
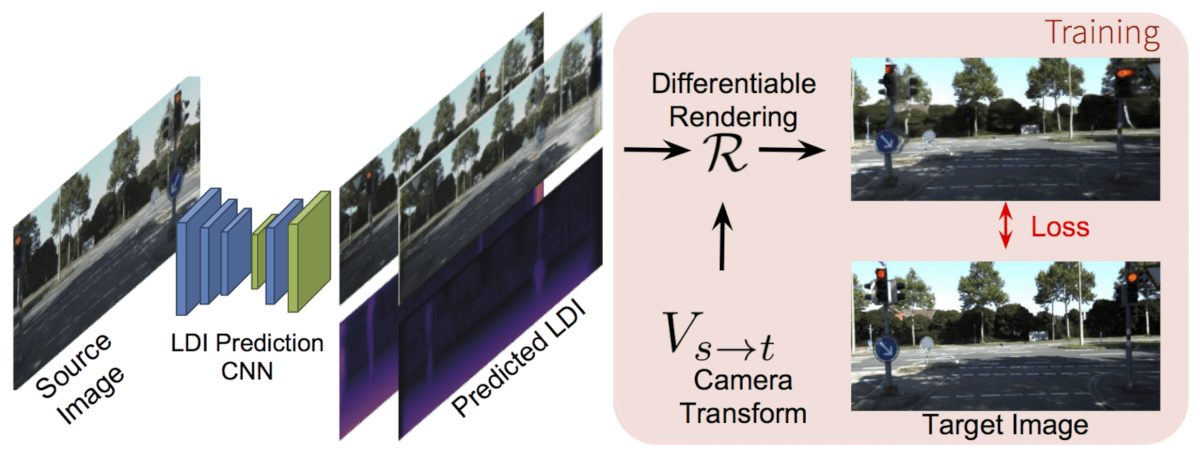
Unlike to the inception period of deep learning, techniques such as unsupervised, self-supervised and multi-view learning have started to receive more and more attention recently. Arguing that lack of supervision makes some problems much more difficult to be solved with Deep Learning techniques, researchers from the University of California, Berkeley and Google have proposed an interesting multi-view learning based approach for 3D scene rendering/prediction.
To overcome the key challenge – lack of available training data the researchers rely on a multi-view based approach which will allow learning a layered representation of the 3D scene. In fact, they use a representation known as layered depth image (LDI) and the proposed method is able to infer such representation of the 3D space from a single given image.
Data Representation
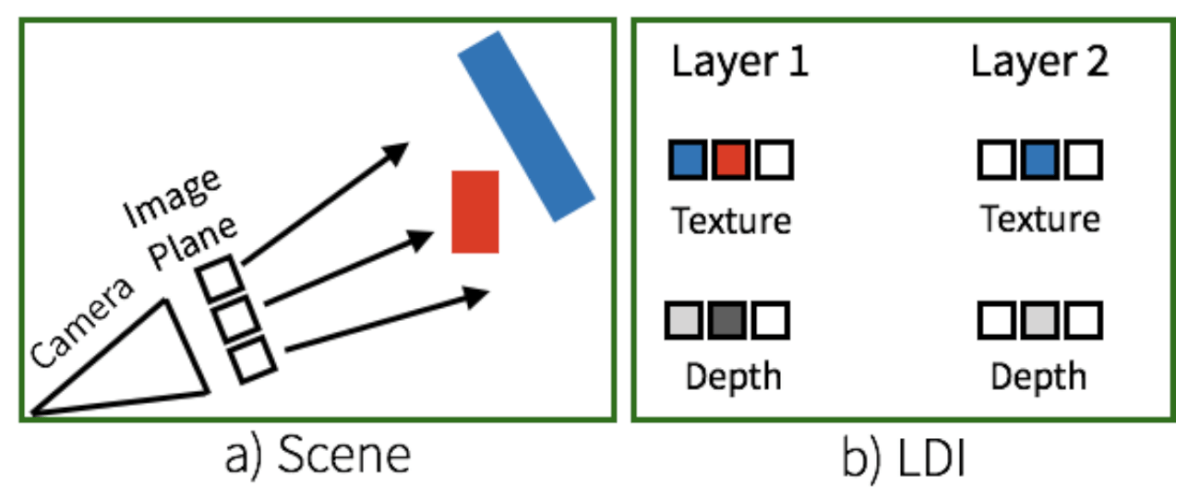
There have been many attempts to use deep learning methods to infer a depth map out of a single image. Many of them are trying to predict a single depth value per pixel both from a single image or monocular videos and calibrated stereo images. Unlike these approaches, in this paper, the goal is to learn a mapping from a single image to a layer-based representation. Therefore, multiple ordered depth values have to be estimated per pixel from the input image and the LDI representation allows this.
Method
Being able to reconstruct a 3D scene out of a single flat image, means also to be able to predict the part of the space which is not visible from the particular viewpoint. In this method, the occluded space behind the visible parts is also estimated as it is required for a full scene rendering and understanding. As mentioned before, inferring a depth map answers, for each pixel the question: “how far from the camera is the point imaged at this pixel?”. Additionally, in this approach, the LDI representation answers also the question: “what lies behind the visible content of this pixel?”, which pushes this approach a bit further in the context of scene description allowing for beyond 2.5D prediction.

Data
The Layer Depth Image representation is specific itself and it represents a 3D structure as layers of depth and color images. In fact, the 3D space is not sliced along the depth dimension but instead, the layers are defined by the surface – the visible part from the camera viewpoint. An LDI image has L tuples of color (i.e. texture) and disparity (inverse depth) images.
Therefore, the training dataset used in this method consists of N image pairs, each of them represented with source and target images (Is, It), camera intrinsics (Ks, Kt) and a relative camera transform given by the rotation and translation (R, t).
View Synthesis as Supervision Signal
Given a source image Is, the method is estimating the corresponding LDI representation using a Convolutional Neural Network. The supervision signal comes from the target image (a flat image from a different view) by employing a view-synthesis method and enforcing similarity between the target image and a rendered image using the LDI estimation and the viewpoint. The predicted target view i.e. the rendered image is done using a geometrically defined rendering function and the know camera transform (the method assumes that the camera transform is known). To do the rendering, the LDI image is treated as a textured point-cloud. Then, each source point is forward-projected onto the target frame, and after that occlusion are handled by a proposed ‘soft z-buffer’, to finally render the target image by a weighted average of the colors of projected points.
Network Architecture
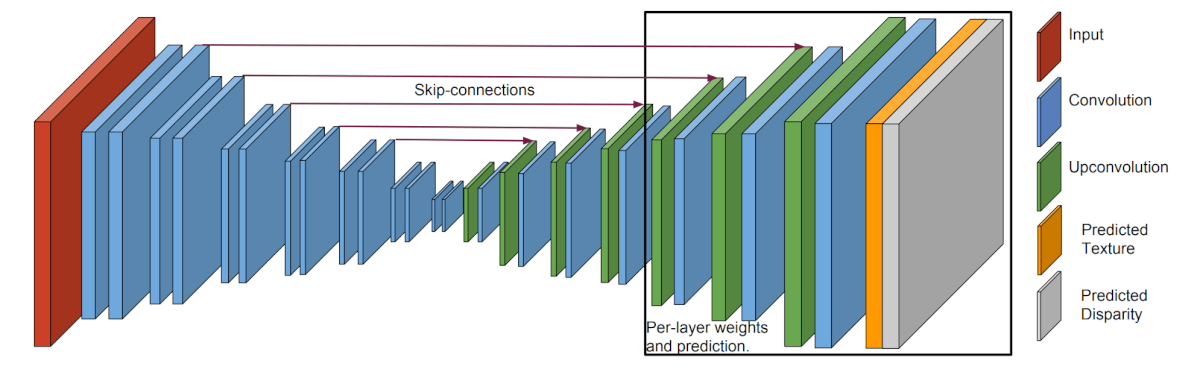
The network architecture used for the LDI estimation is a DispNet Convolutional network, which given a color image computes spatial features at various resolutions and decodes back to the original resolution. Skip connections are also added to the network. To leverage the fact that not all the layers get same learning signal, the authors add separate prediction blocks (last part of the network) for each layer. As a training objective, they enforce that this rendered image should be similar to the observed image from that viewpoint.
Evaluation and Conclusions
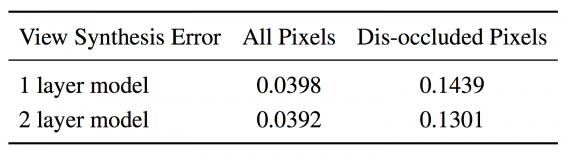
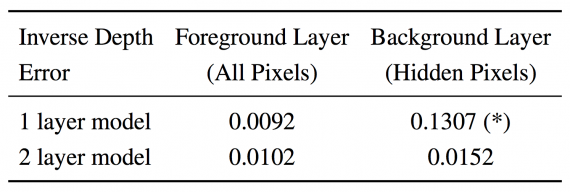
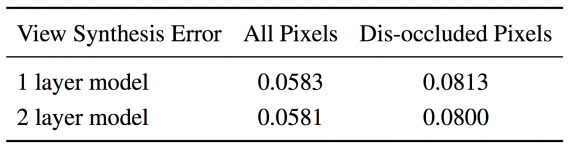
To evaluate the proposed method, the researchers have used both synthetic data and data from a real outdoor driving dataset. By evaluating the separate modules and the solution as a whole both quantitatively and qualitatively, they conclude that the method is able to successfully capture occluded structure.

Although we are still far from full 3D scene understanding, approaches such as this one have proven that deep learning techniques can be successfully applied to scene understanding (even from a single image). In particular, this method pushes the boundaries of scene understanding and goes a step beyond 2.5D scene prediction.




