
Создание реалистичных, похожих на настоящих людей персонажей — важная задача компьютерной анимации. Анимация персонажей применяется в создании мультфильмов, компьютерных игр, спецэффектов в кино и виртуальной реальности.
Ранние работы
Анимация персонажей — сложная задача со множеством этапов. Автоматизация части этапов могла бы упростить и ускорить этот процесс.
Первые попытки автоматизации были сосредоточены на понимании физики и биомеханики и пытались сформулировать и воспроизвести модели движения для виртуальных персонажей. Совсем недавно стали изучаться подходы, ориентированные на работу с данными. Однако большинство таких подходов основано на захвате движения, что часто требует дорогостоящих инструментов и сложной предварительной обработки.
Новая идея
Недавно исследователи из Berkeley AI Research в Калифорнийском университете предложили новый подход, основанный на обучении с подкреплением, для обучения персонажей движениям из видео.
Сочетая оценку движений из видео и глубокое обучение с подкреплением, метод способен перенести движения из видео на анимационного персонажа. Кроме того, предлагаемый способ способен предсказать движение человека по неподвижным изображениям путем прямого моделирования обучающих контроллеров.
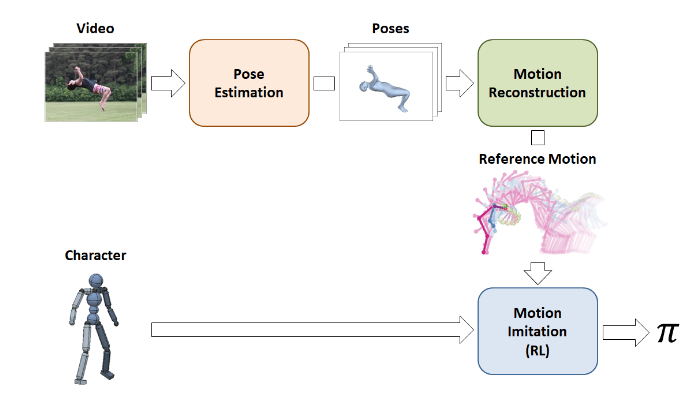
Метод
Исследователи предложили фреймворк, который принимает на вход видео и моделирует персонажа, имитирующего движение. Подход основан на оценке позы в кадрах видео, которая позднее используется для восстановления движения и его имитации.
Входное видео обрабатывается на этапе оценки позы, где для оценки позы актера в каждом кадре применяются вычисленные оценки 2D и 3D позы. Далее, множество предложенных поз отправляется на этап восстановления движения, где опорная траектория движения оптимизирована таким образом, что она согласуется как с 2D, так и с и 3D предсказаниями позы и соблюдает временное соответствие между кадрами. Опорное движение затем используется на этапе имитации движения, где происходит обучение для того, чтобы движение персонажа воспроизводило опорное движение в моделируемой среде.
Этап оценки позы
Первым шагом в схеме является этап оценки позы. На этом этапе целью является оценка позы по одному неподвижному изображению, то есть по каждому кадру видео. На данном этапе необходимо решить ряд проблем, чтобы получить точную оценку позы. Во-первых, изменчивость положения тела у разных людей, выполняющих одно и то же движение, очень высока. Во-вторых, оценка позы должна выполняться в каждом кадре независимо от предыдущего или следующего кадров без учета временной согласованности.
Чтобы решить обе проблемы, исследователи предлагают использовать проверенные методы оценки позы и простой метод аугментации данных для улучшения предсказаний позы при выполнении акробатических движений.
Ученые обучили модель на расширенном датасете и получили оценки 2D и 3D позы для каждого кадра, которые определяют 2D и 3D траектории движения.

Этап восстановления движения
На этапе восстановления движения независимые предсказания сводятся к окончательному эталонному движению. Конечной целью этапа является улучшение качества опорных движений путем исправления ошибок и удаления артефактов движения, проявляющихся как нефизическое поведение. По мнению исследователей, эти артефакты движения возникают из-за несогласованных предсказаний в соседних кадрах.
Опять же, на этом этапе применяется метод оптимизации общей траектории трехмерной позы для оценки позы и обеспечения временной согласованности между последовательными кадрами. Оптимизация выполняется в скрытом слое с использованием архитектуры энкодер-декодер.
Этап имитации движения
На заключительном этапе применяется глубокое обучение с подкреплением. С точки зрения машинного обучения цель — обучить сеть так, чтобы персонаж воспроизводил движения. Исходное движение, извлеченное ранее, используется для определения целевого результата моделирования, и затем проводится подготовка метода для имитации данного движения.
Для улучшения работы метода вводится функция вознаграждения, которая стимулирует персонажа лучше отслеживать отличие совокупности вращений частей тела при движении от эталонного. Фактически, происходит вычисление кватернионных различий между вращением сустава персонажа и совместными вращениями выделенного эталонного движения.

Результаты
Чтобы продемонстрировать работу фреймворка и оценить предложенный метод, исследователи используют трехмерного человекоподобного персонажа и смоделированного робота Atlas. Качественная оценка выполнили, сравнивая снимки персонажей с оригинальными видео. Все видеоролики были собраны с YouTube. На них изображены люди, выполняющие различные акробатические движения. Определить количественную разницу между движем человека и персонажа трудно, поэтому производительность метода оценивалась по отношению к извлеченному опорному движению. На рисунках ниже приведены кадры реальных видеороликов и кадры с персонажами для качественной оценки.


Выводы
Предлагаемый подход показывает хорошие результаты для переноса анимации из одного входящего видео. Объединение методов оценки позы, восстановления позы и обучения с подкреплением позволяет перенести движения на персонажа с высокой точностью. В работе показаны преимущества модульной конструкции. Улучшения, которые относятся к разным этапам, можно включить на более поздних этапах для повышения эффективности работы всего фреймворка.








