Humans have an incredible capability to imagine things in a different context. At the core of our intelligence are the imagination and learning from experience. Both of these things are connected, and creativity always comes from the memory and our experience. Therefore, we can estimate a shape of an object (even though we look at it only from one particular viewpoint), we can imagine motion or deformation of an object by just looking at it while static. Our memory provides us with the ability to visualize complicated things, such as what will a person see in a different context or different pose.
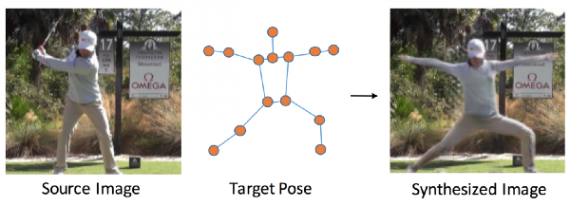
Researchers from Massachusetts Institute of Technology have addressed the Computer vision task of novel human pose synthesis. In their work, they present an image synthesis method that given an image containing a person and a desired, target pose it can synthesise a depiction of the person in that pose in a new realistic model.
They combine multiple techniques, and they frame the novel pose synthesis as a deep learning problem. The approach is unique, and it produces realistic images as they demonstrate in a few different use cases.
Problem Statement
The problem statement: given an image and a target pose synthesise the person in the picture in that pose. From a problem statement point of view, the task of novel human pose synthesis is non-trivial, and there are a few crucial things to be taken into account.
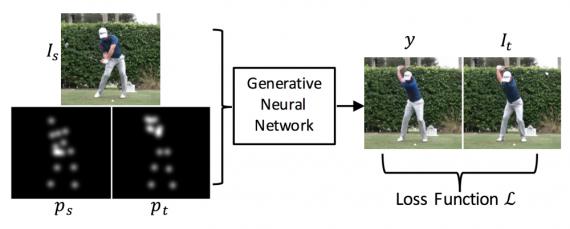
First, the generated image has to be as realistic as possible. Second, changing the pose requires segmenting the person from the background or other objects present in the picture. Third, introducing a novel pose leaves gaps in the background caused by disocclusion which have to be filled appropriately and moreover self-occlusion has to be handled as well.
Capturing these complex changes in the image space represents a challenge and in their approach, the researchers tackle the problem by dividing it into smaller sub-problems, solved by separate modules.
Solution
In fact, they design a modular architecture comprising of several modules to address several different challenges and provide realistic image synthesis in the end. They propose an architecture of 4 modules:
A. Source Image Segmentation
B. Spatial Transformation
C. Foreground Synthesis
D. Background Synthesis
The architecture is trained in a supervised manner mapping a tuple of a source image, source pose and target pose to a target image. The whole architecture is trained jointly using a single model as a target.
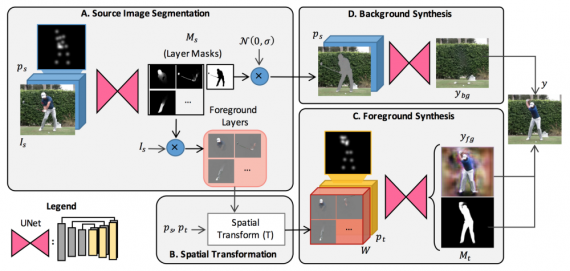
A. Source Image Segmentation
Differences in poses and motion introduced by pose transformation often involve several moving body parts, large displacements, occlusions and self-occlusion. To overcome this problem, the first module is segmenting the source image. The segmentation is two-fold: first, the image is segmented into foreground and background, then the foreground (the person) is segmented into body parts such as arms, legs etc. Therefore, in the output of the segmentation stage, there are 1 background layer and L foreground layers corresponding to each of the L predefined body parts.
As mentioned before, a tuple of the input image along with the pose and the desired target pose is given as input. Unlike the source image which is an RGB image, the poses are defined as a stack of multiple layers. A pose is represented as a 3D volume given in R(HxWxJ). Each of the J layers (or channels) in the pose representation contains a “Gaussian bump” centred at the (x,y) location of each joint. The Gaussian representation (instead of deterministic dense representation) introduces some kind of regularization since joint location estimates can be often noisy and incorrect. In the experiments, the authors use 14 body parts (head, neck, shoulders, elbows, wrists, hips, knees and ankles) as 14 channels.
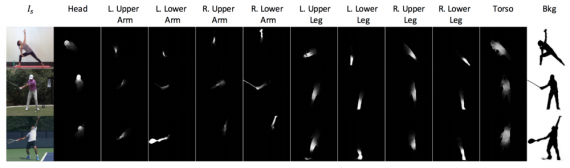
The segmentation module is a U-Net network, that takes a concatenated volume (of the input image plus the pose layers) as input and gives L layer masks as output, specifying the rough location of each joint. The output is, in fact, 2D Gaussian mask over the approximate spatial region of each body part that enables to obtain the desired segmentation.
B. Spatial Transformation
The segmented layers from the segmentation module are then spatially transformed to fit the desired pose parts. The spatial transformation is not learned but directly computed from the input poses.
C. Foreground Synthesis
The foreground synthesis module is again a U-shape network (Encoder-decoder with skip connections) that takes the spatially transformed layers with the target pose layers as a concatenated volume and it outputs two different outputs (by branching the end of the network) — the first one being the target foreground and the second one being the target mask.
D. Background Synthesis
The task that the background synthesis module is solving is filling the background that is missing i.e. that is being occluded by the person in the input image. This module is also a U-net taking a volume of the input image (alongside with Gaussian noise in place of the foreground pixels) and the input pose mask. It outputs a realistic background without the foreground (the person in the image).
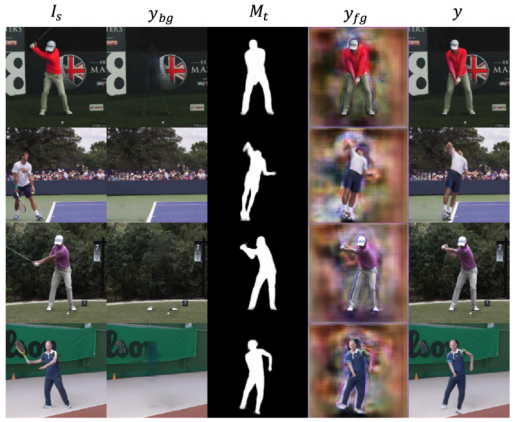
Image Synthesis
Finally, the target background and foreground images are fused by a weighted linear sum taking into account the target mask (see formula below):
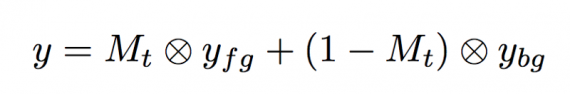
As in many generative models recently, the researchers propose an adversarial discriminator to force the generation of realistic images. In fact, the generative model was trained using L1 loss, a feature-wise Loss (denoted L-VGG ) and finally a combined L-VGG + GAN loss using binary cross-entropy classification error of the discriminator.

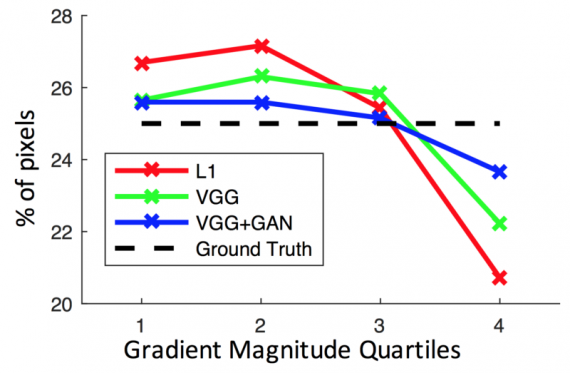
Evaluation
The method was evaluated using videos of people performing actions collected from YouTube. The experiments were done using videos from three action classes: golf swings, yoga/workout routines, and tennis actions having a dataset of sizes 136, 60 and 70 videos, respectively. Simple data augmentation is also used to increase the size of the dataset.


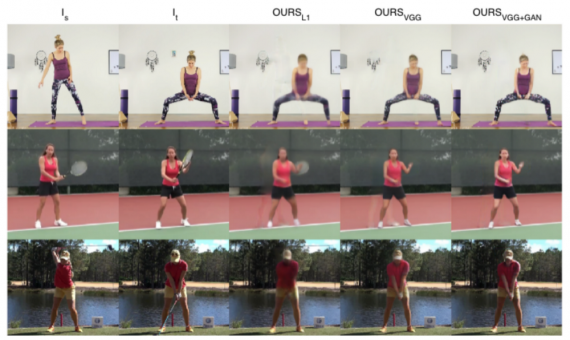
Bottom line
The evaluation shows that the method is capable of synthesizing realistic images across different action classes. Though trained on pairs of images within the same video, the method can generalize to pose-appearance combinations that it has never seen (e.g., a golfer in a tennis player’s pose). The decoupling approach proved successful in this non-trivial task, and it shows that tackling a problem by dividing it into sub-problems can give outstanding results despite the complexity of the problem itself.