
Precise facial landmark detection lays the foundation for a high-quality performance of many computer vision and computer graphics tasks, such as face recognition, face animation and face reenactment. Many face recognition methods rely on locations of detected facial landmarks to spatially align faces, and imprecise landmarks could lead to bad alignment and degrade face recognition performance. Precise facial landmark detection is still an unsolved problem. While significant work has been done on image-based facial landmark detection, these detectors tend to be accurate but not precise, i.e., the detector’s bias is small but the variance is significant. The main causes could be:
- insufficient training samples
- imprecise annotations
as human annotations inherently have limits on precision and consistency. Other methods that focus on video facial landmark detection utilize both detections and tracking to combat jittering and increase precision, but these methods require per-frame annotations in a video.
This research is using the unsupervised learning to do the task. Supervision-by-Registration (SBR), which augments the training loss function with supervision automatically extracted from unlabeled videos. The key observation is that the coherency of
- the detections of the same landmark in adjacent frames
- registration, i.e., optical flow, is a source of supervision.
Framework Overview
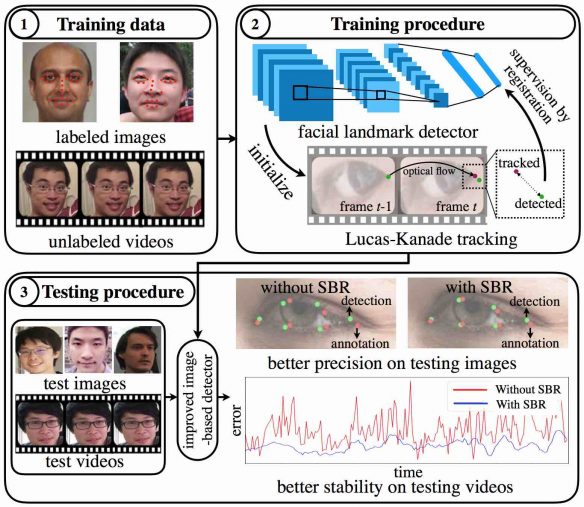
SBR is an end-to-end trainable model consists of two components: a generic detector built on convolutional networks, and a differentiable Lucas-Kanade (LK) operation. During the forward pass, the LK operation takes the landmark detections from the past frame and estimates their locations in the current frame. The tracked landmarks are then compared with the direct detections on the current frame. The registration loss is defined as the offset between them. In the backward pass, the gradient from the registration loss is back-propagated through the LK operation to encourage temporal coherency in the detector. The final output of the method is an enhanced image-based facial landmark detector which has leveraged large amounts of unlabeled video to achieve higher precision in both images and videos and more stable predictions in videos. SBR brings more supervisory signals from registration to enhance the precision of the detector. In sum, SBR has the following benefits:
- SBR can enhance the precision of a generic facial landmark detector on both images and video in an unsupervised fashion.
- Since the supervisory signal of SBR does not come from annotations, SBR can utilize a very large amount of unlabeled video to enhance the detector.
- SBR can be trained end-to-end with the widely used gradient back-propagation method.
Network Architecture

SBR consists of two complementary parts, the general facial landmark detector, and the LK tracking operation. The training procedure of supervision-by-registration with two complementary losses. The detection loss utilizes appearance from a single image and label information to learn a better landmark detector. Many facial landmark detectors take an image I as input and regress to the coordinates of the facial landmarks, i.e., D(I) = L. L² loss is used on the co-ordinated L with ground-truth labels L*.
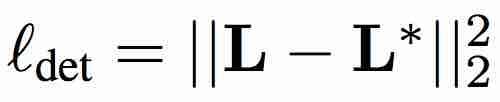
The registration loss uncovers temporal consistency by incorporating a Lucas-Kanade operation into the network. Registration loss can be computed in an unsupervised manner to enhance the detector. It is realized with a forward-backward communication scheme between the detection output and the LK operation. The forward communication computes the registration loss while the backward communication evaluates the reliability of the LK operation. The loss is as follows:
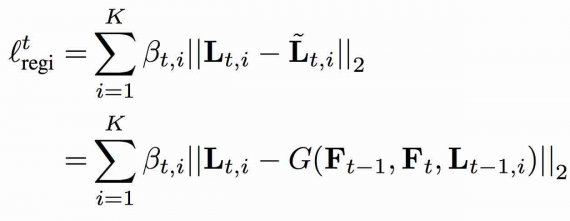
Complete loss function: Let N be the number of training samples with ground truth. For notation brevity, we assume there is only one unlabeled video with T frames. Then, the complete loss function of SBR is as follows:
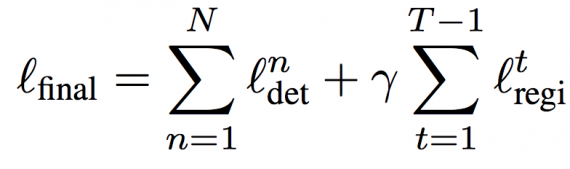
The first detector is CPM, which utilizes the ImageNet pre-trained models as the feature extraction part. The first four convolutional layers of VGG-16 is used for feature extraction and use only three CPM stages for heatmap prediction. The faces are cropped and resized into 256×256 for pre-processing. We train the CPM with a batch size of 8 for 40 epochs in total. The learning rate starts at 0.00005 and is reduced by 0.5 at 20th and 30th epochs.
Good news! Now you may swap face with celebrity in a second with our brand new app SWAPP!
The second detector is a simple regression network, denoted as Reg. VGG-16 is used as the base model and change the output neurons of the last fully-connected layer to K×2, where K is the number of landmarks. Input images have been cropped to 224×224 for this regression network.
Result
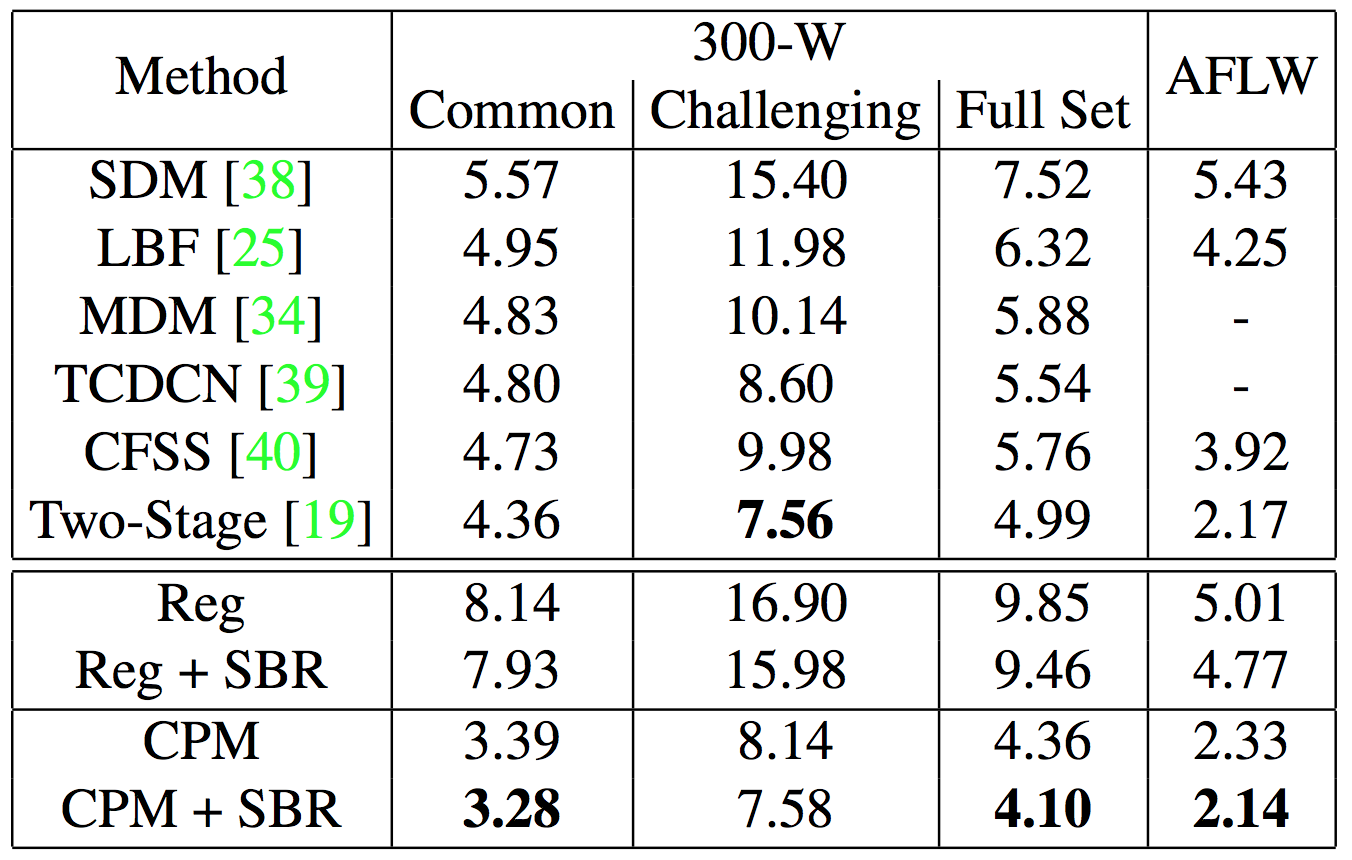

The datasets used to compute the 300-W, AFLW, youtube-face, 300-VW and YouTube Celebrities. The result of SBR is shown in fig:2 is performed on both the Reg (regression-based) and CPM (heatmap-based) on AFLW and 300-W. Normalized Mean Error (NME) is used to evaluate the performance of images.
The Bottom Line

SBR achieved the state-of-the-art result on all of the datasets. supervision-by-registration (SBR). The main advantages are:
- It does not rely on human annotations which tend to be imprecise,
- The detector is no longer limited to the quantity and quality of human annotations, and
- Back-propagating through the LK layer enables more accurate gradient updates than self-training.
Also, experiments on synthetic data show that annotation errors in the evaluation set may make a well-performing model seem like it is performing poorly, so one should be careful of annotation imprecision when interpreting quantitative results.






