
Люди обладают удивительной способностью воображения. Воображение и обучение на опыте лежат в основе нашего интеллекта. Обе эти способности связаны – воображение работает благодаря памяти и опыту. Поэтому мы можем определить форму объекта, даже если рассматриваем его только с одной стороны, можем представить движение или деформацию объекта только взглянув на него в статическом положении. Память дает нам возможность представлять сложные вещи. К примеру, как будет выглядеть тот или иной человек в различных позах.
Исследователи из Массачусетского технологического института рассмотрели задачу моделирования человеческой позы на изображении. При помощи фотографии человека и модели целевой позы (target pose) нейросеть создаёт реалистичное изображение:
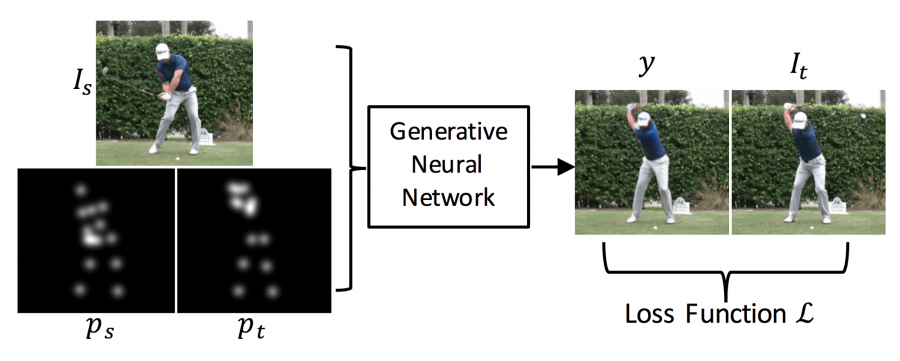
В данной работе исследователи объединяют несколько техник и ставят задачу синтезирования позы человека на изображении в контексте глубокого обучения. Предлагаемый подход уникален, так как его использование в машинном обучении позволяет создавать реалистичные изображения.
Постановка проблемы
Постановка проблемы: перестраивание позы человека с помощью заданного изображения и модели конкретной позы:
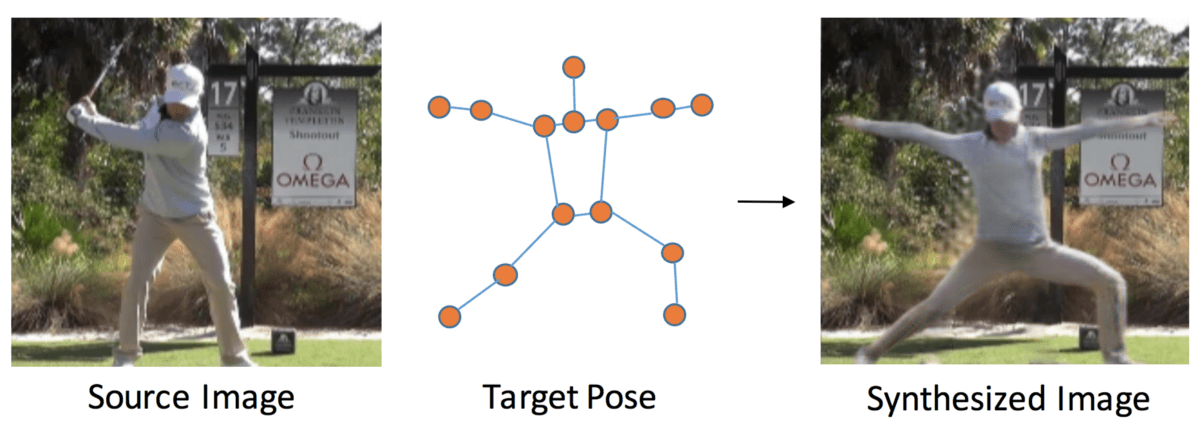
С точки зрения постановки проблемы, задача моделирования человеческой позы нетривиальна, так как существует несколько важных аспектов, которые необходимо учитывать.
- Во-первых, генерируемое изображение должно быть максимально реалистичным;
- Во-вторых, изменение позы требует сегментации человека и других объектов на изображении;
- В-третьих, моделирование новой позы оставляет пустые места на заднем плане, которые должны быть надлежащим образом заполнены.
Корректировка этих изменений на изображении – сложная задача. В своей работе исследователи решают эту задачу, разделяя её на подпроблемы, решаемые отдельными модулями. Фактически, они создают модульную архитектуру, состоящую из нескольких частей, каждая из которых решает отдельные задачи и обеспечивает реалистичный синтез изображений. Предлагаемая модель состоит из 4-х модулей:
A. Модуль сегментации исходного изображения;
B. Модуль пространственной трансформации;
C. Модуль синтеза переднего плана;
D. Модуль синтеза фона.
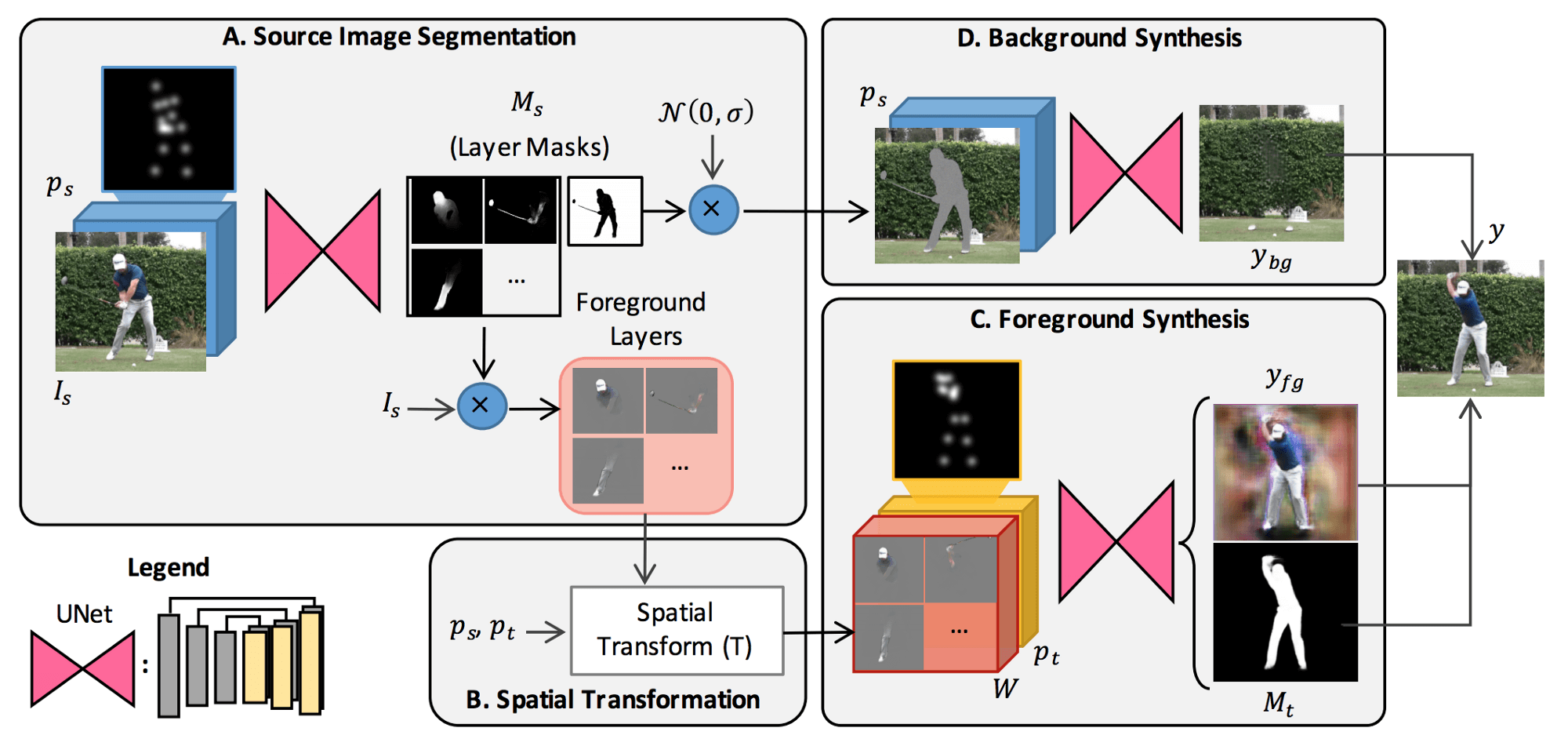
Сегментация исходного изображения
Артефакты на изображении, возникающие при трансформации позы, часто бывают следующими: появление дополнительных частей тела, большие смещения конечностей и наложение частей тела. Чтобы преодолеть эти проблемы, первый модуль сегментирует исходное изображение. Сегментация двухуровневая: сначала изображение разделяется на передний план и фон, а затем передний план (человек) сегментируется на части тела: руки, ноги и т.д. Поэтому на выходе этапа сегментации есть один фоновый слой и L передних слоев, соответствующих каждой из L предварительно сегментированных частей тела.
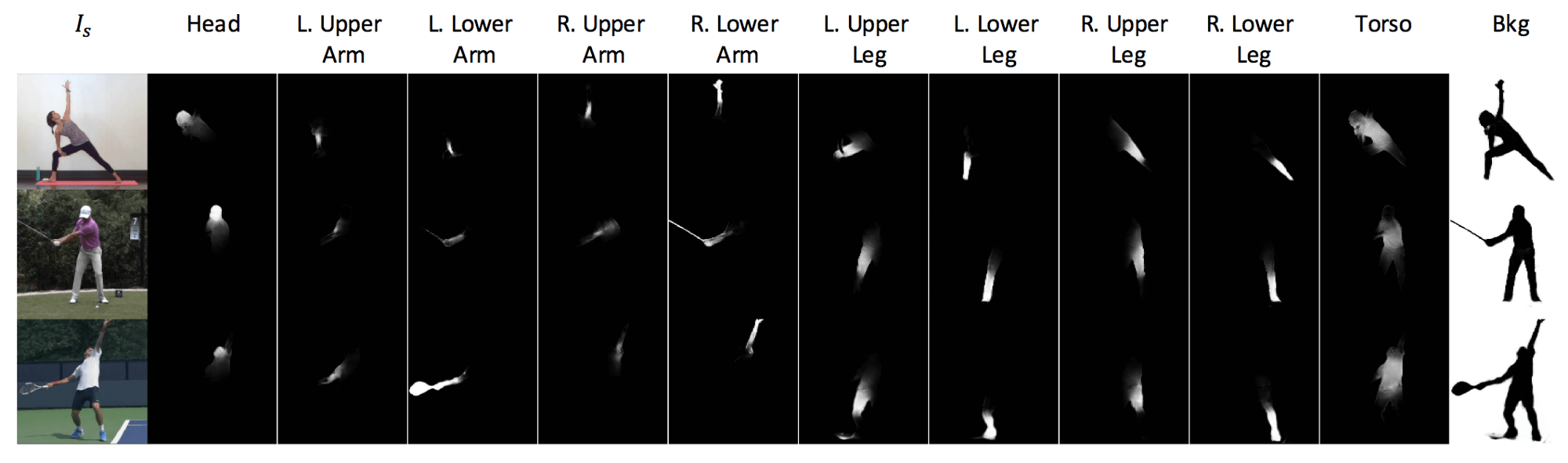
В качестве входных данных вводится совокупность исходного изображения и моделей начальной и желаемой поз. В отличие от исходного изображения, которое является RGB-изображением, позы определяются как стек из нескольких слоев. Поза представляет собой трехмерный объект, заданный в R (HxWxJ). Каждый из J-слоев (или каналов) в представлении позы содержит Гауссову кривую, центрированную в координатах (x,y) каждого сустава. Гауссово представление (вместо детерминированного представления) вводит определённую степень регуляризации, поскольку совместные оценки местоположения могут быть часто зашумлены и неточны. При проведении тестов авторы сегментировали 14 частей тела (голова, шея, плечи, локти, запястья, бедра, колени и лодыжки).
Результаты работы модуля сегментации
Модуль сегментации представляет собой нейросеть U-Net, которая принимает конкатенированный объем входного изображения и слоев позы в качестве входных данных и выдает L-слоев, определяя примерное местоположение каждого сустава. Выходной сигнал фактически представляет собой двумерную Гауссову маску над пространственной областью каждой части тела, которая позволяет получить желаемую сегментацию.
- Пространственная трансформация. Сегментированные слои из модуля сегментации преобразуютсятаким образом, чтобы соответствовать желаемым частям позы. Пространственное преобразование не изучается, а непосредственно вычисляется из входных моделей поз.
- Синтез переднего плана. Модуль синтеза переднего плана представляет собой U-образную нейросеть, которая принимает пространственно преобразованные слои со слоями моделируемой позы в виде конкатенированного объема и выдает два разных результата — первый из них является необходимым передним планом, а второй — необходимой маской.
- Синтез фона. Задача, которую решает модуль синтеза фона, заключается в заполнении отсутствующего, который закрывается человеком во входном изображении. Этот модуль также является U-сетью, работающей с объемом входного изображения (наряду с гауссовым шумом вместо пикселей переднего плана) и маской позы на входе. Он выводит реалистичный фон без переднего плана — то есть без человека на изображении.
Результаты работы отдельных модулей, создающих новое изображение.
Синтез изображений
Наконец, составляется взвешенная линейная комбинация необходимого фонового и переднепланового изображений (см. формулу ниже).
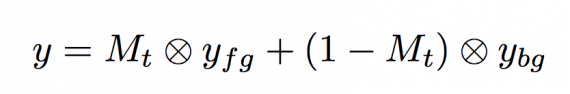
Как и во многих генеративных нейросетях, исследователи предлагают использовать дискриминатор, чтобы генерировать реалистичные изображения. Генеративная модель была обучена с использованием функций потерь L1, L-VGG и L-VGG + GAN с использованием бинарной классификационной ошибки дискриминатора.
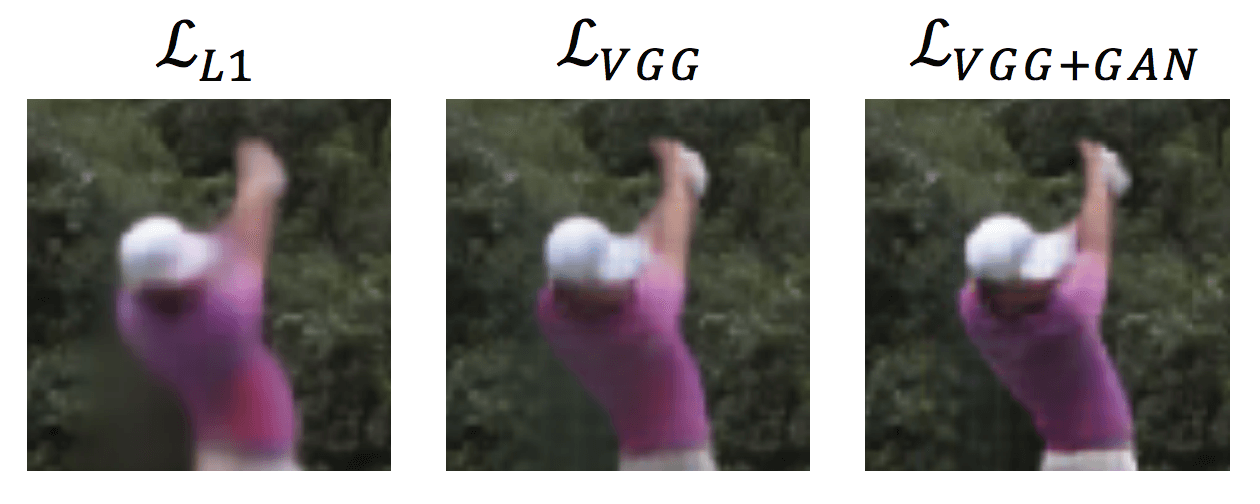
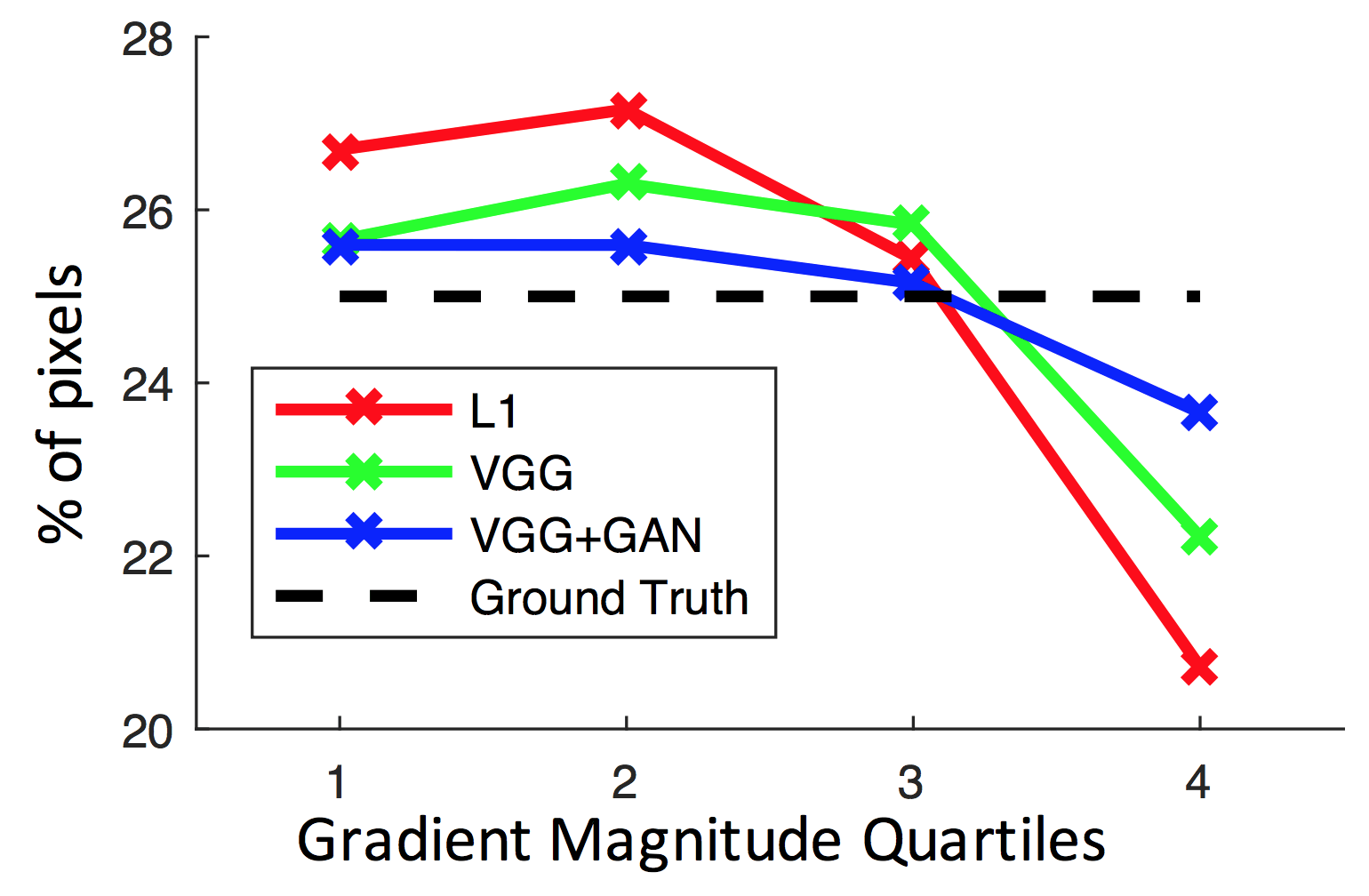
Оценка
Оценка метода производилась на примере роликов на Youtube. Эксперименты проводились с использованием видеороликов, на которых происходили три класса действий: игра в гольф (136 роликов), занятие йогой (60 роликов) и занятие теннисом (70 роликов).
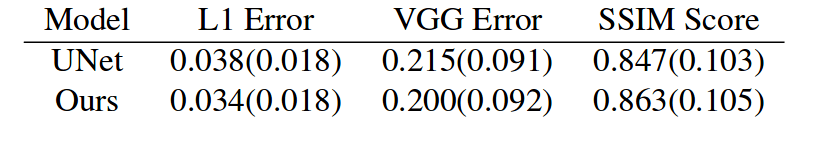


В сухом остатке
Количественные и качественные оценки показывают, что с использованием предлагаемого метода можно создавать реалистичные изображения для разного класса действий. Нейросеть обучается на роликах, показывающих различные классы действий и способна моделировать новые позы для каждого изображения в роликах (например, игрок в гольф оказывается в позе теннисиста). Предлагаемый подход оказался успешным при решении поставленной задачи моделирования поз и является очередной ступенью на пути создания полноценного искусственного интеллекта.







