
Google has introduced AudioPaLM, a large language model for speech processing and generation that combines two Google language models, PaLM-2 and AudioLM, into a multimodal architecture. The model can recognize speech, mimic intonation and accents, perform speech translation to other languages based on short voice prompts, and transcribe speech.
AudioPaLM inherits the speaker identification and intonation copying capabilities from AudioLM, and the linguistic abilities of LLM from PaLM-2. Experiments have shown that initializing AudioPaLM with the text model’s weights obtained from pre-training significantly improves speech processing. The resulting model surpasses state-of-the-art speech translation models and is capable of translating speech to text for language pairs that were not considered during training (zero-shot translation).
Model Description
The diagram illustrates the functioning of the AudioPaLM model in speech-to-speech translation and automatic speech recognition tasks:
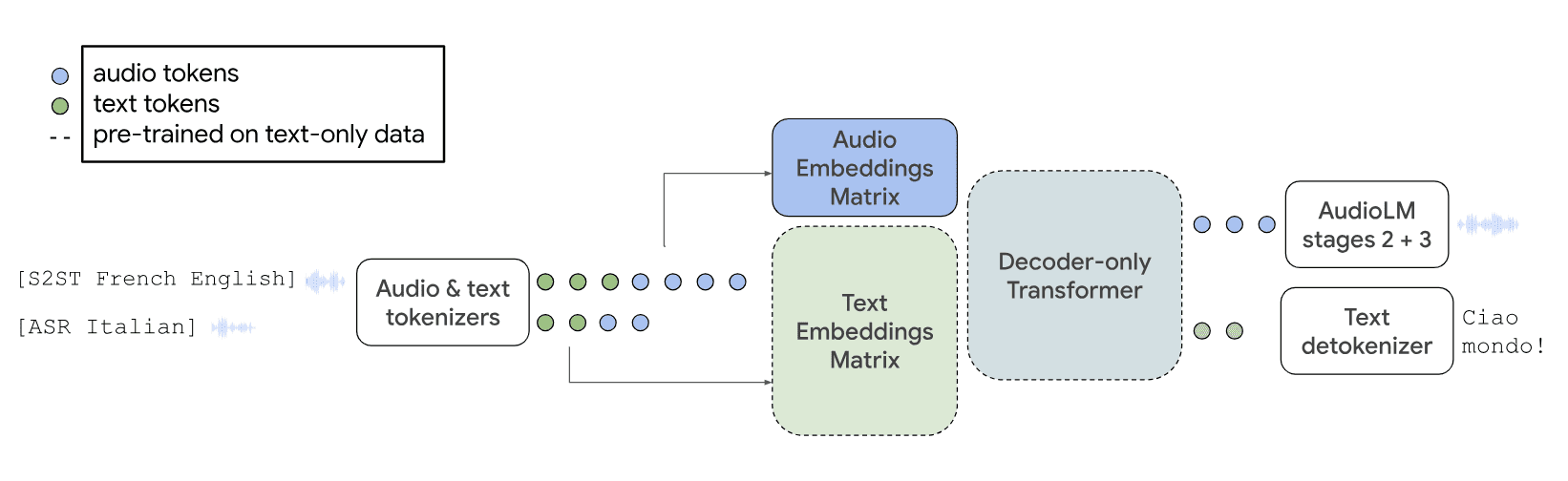 The embedding matrix of the pre-trained text model (dashed lines) is used to model a set of audio tokens. The rest of the model architecture remains unchanged: a mixed sequence of text and audio tokens is input, and the model decodes these tokens into text or audio. The audio tokens are further transformed back into the original audio using layers from the AudioLM model.
The embedding matrix of the pre-trained text model (dashed lines) is used to model a set of audio tokens. The rest of the model architecture remains unchanged: a mixed sequence of text and audio tokens is input, and the model decodes these tokens into text or audio. The audio tokens are further transformed back into the original audio using layers from the AudioLM model.
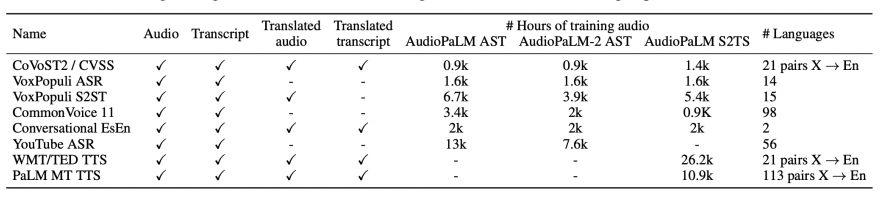
Datasets used to train the model:
Results
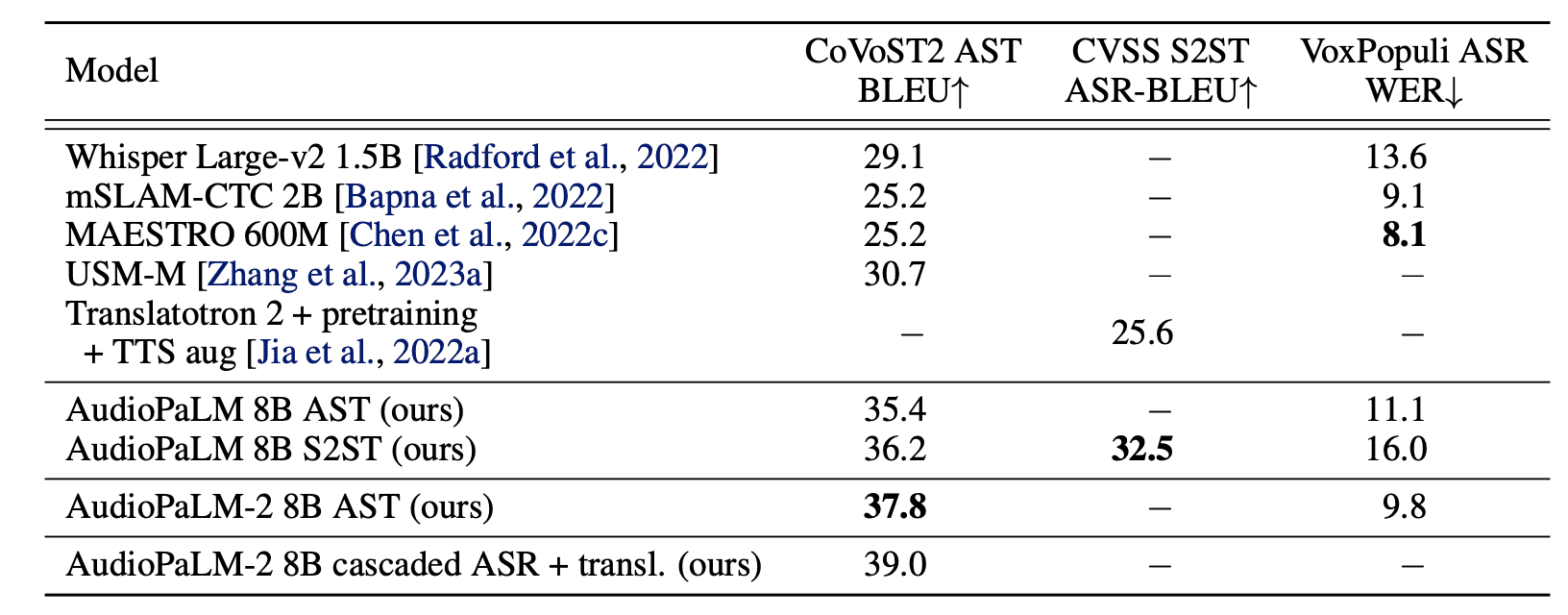
Researchers evaluated the model’s performance on CoVoST2 AST BLEU, CVSS S2ST ASR-BLEU, and VoxPopuli ASR VER benchmarks, comparing the results with other contemporary models.
Additional examples of the model’s work, experiments with different languages, and transcription generation are available on the model’s presentation page.











