
Researchers at Microsoft Research have introduced Phi-1, a language model for code generation with just 1.3 billion parameters. This model has achieved a state-of-the-art level of code generation using a dataset curated by the authors. The researchers discovered that most existing code datasets are inadequate for training models as they lack complete information, meaningful comments, and mostly consist of configuration files or draft versions.
The authors created their own high-quality programming textbook-like dataset called CodeTextBook, which contains 6 billion tokens of Python code selected from The Stack and StackOverflow, along with 1 billion tokens generated by the GPT-3.5 model, including comments and descriptions.

The model was further fine-tuned on the CodeExercises dataset, which consists of 180 million tokens of synthetically generated exercises with high-quality descriptions. Surprisingly, this fine-tuning endowed the model with emergent properties, such as the ability to utilize external libraries like Pygame and Tkinter, despite these libraries not being mentioned in the dataset.

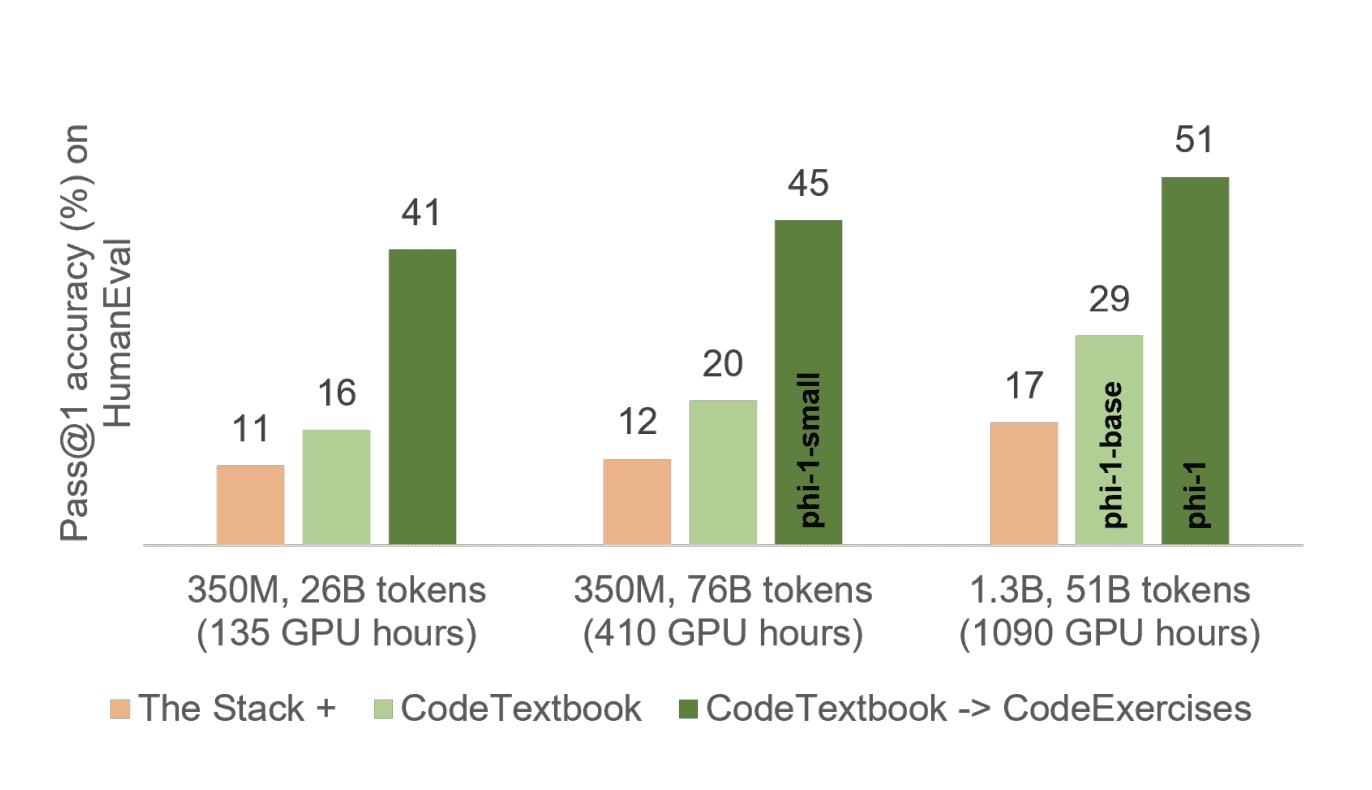
The researchers evaluated the phi-1-base model, which was not fine-tuned on the CodeExercises dataset, and the phi-1-small model, a more compact model with 350 million parameters trained using the same methodology as the phi-1 model. The phi-1-small model achieved a 45% performance on the HumanEval test.
Model Description
Phi-1 is based on the Transformer architecture and consists of 1.3 billion parameters. The model was trained for 4 days on 8 Nvidia A100 GPUs using the authors’ CodeExercises dataset, which approximates the quality of a programming textbook and contains 6 billion tokens. The dataset was supplemented with 1 billion tokens synthetically generated by the GPT-3.5 model.
The image below shows examples of high-quality and low-quality training data:

Phi-1 Results
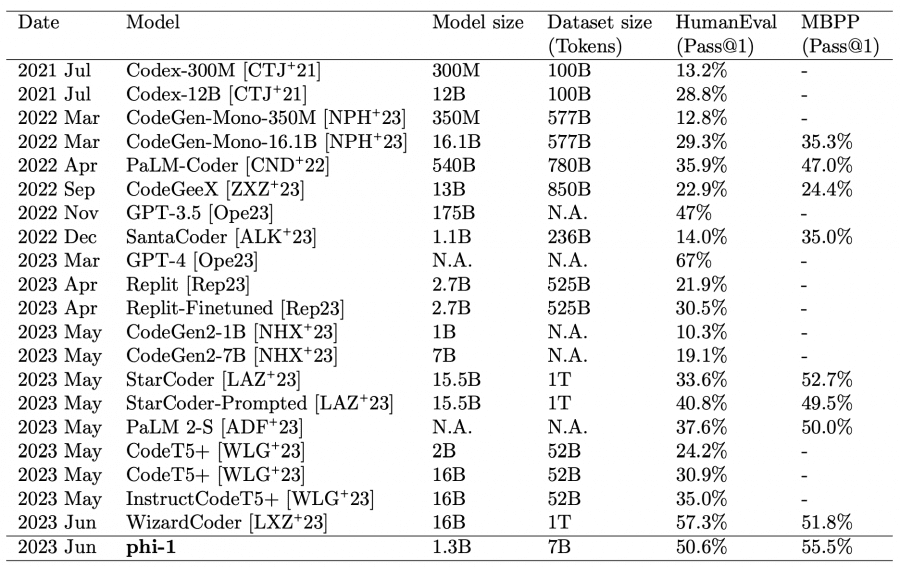
Preliminary training on the CodeTextbook dataset and fine-tuning on CodeExercises resulted in near state-of-the-art performance. Despite its relatively small scale, phi-1 achieved a pass@1 accuracy of 50.6% on the HumanEval benchmark and 55.5% on the MBPP benchmark, falling slightly behind GPT-4 and WizardCoder (the latter only on the HumanEval benchmark).
The model exhibits remarkable emergent properties compared to the base phi-1 model, which was not fine-tuned on the high-quality dataset. For example, after fine-tuning on the CodeExercises dataset, the model learned to use external libraries like Pygame and Tkinter, even though these libraries were not included in the exercises.

This study confirms that the quality of training data is more important than its quantity.











