
Let’s say you have a picture of a Hugh Jackman for an advertisement. He looks great, but the client wants him to look a little bit happier. No, you don’t need to invite the celebrity for another photo shoot. You even don’t need to spend hours with Photoshop. You can automatically generate a dozen images from this single image, where Hugh will have the smiles of different intensities. You can even create an animation from this single image, where Hugh changes his facial expression from absolutely serious to absolutely happy.
The authors of a novel GAN conditioning scheme based on Action Units (AUs) annotations claim that such scenario is not futuristic but absolutely feasible as of today. And in this article, we’re going to have an overview of their approach, observe the results generated with the suggested method, and compare its performance with the state-of-the-art approaches.
Suggested Method
Facial expressions are the result of the combined and coordinated action of facial muscles. They can be described in terms of the so-called Action Units, which are anatomically related to the contractions of specific facial muscles. For example, the facial expression for fear is generally produced with the following activations: Inner Brow Raiser (AU1), Outer Brow Raiser (AU2), Brow Lowerer (AU4), Upper Lid Raiser (AU5), Lid Tightener (AU7), Lip Stretcher (AU20) and Jaw Drop (AU26). The magnitude of each AU defines the extent of emotion.
Building on this approach to defining facial expressions, Pumarola and his colleagues suggest a GAN architecture, which is conditioned on a one-dimensional vector indicating the presence/absence and the magnitude of each action unit. They train this architecture in an unsupervised manner that only requires images with their activated AUs. Next, they split the problem into two main stages:
- Rendering a new image under the desired expression by considering an AU-conditioned bidirectional adversarial architecture provided with a single training photo.
- Rendering back the synthesized image to the original pose.
Moreover, the researchers wanted to ensure that their system will be able to handle images under changing backgrounds and illumination conditions. Hence, they’ve added an attention layer to their network. It focuses the action of the network only in those regions of the image that are relevant to convey the novel expression.
Let’s now move on to the next section to reveal the details of this network architecture – how does it succeed in generating anatomically coherent facial animations from images in the wild?
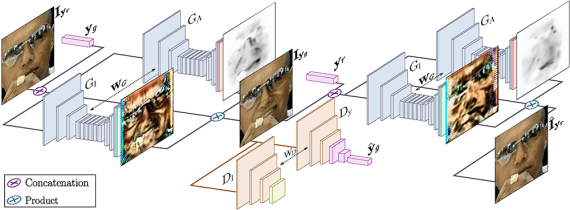
Network Architecture
The proposed architecture consists of two main blocks:
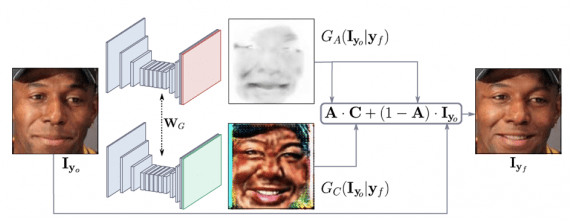
- Generator G regresses attention and color masks (note that it’s applied twice, first to map the input image and then to render it back). The aim was to make generator focusing only on those regions that are responsible for synthesizing the novel face expression while keeping the rest elements of the image such as hair, glasses, hats or jewelry untouched. Thus, instead of regressing the full image, this generator outputs a color mask C and an attention mask A. The mask A indicates to which extent each pixel of the C contributes to the output image. This leads to sharper and more realistic images at the end.
- Conditional critic. Critic D evaluates the generated image in its photorealism and expression conditioning fulfillment.
The loss function for this network is a linear combination of several partial losses: image adversarial loss, attention loss, conditional expression loss, and identity loss:
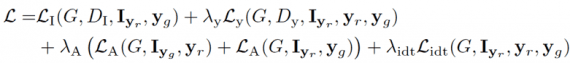
The model is trained on a subset of 200 000 images from the EmotioNet dataset using the Adam optimizer with the learning rate of 0.0001, beta1 0.5, beta2 0.999 and batch size 25.
Experimental Evaluation
The image below demonstrates the model’s ability to activate AUs at different intensities while preserving the person’s identity. For instance, you can see that the model properly handles the case with zero intensity and generates an identical copy of the input image. For the non-zero cases, the model realistically renders complex facial movements and outputs images that are usually indistinguishable from the real ones.

Next figure displays the attention mask A and the color mask C. You can see how the model focuses its attention (darker area) onto the corresponding action units in an unsupervised manner. Hence, only the pixels relevant to the expression change are carefully estimated, while the background pixels are directly copied from the input image. This feature of the model is very handy when dealing with images in the wild.

Now, let’s see how the model handles the task of editing multiple AUs. The outcomes are depicted below. You can observe here remarkably smooth and consistent transformation across frames even with challenging light conditions and non-real world data, as in the case of the avatar. These results encourage the authors to further extend their model to video generation. They should definitely try, shouldn’t they?

Meanwhile, they compare their approach against several state-of-the-art methods to see how well their model performs at generating different facial expressions from a single image. The results are demonstrated below. It looks like the bottom row, representing the suggested approach, contains much more visually compelling images with notably higher spatial resolution. As we’ve already discussed before, the use of the attention mask allows applying the transformation only on the cropped face and put it back on the original image without producing an artifact.

Limitations of the Model
Let’s now discuss the model’s limits – which types of challenging images it is still able to handle, and when it actually fails. As demonstrated on the image below, the model succeeds when dealing with human-like sculptures, non-realistic drawings, non-homogeneous textures across the face, anthropomorphic faces with non-real textures, non-standard illuminations/colors and even the face sketches.
However, there are several cases, when it fails. The first failure case depicted below results from the errors in the attention mechanism when given extreme input expressions. The model may also fail when the input image contains non-previously seen occlusions such as an eye patch causing artifacts in the missing face attributes. It is also not ready to deal with non-human anthropomorphic distributions as in the case of cyclopes. Finally, the model can also generate artifacts like human face features when dealing with animals.

Bottom Line
The model presented here is able to generate anatomically-aware face animations from the images in the wild. The resulting images surprise with their realism and high spatial resolution. The suggested approach advances current works, which had only addressed the problem for discrete emotions category editing and portrait images. Its key contributions include a) encoding face deformations by means of AUs to render a wide range of expressions and b) embedding an attention model to focus only on the relevant regions of the image. Several failure cases that were observed are presumably due to insufficient training data. Thus, we can conclude that the results of this approach are very promising, and we look forward to observing its performance for video sequences.









