
Исследователи из Udacity разработали нейросеть LumièreNet, которая на основе аудиоклипов синтезирует видеолекции в высоком разрешении. Примеры сгенерированных видеозаписей находятся по ссылкам: первый пример, второй пример.
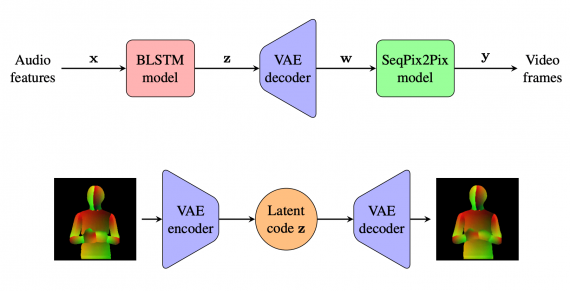
В отличие от предшествующих моделей, LumièreNet полностью состоит из обучаемых нейросетевых модулей, которые конвертируют аудио в видео через скрытые коды и модуль с сохранением позы человека.
Архитектура нейросети
Предложенная модель состоит из трех нейросетевых модулей:
- BLSTM модель, которая ассоциирует полученные из аудио характеристики с скрытыми кодами;
- VAE модель, которая предсказывает позу человека по скрытым кодам из BLSTM;
- SeqPix2Pix модель, которая генерирует видеокадры на основе поз, которые были получены из VAE
Во время обучения LumièreNet использует VAE модель, чтобы сгенерировать скрытые изображения поз человека с помощью кодировщика и декодировщика. Чтобы предсказывать позу лектора, исследователи использовали существующий фреймворк DensePose. SeqPix2Pix, которую предлагают исследователи, — это модификация Pix2Pix архитектуры. SeqPix2Pix использует генеративную нейросеть, чтобы выучить сопоставление между аудиоданными и видеокадрами.
Исследователи записали четырехчасовую лекцию и использовали ее для обучения нейросети. В видеозаписи лектора не перезаписывали после оговорок или иных мелких ошибок. Это необходимо было, чтобы видеозапись была максимально приближена к реальной записи видеолекции. Видео записали на 30 кадров в секунду и поделили на блоки по 3-4 минуты. Для обучения использовался 1 кадр на каждую секунду видео.
Проверка работы модели
Чтобы проверить, насколько предложенная модель сравнима с базовыми моделями, исследователи качественно и количественно сравнили результаты. В качестве базовых моделей — функция потерь стандартной GAN и то же с добавлением ограничения на консистентность структуры изображения.
Видно, что SeqPix2Pix справляется лучше как и в случае качественного сравнения результатов, так и в случае количественной оценки.











