
NVIDIA released the StyleGAN code, the GAN for faces generation that has never existed which is the state-of-the-art method in terms of interpolation capabilities and disentanglement power.
On the 18th of December we wrote about the announcement of StyleGAN, but at that time the implementation was not released by NVIDIA. Now that the code is open-sourced and available on Github we go back to the StyleGAN paper, to further analyze the method and the results.
State-of-the-Art Idea
The improvement of Generative Adversarial Networks is very often measured by the resolution and quality of the generated images. However, following the progress with this objective in mind, Generator networks are still a black box that is difficult to understand.
Besides some individual efforts to try to understand the internal structure of Generative Adversarial Networks, most researchers are still optimizing the objective of better image quality only using GANs as black boxes. The properties of the latent space and the representations are still poorly understood.
Recent work has tried to dissect Generative Adversarial Networks and study the internal representations of GANs.
The new method proposed by NVIDIA is redesigning the generator architecture so that it exposes new ways to control the image generation process. In fact, the StyleGAN generator starts from a learned constant input and adjusts the “style” of the image at each convolution layer based on the latent code. In this way, the generator is able to directly control the strength of image features at different scales. The goal of this architecture is to provide a disentanglement of the latent factors of variation and by doing so to be able to increase the level of control.
StyleGAN architecture
To put in more simple terms, the StyleGAN architecture is trying to separate high-level attributes (pose, person’s identity) from stochastic variation factors such as hair, freckles etc. When I mentioned before “the generator architecture” I meant the generator network (yes only the generator part, not the whole GAN network). And this is very important to note since researchers from NVIDIA modified only the image synthesis process (the Generator) but not the Discriminator network.
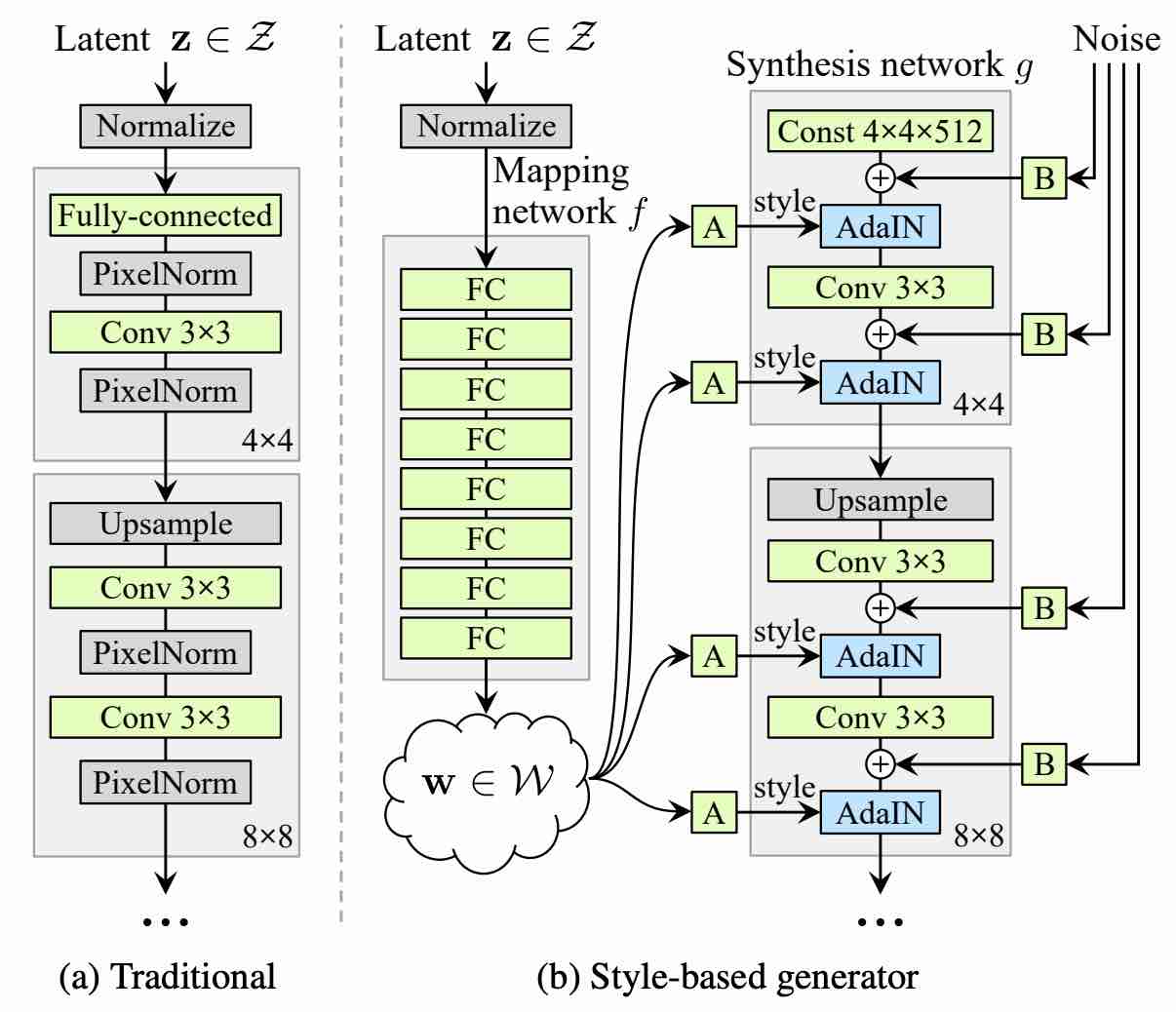
The idea behind the architecture is to embed the input latent code into an intermediate latent space, which supposedly has a profound effect on how the factors of variation are represented in the network. Researchers claim that this intermediate latent space is free from that restriction and is therefore allowed to be disentangled.
This conversion is done using a learned non-linear mapping that produces a modified latent vector. The modified vector is then specialized by applying learned affine transformations to different, so-called “styles”. In fact, these styles are simply modifications of the latent vector embedding that will be used to control normalization operations in each convolution layer.
Normalizing Convolutional Inputs
Each convolutional layer’s input is normalized with adaptive instance normalization (AdaIN) operation using the latent vector “style” embeddings. Finally, additional noise is incorporated in the network to provide means for the generation of more stochastic details in the images. This noise is simply a single-channel image consisting of uncorrelated Gaussian noise. The noise is fed before each AdaIN operation at each convolutional layer. Additionally, there is a scaling factor for the noise which is learned per-feature.

fine layers only. (d) Noise in coarse layers only.
Results
Since the main objective of the method is disentanglement and interpolation capabilities of the generative model, a naturally occurring question is: what happens with the image quality and resolution?
Well, researchers demonstrate that the radical redesign of the generator does not compromise generated image quality, but it improves it considerably. So, there does not exist a trade-off between image quality and interpolation capabilities.

generator with the FFHQ dataset.
As additional contributions, researchers provide two new automated methods for quantification of interpolation quality and disentanglement and a new varied dataset of human faces.
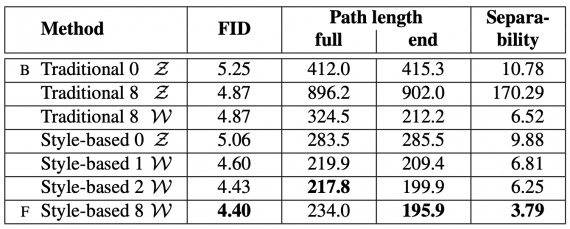
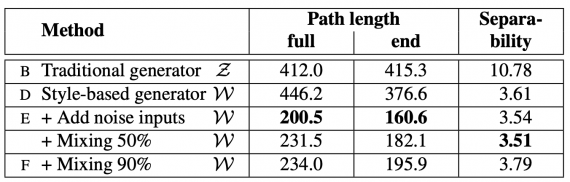
Experiments were conducted on both Celeba-HQ and the new dataset called FFHQ. The results show that StyleGAN is supperior to traditional Generative Adversarial Networks and it achieves state-of-the-art performance in traditional distribution quality metrics. The tables below show the comparison of StyleGAN with traditional GAN networks as baselines.


StyleGAN code
In conclusion, StyleGAN is currently the most powerful Generative Adversarial Network model that yields impressive visual results. Researchers from NVIDIA were able to do this just with a few simple modifications of the architecture. They improved disentanglement and interpolation quality while at the same time improving image quality and resolution. NVIDIA released the code of StyleGAN and it can be found here together with pre-trained models. The new dataset FFHQ is also open-sourced and publicly available.





