Создание реалистичных аватаров играет ключевую роль в достижении комфортной коммуникации между людьми в виртуальной среде. Идеальный способ получения реалистичного 3D аватара: человек делает селфи, загружает фото в сеть и получает аватара в виртуальной реальности, который имеет точные черты лица владельца и соответствующее альбедо (отражательная способность поверхности лица). Всё просто. Однако на практике для достижения поставленной цели приходится идти на значительные компромиссы между количеством входных изображений, объёмом вычислений и качеством результата.
Несмотря на сложность задачи, группа исследователей из Технологического Института Южной Калифорнии (USC Institute for Creative Technologies) заявила, что их нейросеть позволяет эффективно создавать точные 3D-текстуры на основе одной фотографии, снятой в произвольном ракурсе. Более того, такие текстуры отличаются высоким качеством исполнения, и при этом не требуют больших вычислительных затрат и работы профессионального фотографа для получения фото.
Приходится идти на компромиссы между количеством входных изображений, объёмом вычислений и качеством результата.
Итак, давайте рассмотрим этот подход к созданию 3D-текстур.
Краткий обзор метода
Нейросеть обучена на датасете из сканов лиц высокого разрешения, которые получены с помощью современных фотометрических систем, снимающих под разными ракурсами. Она позволяет получить карты альбедо и геометрии лица на основе 2D-изображения, которое может быть получено при произвольном освещении и частичном затенении лица. Полученные карты могут быть использованы для отрисовки реалистичного 3D-аватара в других условиях освещения. Весь процесс создания 3D-текстуры занимает всего лишь несколько секунд.
Поставленная задача разбита на несколько частей, каждая из которых решается отдельной свёрточной нейросетью:
- 1-й шаг. Вначале система получает грубую геометрию лица посредством аппроксимации входного изображения 3D-шаблоном. Затем происходит получение из шаблона начальной карты альбедо. Далее используется нейросеть для оценки диффузного и зеркального альбедо и получения карт смещений входного изображения относительно шаблона.
- 2-й шаг. Из-за условий съёмки или частичного затенения лица карты получаются с недостающими областями, поэтому они подаются на вход нейросетей, добавляющих недостающие участки текстур. Высокая точность добавленных текстур достигается с помощью image-to-image translation сетей, в которых особенности изгибов черт лица на скрытых пространствах доворачиваются таким образом, чтобы достичь естественной степени симметрии лица, сохраняя при этом локальные отклонения.
- 3-й шаг. Ещё одна нейросеть используется для прорисовки деталей в дополненных областях.
- 4-й шаг. Свёрточная нейросеть повышает разрешение конечного изображения с 512х512 до 2048х2048.
Рассмотрим структуру предлагаемой модели более детально.
Структура модели в деталях
Схема предлагаемого подхода изображена на картинке внизу. Из одного изображения извлекается базовая сетка лица и соответствующая ей карта текстур. Эта карта пропускается через свёрточные нейросети, которые выдают карты смещений и альбедо. Так как они могут иметь отсутствующие участки, то на следующем шаге производится дорисовка и усовершенствование текстур на основе информации из доступных областей изображения. И наконец, выполняется увеличение разрешения дополненных областей. Полученные карты геометрии и альбедо лица могут быть использованы для создания 3D-текстур в других условиях освещения.
Вывод геометрии и альбедо. Для вывода базовой геометрии лица и ориентации головы применяется алгоритм попиксельной оптимизации. Эти данные используются для создания карты текстур посредством UV-преобразования. Область вне лица удаляется. Далее для получения карт альбедо и смещения извлечённая текстура в RGB палитре передаётся в нейросеть архитектуры U-net с пропущенными соединениями.
Для достижения наилучшего результата применяются две нейросети с идентичной архитектурой: одна работает с диффузной картой альбедо (“подповерхностная” часть), а другая — с тензором, полученным посредством объединения карты зеркального альбедо с картами смещения средних и высоких частот (поверхностные части).
Дополнение текстуры с учетом симметрии. На данном этапе используются два потока нейросети: один поток — для дополнения диффузного альбедо, а другой — для дополнения других составляющих (зеркального альбедо, смещений в средних и высоких частотах).
Было обнаружено, что дополнение больших областей при высоком разрешении изображения не даёт удовлетворительного результата, так как в этом случае возрастает сложность обучения. Поэтому процесс дополнения был разделён на ряд стадий, которые изображены на рисунке ниже.
Более того, исследователи усилили пространственную симметрию UV-параметризации и достигли максимального покрытия особенностей с помощью поворота промежуточных особенностей относительно оси V в UV-плоскости. Это придало конечным текстурам естественную степень асимметрии, характерную для человеческого лица.
Каждая нейросеть была обучена с использованием оптимизатора Adam на скорости обучения 0.0002.
Результаты
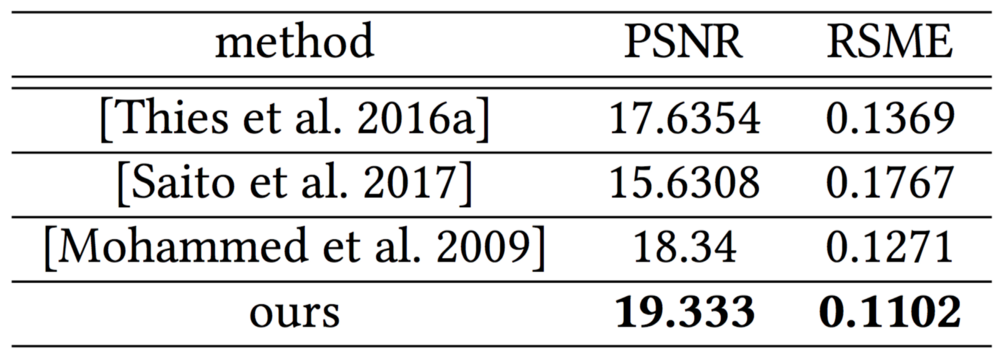
Количественные оценки способности системы восстанавливать альбедо и геометрию лица были сделаны на основе 100 тестовых изображений. Данные оценки представлены в таблице ниже.

Несмотря на то, что мы наблюдаем сравнительно высокое отклонение от реальных значений зеркального альбедо, качественные оценки показывают, что полученные текстуры приемлемы для создания реалистичных и качественных аватаров.
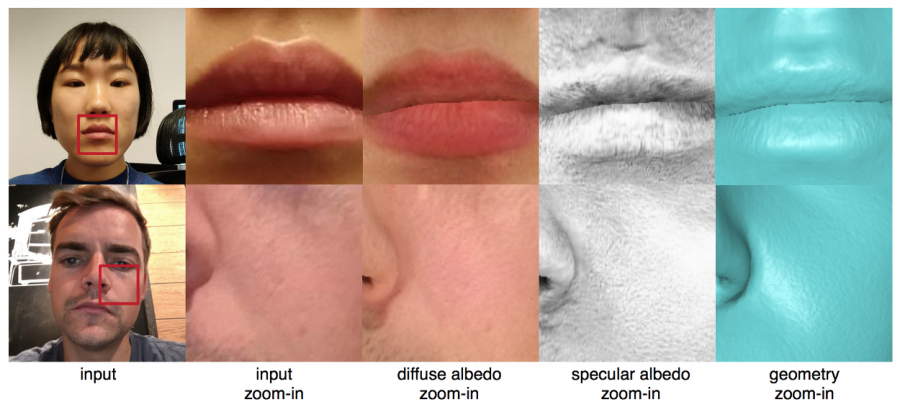
Более того, результаты были приведены в качественное и количественное сравнение с результатами других современных методов. Это сравнение показало, что представленный подход позволяет получить более правдоподобные текстуры лица, чем любой из альтернативных методов.
В сухом остатке
Предлагаемый подход позволяет получить карты геометрии и альбедо лица в высоком разрешении на основе одной фотографии. Конечно, для создания максимально реалистичного аватара требуются не только эти карты, но основное достоинство метода заключается в высокой скорости работы (несколько секунд) в отличие от других методов (несколько минут). Столь выдающиеся результаты достигаются благодаря использованию высококачественных 3D-сканов, используемых для обучения. Более того, поворот и добавление особенностей изгибов черт лица, закодированных в скрытом пространстве, позволили выполнить дополнение текстур с сохранением естественной степени асимметрии.
Тем не менее, предлагаемый подход имеет несколько ограничений, которые продемонстрированы на рисунке выше:
- метод выдаёт артефакты в случае наличия на лице сильного затенения и дополнительных объектов.
- на полученных текстурах не отображается объёмная борода, а морщины могут внести отклонения в получаемые карты смещений.
Ограничения не уменьшают значимости вклада, вносимого рассмотренным методом в создание реалистичных аватаров для виртуальной реальности.
Перевод — Борис Румянцев, оригинал — Kateryna Koidan.