Плохо умеете танцевать? Больше не проблема! Удивите своих друзей ошеломляющим видео, где вы танцуете, как суперзвезда. Исследователи предложили новый способ motion trasfer для видео. Они утверждают, что способны перенести исполнение танца с исходного видео на целевое всего за несколько минут.
Предыдущие работы
За последние два десятилетия motion transfer (трансфер или ретаргетинг движений) привлек значительное внимание со стороны исследователей. Ранние подходы заключались в создании нового видеоматериала путем манипулирования существующими.
- Video Rewrite подход, предложенный Крисом Бреглером и его коллегами в 1997, создает видео, где человек говорит фразу, которую он не произносил в оригинале, путем обработки кадров и поиска тех положений губ, которые необходимы для целевой речи.
- Метод Эфроса и Берга представленном в 2003, который использует оптический поток, как описатель, сопоставляющий одинаковые действия разным объектам, позволяя делать “Делай, как я”, “Говори, как я” ретаргетинг.
- Другой подход может быть реализован посредством 3D трансфера движений для графики и анимации. Недавно, Виллегас и коллеги продемонстрировали, как техники глубокого обучения могут помочь с ретаргетингом движений без размеченных данных
- Самые совершенные на данный момент методы может успешно генерировать детальное изображения человека в новых позах (в частности Метод Джу для генерации движущегося изображения)
- Более того, такие изображения могут быть получены для временной согласованности видео и предсказания.
Так какая же идея лежит за новым подходом?
State-of-the-art идея
Исследователи поставили перед собой задачу покадрового преобразования изображений с пространственно-временным сглаживанием. Обнаружение позы представленно палочным скелетом, как промежуточное представление между источником и целью. Supervised обучение происходит на основе переноса движений со скелета на целевого персонажа.
Два дополнительных компонента улучшают результаты:
- условное предсказание в каждом кадре в сравнении с предыдущим шагом для временной гладкости;
- специализированной GAN для реалистичного синтеза лица.
Прежде чем погрузиться в архитектуру предлагаемого подхода, давайте проверим результаты с помощью этого короткого видео:
По существу, модель обучается производству персонализированных видеороликов для определенного целевого объекта. Трансфер движения происходит, когда на скелет из обученной модели «надевают» оболочку цели, чтобы получить аналогичную оригиналу позу.
Метод
Предлагаемый метод состоит из 3 частей:
- Обнаружение позы — с использованием предобученного современного детектора позы для скелета из исходного видео.
- Глобальная нормализация позы — учет различий между источником и целевыми объектами в фигурах и местоположении в кадре.
- Сопоставление нормализованных скелетов и целевого объекта.
Ниже приведен обзор метода:
-

Обзор метода
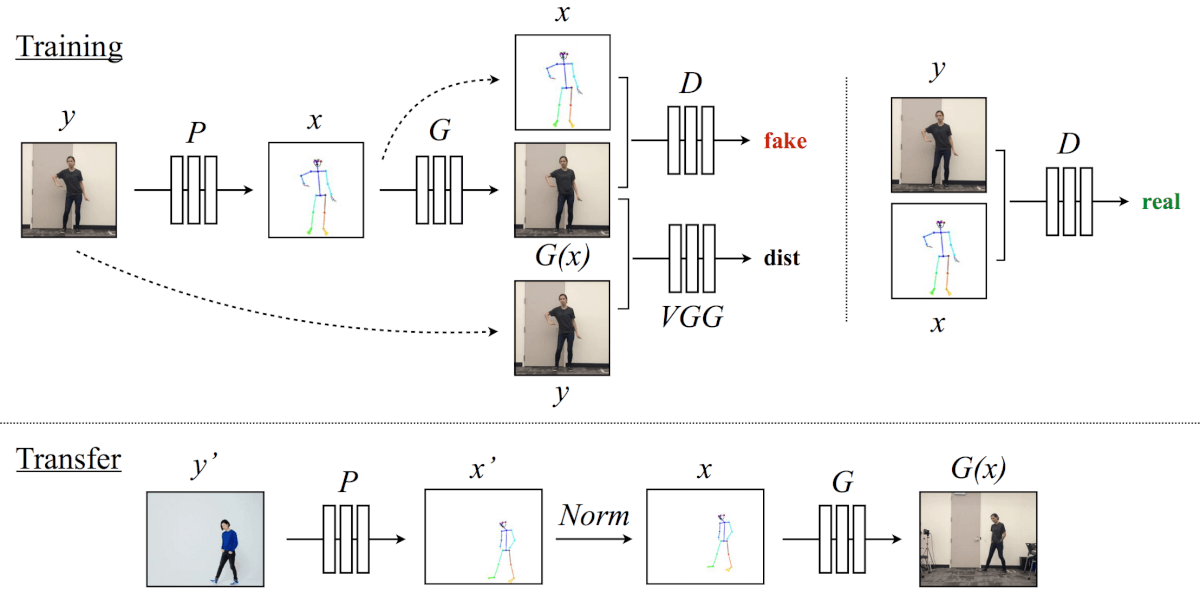
Для обучения модель использует детектор позы P для создания скелета из видеокадров целевого объекта. Тогда отображение G обучается вместе с состязательным дискриминатором D, который пытается отличить «реальную» пару соответствий (x, y) и «поддельную» пару (G (x), y).
Далее, для передачи, детектор позы P помогает получить стыковые суставы для источника. Затем они преобразуются с нормализацией процесса Norm в суставы для цели, для которой создается скелет. Наконец, применяется обученное отображение G.
Исследователи основывают свой метод на задаче, представленной в pix2pixHD, с некоторыми расширениями для создания временной согласованности видеокадров и генерации реалистичных изображений лица.
Временное сглаживание
Чтобы создать видеоряд, они модифицируют генерацию одного изображения, чтобы обеспечить временную согласованность между соседними кадрами, как показано на рисунке ниже:
-
Настройка временного сглаживания
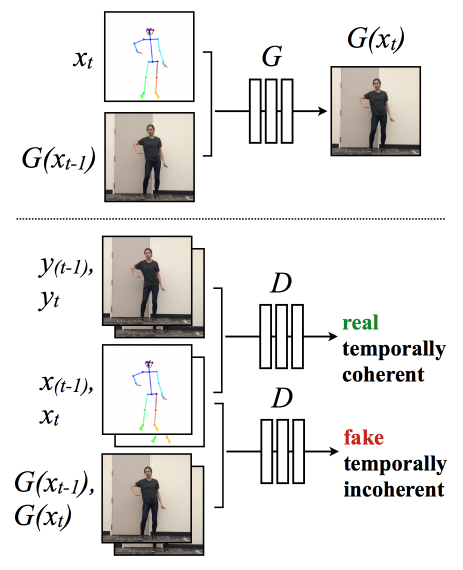
Проще говоря, текущий кадр G (xt) обусловлен его соответствующим скелетом xt и ранее синтезированным кадром G (xt-1) для получения гладкой картинки на выходе. Дискриминатор D затем пытается дифференцировать «реальную» временную согласованность последовательность (xt-1, xt, yt-1, yt) из «поддельной» последовательности (xt-1, xt, G (xt-1), G (xt) ).
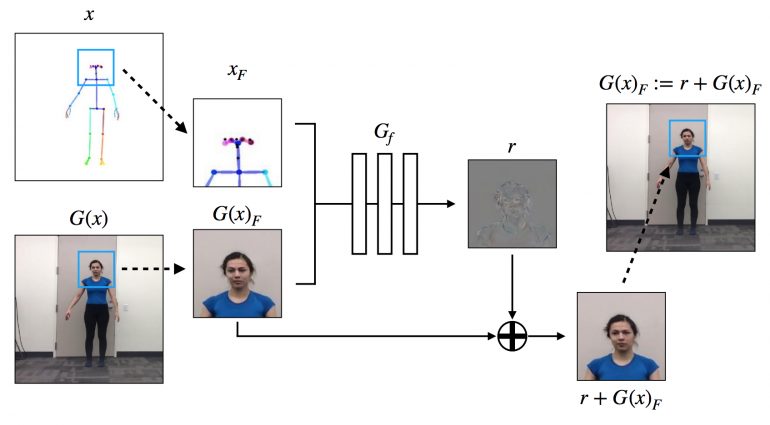
Настройка FaceGAN
Исследователи дополнительно расширяют модель с помощью специальной настройки GAN, предназначенной для добавления деталей и реализма лица, как показано на рисунке ниже. А точнее, модель использует один дискриминатор 70 × 70 Patch-GAN для дискриминатора лица.
Теперь перейдем к результатам экспериментов …
Результаты
Целевые объекты записывались в течение 20 минут в режиме реального времени со скоростью 120 кадров в секунду. Кроме того, учитывая, что сеть не кодирует информацию об одежде, целевые танцоры носят туго натянутую одежду с минимальным складками.
Видео с источниками было найдено онлайн — это видео высокого качества, на которых исполняется танец.
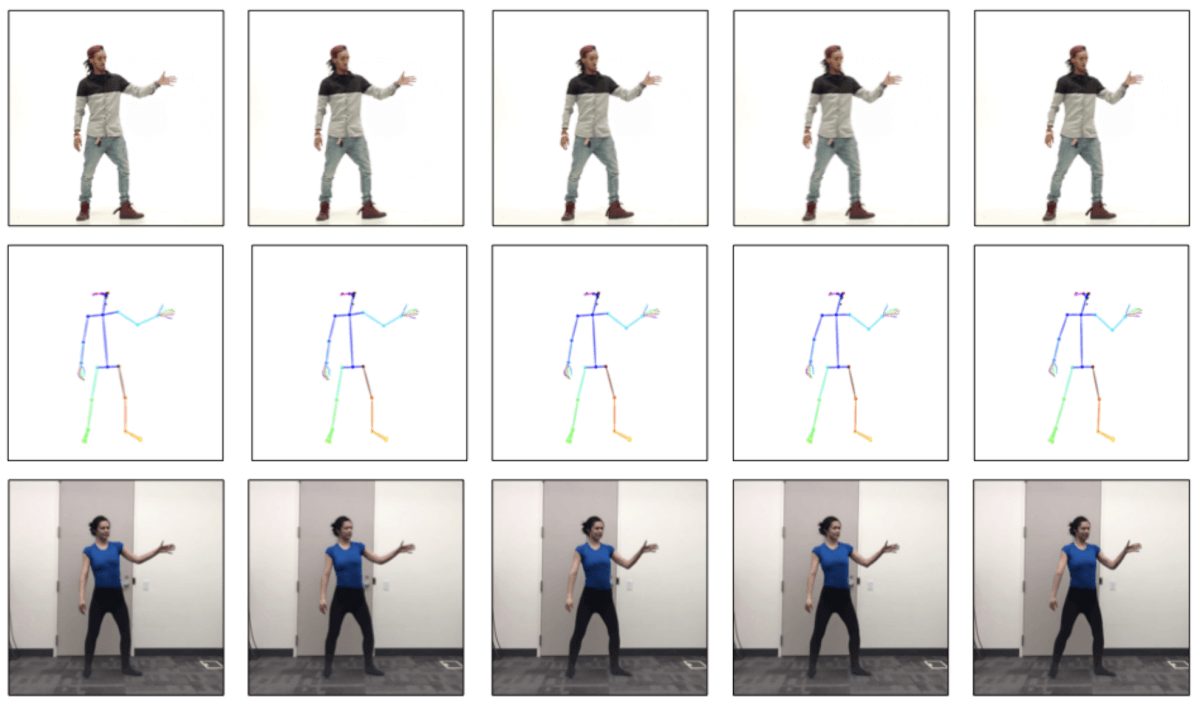
Ниже приведены результаты, где верхняя строка показывает объект-источник, средняя показывает нормализованные скелеты, а нижняя отображает выходные данные модели:
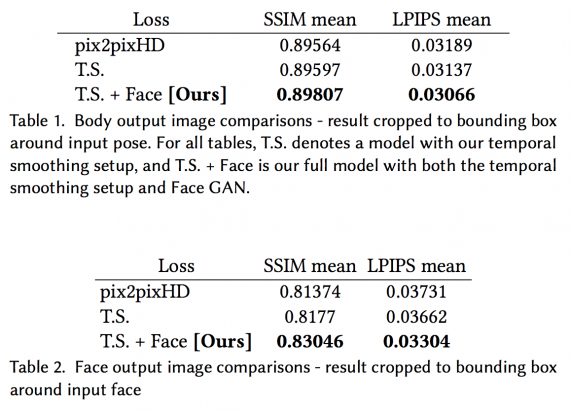
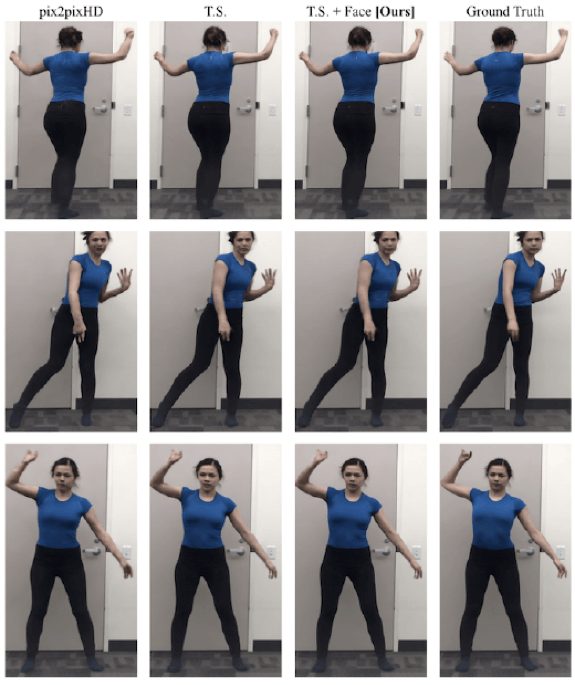
В приведенных ниже таблицах показаны результаты полной модели (с временным сглаживанием и настройками FaceGAN) по сравнению с базовой моделью (pix2pixHD) и базовой моделью с настройкой временного сглаживания. Качество отдельных кадров оценивалось с помощью измерения Structural Similarity (SSIM) и Learned Perceptual Image Patch Similarity (LPIPS).
-
разных моделей (T.S .: модель с временным сглаживанием, T.S. + Face: полная модель с настройкой временного сглаживания и FaceGAN)»> Сравнение результатов синтеза для разных моделей (T.S .: модель с временным сглаживанием, T.S. + Face: полная модель с настройкой временного сглаживания и FaceGAN)
Чтобы дополнительно проанализировать качество результатов, исследователи запускают детектор позы P на выходах каждой модели и сравнивают полученные ключевые точки с позой исходного видео. Если все части тела синтезированы правильно, то реконструированная поза должна быть похожа на исходную позу. См. Результаты в таблицах ниже:
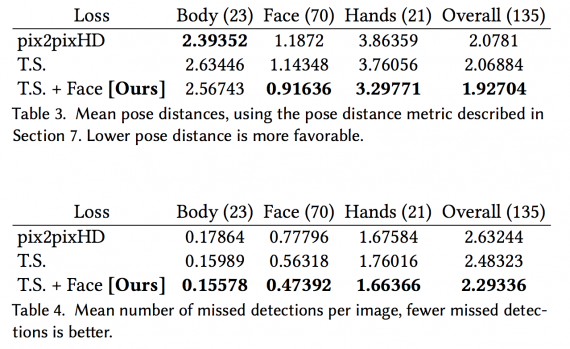
Как видно из таблиц, временная сглаживающая настройка, похоже, не добавляет значительных результатов в baseline, если смотреть только на количественные результаты. Однако временная сглаживающая настройка помогает с плавными движениями, согласованностью цветов по кадрам, а также в индивидуальном синтезе кадров.
С другой стороны, настройка FaceGAN улучшает как количественные, так и качественные результаты модели. Как видно из приведенных ниже рисунков, этот компонент добавляет значительную детализацию к выходному видео и обеспечивает реалистичную генерацию частей тела.
-
Сравнение изображений лиц, полученных различными моделями, в наборе валидации

Вывод
Представленная модель способна создавать реалистичные и достаточно длинные видеоролики человека, осуществляющего танцевальные движения, которые есть на видео-источнике. Однако результаты по-прежнему часто страдают от дрожания. Это особенно характерно, когда перемещение или скорость перемещения отличаются от движений, наблюдаемых во время обучения.
Учитывая, что дрожь остается, даже если человек пытается скопировать движения объекта-источника на тренировочных данных, исследователи полагают, что дрожание может также возникнуть из-за разницы между тем, как движутся исходный и целевой объекты с учетом их уникальных структур тела. Тем не менее, этот подход к трансферу движения уже способен генерировать привлекательные видеоролики на разных данных.
Может быть интересно:
- Нейросеть распознает фейковые видео с 99% точностью
- Перенос стиля для видео
- Сегментация объектов на видео в реальном времени