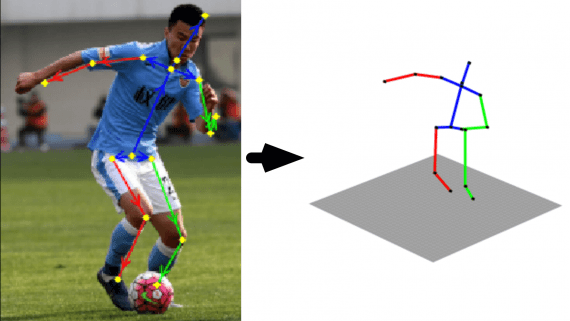
Hugging Face и Pollen Robotics показали Reachy2 — open-source робота для работы по дому
10 июня 2024

Hugging Face и Pollen Robotics показали Reachy2 — open-source робота для работы по дому
Hugging Face и Pollen Robotics представили антропоморфного робота Reachy2, обучающий датасет и модель которого опубликованы в открытом доступе. Reachy2 умеет выполнять домашние обязанности и безопасно взаимодействует с людьми и домашними…