
GANs can be taught to create (or generate) worlds similar to our own in any domain: images, music, speech, etc. Since 2014, a large number of improvements of GANs have been proposed, and GANs have achieved impressive results. Researchers from MIT-IBM Watson Lab have presented GAN Paint based on Dissecting GAN – the method to validate if an explicit representation of an object is present in an image (or feature map) from a hidden layer:

State-of-the-art Idea
However, a question that is raised very often in ML is the lack of understanding of the methods developed and applied. Despite the success of GANs, visualization and understanding of GANs are very little explored fields in research.
A group of researchers led by David Bau have done the first systematic study for understanding the internal representations of GANs. In their paper, they present an analytic framework to visualize and understand GANs at the unit-, object-, and scene-level.
Their work resulted with a general method for visualizing and understanding GANs at different levels of abstraction, several practical applications enabled by their analytic framework and an open source interpretation tools for better understanding Generative Adversarial Network models.
Method
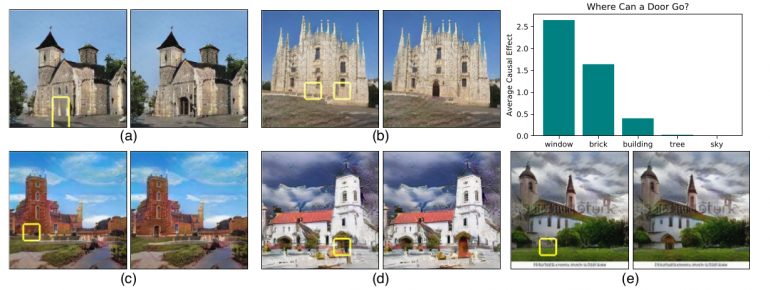
From what we have seen so far, especially in the image domain, Generative Adversarial Networks can generate super realistic images from different domains. From this perspective, one might say that GANs have learned facts about a higher abstraction level – objects for example. However, there are cases where GANs fail terribly and produce some very unrealistic images. So, is there a way to explain at least these two cases? David Bau and his team tried to answer this question among a few others in their paper. They studied the internal representations of GANs and tried to understand how a GAN represents structures and relationships between objects (from the point of view of a human observer).
As the researchers mention in their paper, there has been previous work on visualizing and understanding deep neural networks but mostly for image classification tasks. Much less work has been done in visualization and understanding of generative models.
The main goal of the systematic analysis is to understand how objects such as trees are encoded by the internal representations of a GAN generator network. To do this, the researchers study the structure of a hidden representation given as a feature map. Their study is divided into two phases that they call: dissection and intervention.
Characterizing units by Dissection
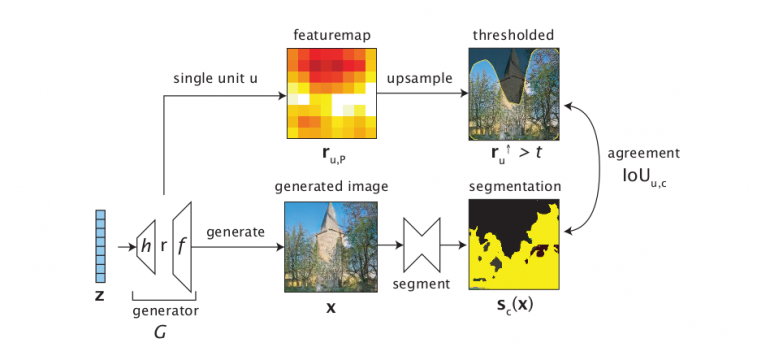
The goal of the first phase – Dissection, is to validate if an explicit representation of an object is present in an image (or feature map) from a hidden layer. Moreover, the goal is to identify which classes from a dictionary of classes have such explicit representation.
To search for explicit representations of objects they quantify the spatial agreement between the unit thresholded feature map and a concept’s segmentation mask using intersection-over-union (IoU) measure. The result is called agreement, and it allows for individual units to be characterized. It allows to rank the concepts related to each unit and label each unit with the concept that matches it best.
Measuring causal relationships using Intervention
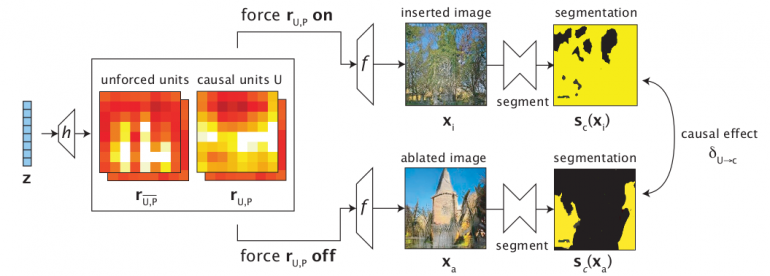
The second important question that was mentioned before is causality. Intervention – denoted as the second phase, seeks to estimate the causal effect of a set of units on a particular concept.
To measure this effect, in the intervention phase the impact of forcing units on (unit insertion) and off (unit ablation) is measured, again using segmentation masks. More precisely, a feature map’s units are forced on and off, and both resulting images from those two representations are segmented to obtain two segmentation masks. Finally, these masks are compared to measure the causal effect.
Results
For the whole study, the researchers use three variants of Progressive GANs (Karras et al., 2018) trained on LSUN scene datasets. For the segmentation task, they use a recent image segmentation model (Xiao et al., 2018) trained on the ADE20K scene dataset.
An extensive analysis was done using the proposed framework for understanding and visualization of GANs. The first part – Dissection was used by the researchers for analyzing and comparing units across datasets, layers, and models, and locating artifact units.
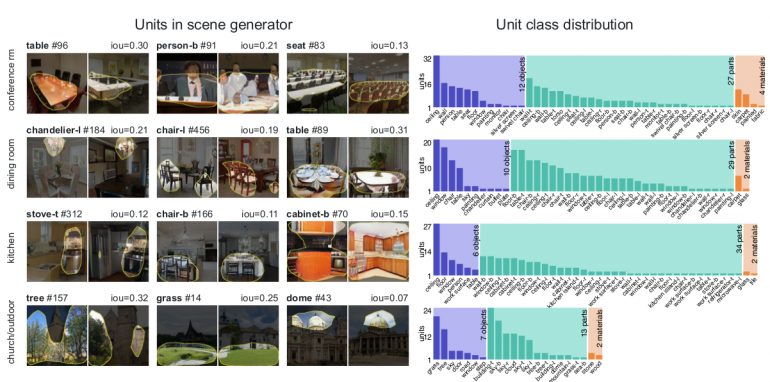
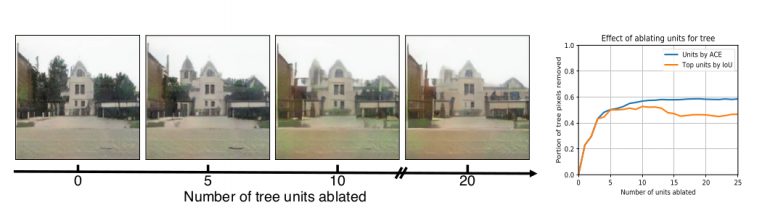
A set of dominant object classes and the second part of the framework- intervention, were used to locate causal units that can remove and insert objects in different images. The results are presented in the paper, the supplementary material and a video were released demonstrating the interactive tool. Some of the results are shown in the figures below.

Conclusion
This is one of the first extensive studies that target the understanding and visualization of generative models. Focusing on the most popular generative model – Generative Adversarial Networks, this work reveals significant insights about generative models. One of the main findings is that the larger part of GAN representations can be interpreted. It shows that GAN’s internal representation encodes variables that have a causal effect on the generation of objects and realistic images.
Many researchers will potentially benefit from the insights that came out of this work and the proposed framework that will provide a basis for analysis, debugging and understanding of Generative Adversarial Network models.








