A picture may be worth a thousand words, but at least it contains a lot of very diverse information. This not only comprises what is portrayed, e.g., a composition of a scene and individual objects but also how it is depicted, referring to the artistic style of a painting or filters applied to a photo. Especially when considering artistic images, it becomes evident that not only content but also style is a crucial part of the message an image communicates (just imagine van Gogh’s Starry Night in the style of Pop Art). A vision system then faces the challenge to decompose and separately represent the content and style of an image to enable a direct analysis based on each individually. The ultimate test for this ability is style transfer, exchanging the style of an image while retaining its content.

Recent work has been done using neural networks and the crucial representation in all these approaches has been based on a VGG16 or VGG19 network, pretrained on ImageNet. However, a recent trend in deep learning has been to avoid supervised pre-training on a million images with tediously labeled object bounding boxes. In the setting of style transfer, this has the particular benefit of avoiding from the outset any bias introduced by ImageNet, which has been assembled without artistic consideration. Rather than utilizing a separate pre-trained VGG network to measure and optimize the quality of the stylistic output, an encoder-decoder architecture with adversarial discriminator is used, to stylize the input content image and also use the encoder to measure the reconstruction loss.
State of the Art
To enable a fast style transfer that instantly transfers a content image or even frames of a video according to a particular style, a feed-forward architecture is required rather than the slow optimization-based approach. To this end, t an encoder-decoder architecture that utilizes an encoder network E to map an input content image x onto a latent representation z = E(x). A generative decoder G then plays the role of a painter and generates the stylized output image y = G(z) from the sketchy content representation z. Stylization then only requires a single forward pass, thus working in real-time.
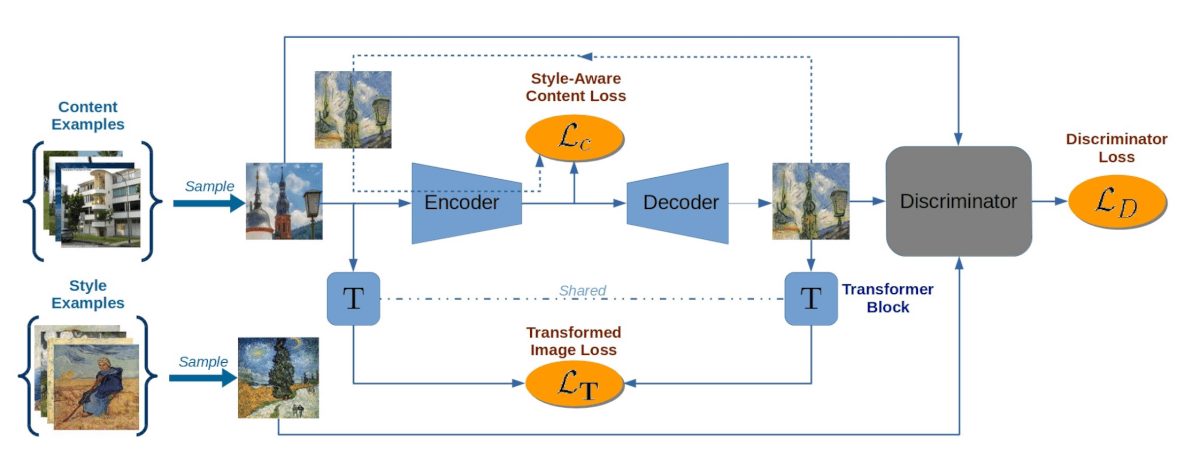
1) Training with a Style-Aware Content Loss
Previous approaches have been limited in that training worked only with a single style image. In contrast, in this work, a single image y0 is given with a set Y of related style images yj ∈ Y. To train E and G, a standard adversarial discriminator D is used to distinguish the stylized output G(E(xi)) from real examples yj ∈ Y. The transformed image loss is defined as then:
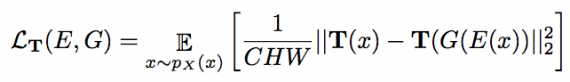
where C × H × W is the size of image x and for training T is initialized with uniform weights. Fig. 3 illustrates the full pipeline of approach. To summarize, the full objective of our model is:
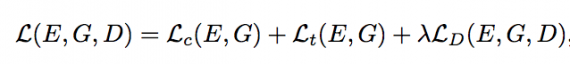
where λ controls the relative importance of adversarial loss.
2) Style Image Grouping
Given a single style image y0 the task is to find a set Y of related style images yj ∈ Y. A VGG16 is trained from scratch on Wikiart dataset to predict an artist given the artwork. The network is trained on the 624 largest (by the number of works) artists from the Wikiart dataset. Artist classification, in this case, is the surrogate task for learning meaningful features in the artworks’ domain, which allows retrieving similar artworks to image y0.
Let φ(y) be the activations of the fc6 layer of the VGG16 network C for input image y. To get a set of related style images to y0 from the Wikiart dataset Y we retrieve all nearest neighbors of y0 based on the cosine distance δ of the activations φ(·), i.e.
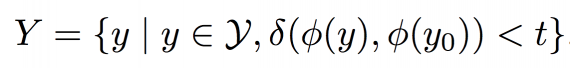
The basis for style transfer model is an encoder-decoder architecture. The encoder network contains 5 conv layers: 1×conv-stride-1 and 4×conv-stride-2. The decoder network has 9 residual blocks, 4 upsampling blocks, and 1×conv-stride-1. The discriminator is a fully convolutional network with 7×conv-stride-2 layers. During the training process sample 768 × 768 content image patches from the training set of Places365 [51] and 768×768 style image patches from the Wikiart dataset. We train for 300000 iterations with batch size 1, learning rate 0.0002 and Adam optimizer. The learning rate is reduced by a factor of 10 after 200000 iterations.
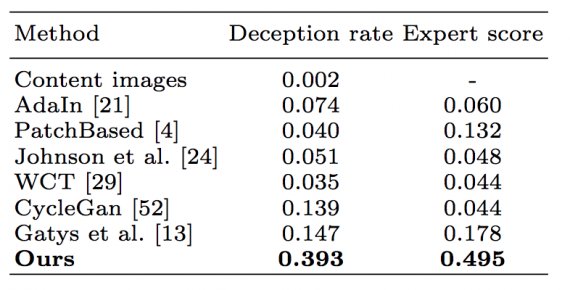
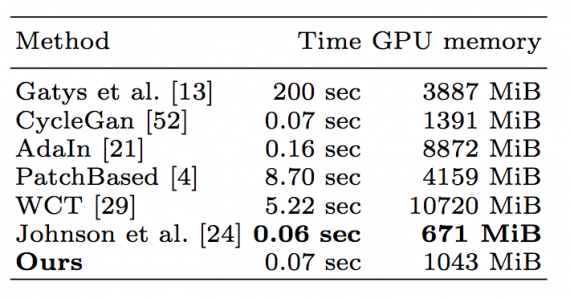
Experts were asked to choose one image which best and most realistically reflects the current style. The score is computed as the fraction of times a specific method was chosen as the best in the group. Mean expert score is calculated for each method using 18 different styles and report them in Tab. 1.
Result
This paper has addressed major conceptual issues in state-of-the-art approaches for style transfer. The proposed style-aware content loss enables a real-time, high-resolution encoder-decoder based stylization of images and videos and significantly improves stylization by capturing how style affects content.













