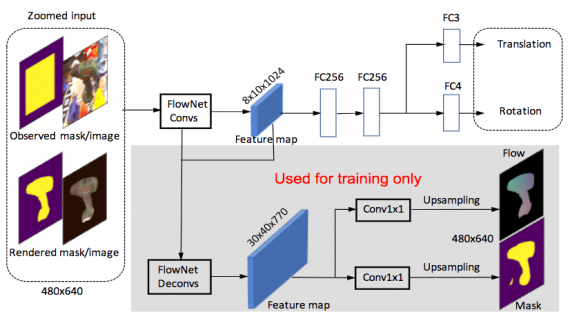
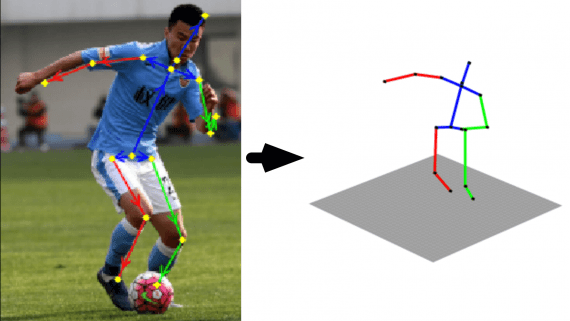
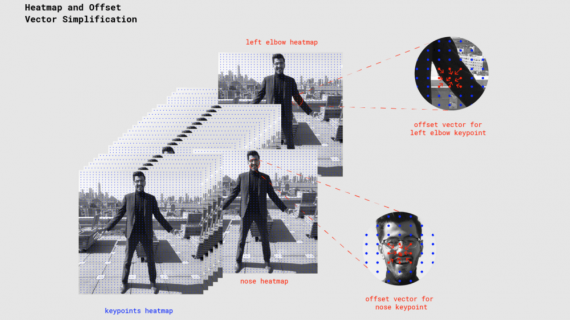
Google Try-on: примерка одежды онлайн
18 июня 2023

Google Try-on: примерка одежды онлайн
Google представила Try-on – диффузионную модель, позволяющую пользователям сервиса «Покупки» примерить одежду на моделях с различным телосложением и оттенком кожи. Модель меняет одежду в один клик, фотореалистично воспроизводит драпировку, облегание,…