. Although successful, these methods rely on supervised learning techniques and are often not able to generalize well due to the insufficient amounts of training data.
On the other hand, obtaining large enough amount of labeled training data of 3D human poses is a cumbersome and very time-consuming process.
Researchers from Sun Yat-sen University have proposed a novel method for 3D human pose estimation out of 2D images relying on a self-supervised correction mechanism. The method can effectively learn structures of human poses from abundant images in a self-supervised manner.
State-of-the-art Idea
The idea behind the proposed method is to employ a specific learning scheme that involves two dual learning tasks: 2D-to-3D pose transformation and 3D-to-2D pose projection. In this way, exploiting the learning a two-way mapping from 3D to 2D and vice versa, the method can do accurate 3D human pose estimation without any supervision signal.
The method is also exploiting the sequential nature of frames data in videos, to do spatiotemporal modeling and regress 3D poses by transforming 2D pose representations in a temporal context. To put it simply, the method is additionally learning long-term temporal dependencies between 3D poses in different (subsequent) frames to refine each 3D pose prediction in each of the frames.
Method
Researchers propose the so-called 3D human pose machine to resolve 3D pose sequence generation for monocular frames using the proposed model and self-supervised correction mechanism.
The method first extracts 2D pose representations and estimates 2D pose for each frame using the first subnetwork – 2D Pose Representation Network (as noted in the architecture below).
The architecture consists of two large modules: the first one – 2D-to-3D pose transformer module for transforming 2D pose features (given as the output from the first subnetwork) from 2D to the 3D domain and the second one – the 3D-to-2D pose projector module that refines obtained 3D pose prediction using the proposed self-supervised correction mechanism.
The unified network architecture consisting of the described modules enables optimization in an end-to-end manner.
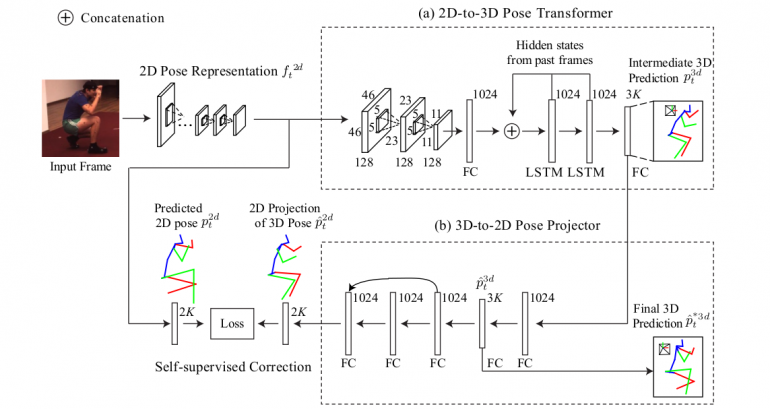
2D Pose Sub-network
The 2D Pose sub-network merely is an encoder network that should learn a compact representation of the pose information in each frame. This network consisting of convolutional and pooling layers takes an image as input and outputs feature maps along with the predicted 2D pose vectors.

Module 1: 2D-to-3D Pose Transformer
The first module – the pose transformer module is used to adapt the 2D pose-aware features extracted by the pose sub-network. This module consists of two convolutional layers, one fully-connected layer and two LSTM layers that are used to learn temporal motion patterns from the encoded poses. The output layer is a final fully-connected layer that outputs the predicted locations of K common points of the human body.
Module 2: 3D-to-2D Projector Module
The second module – the projector module consists of six fully-connected layers. The first two layers have an output which defines the final 3D pose prediction which is obtained as regression of the output of the first module. The other layers along with the first two define a projection mapping function that gives the 2D projection of the regressed 3D pose. This projection is then used by the self-supervised correction mechanism to define a loss function given as the distance between this projection and the predicted 2D pose from the 2D Pose sub-network (directly from the frame). This closed loop defines the unified closed-loop architecture that enables learning in a self-supervised manner. The whole architecture is depicted in the picture.
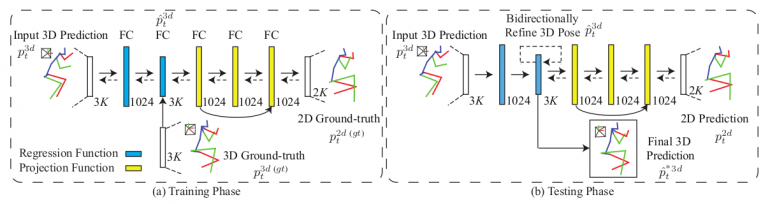
(b) testing phase.
Results
The researchers conducted extensive evaluations on two publicly available benchmark datasets: Human 3.6 M and HumanEva-I.
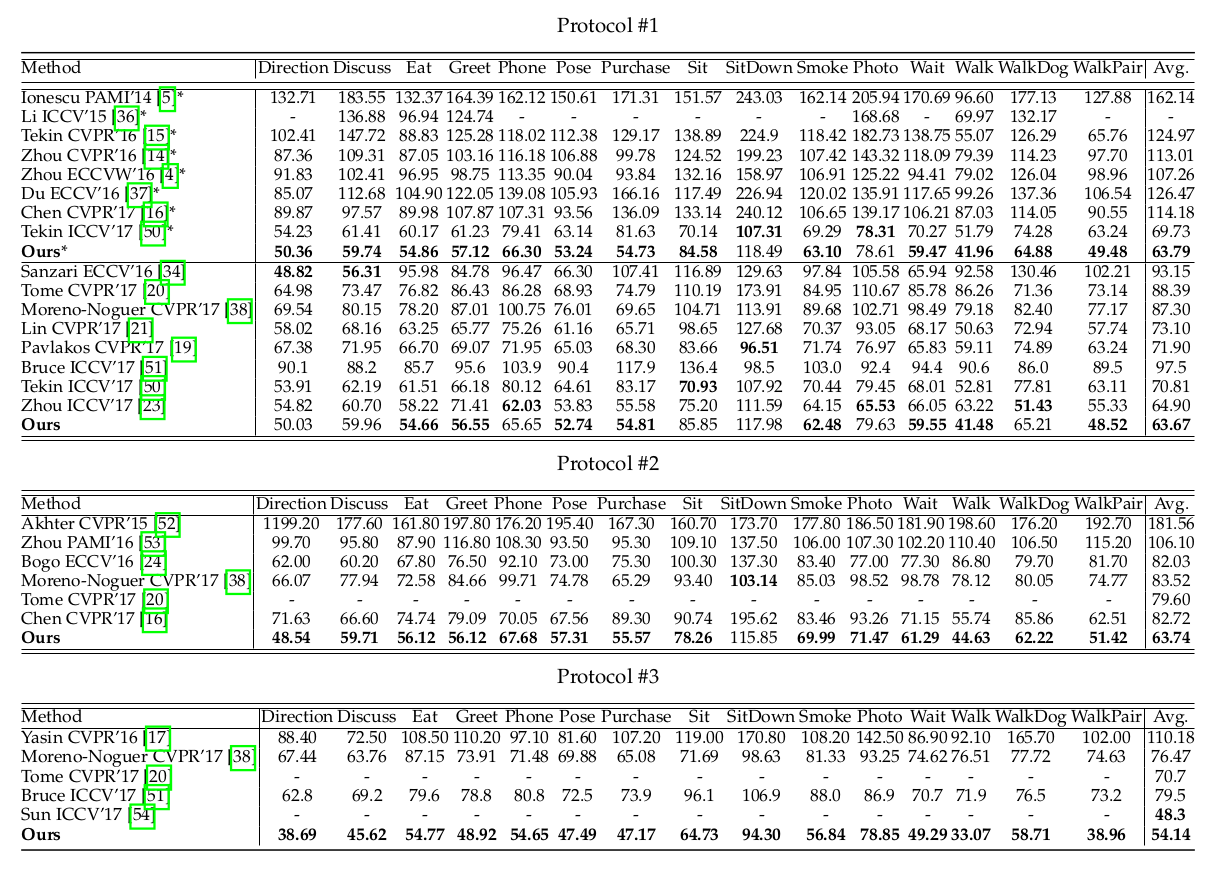
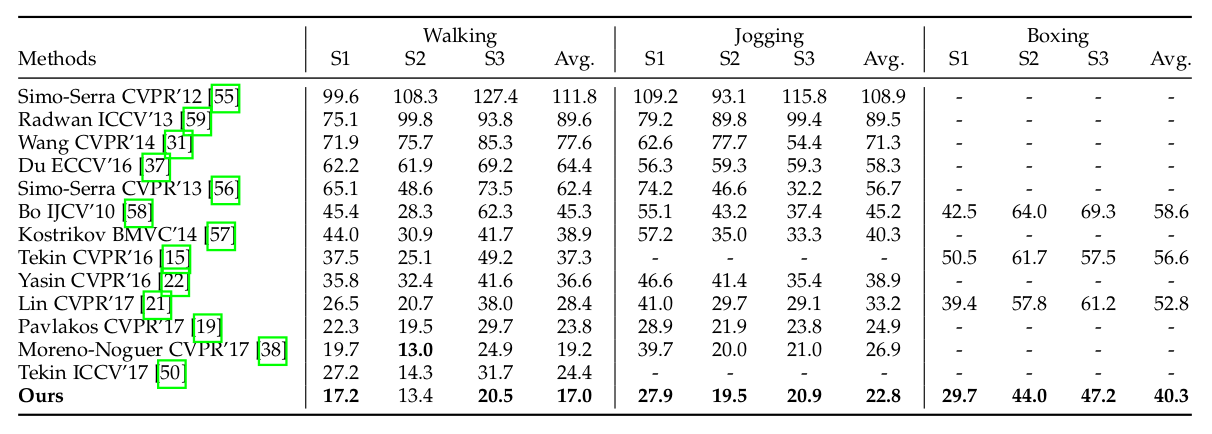
Quantitative evaluation of both datasets shows that the proposed method achieves superior results as compared to existing methods. The assessment was broken down by pose category to provide even more detailed comparison. The tables below show the comparison scores on the two benchmark datasets.
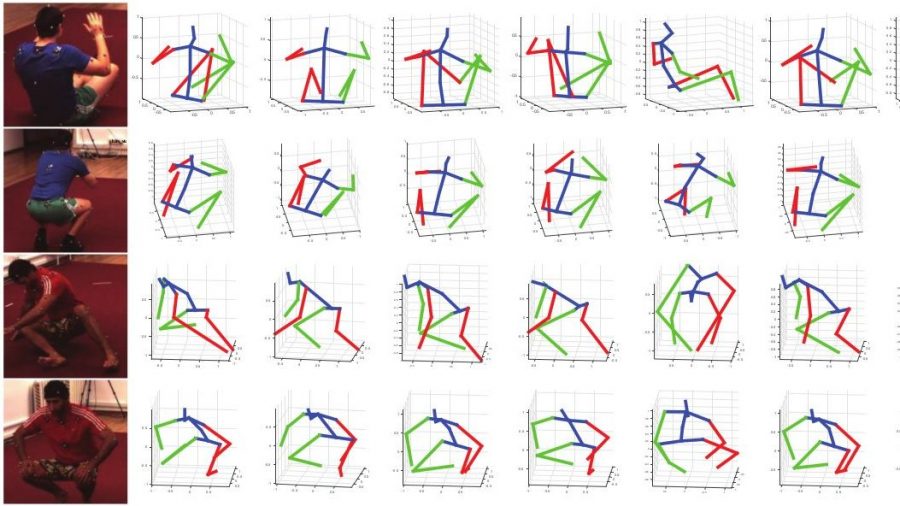
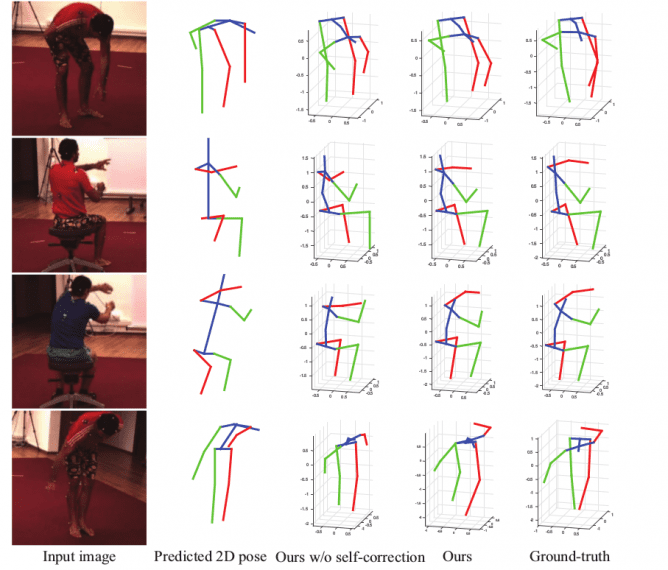
Additionally, researchers performed qualitative evaluation comparing the obtained results from the novel method against existing methods visually. They mention that their approach “achieves considerably more accurate estimations.”
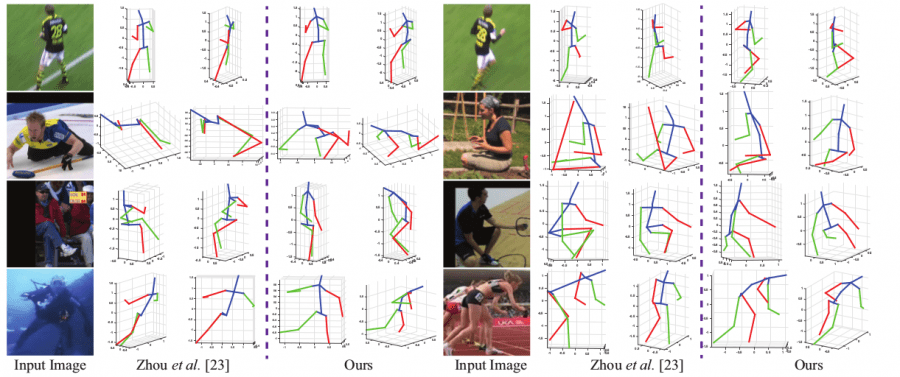
Bottom Line
The presented method is a significant contribution in the area of human pose estimation. Researchers were able to show the potential of self-supervised learning methods towards solving a non-trivial task in computer vision. The evaluations show that the proposed method can bridge the domain gap between 3D and 2D human poses and learn to derive 3D poses without additional 3D annotations. The code of the project was open-sourced and can be found at the following link.





[…] 3D pose estimation […]