Функции активации нейросети: сигмоида, линейная, ступенчатая, ReLu, tahn
29 ноября 2018

Функции активации нейросети: сигмоида, линейная, ступенчатая, ReLu, tahn
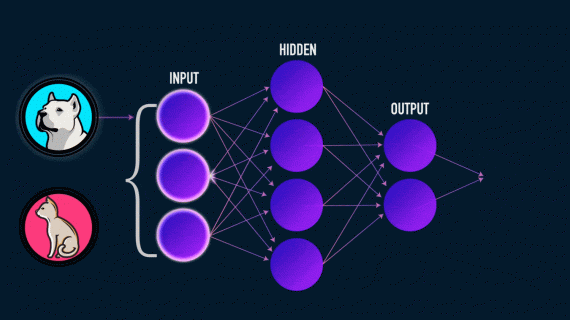
Что делает искусственный нейрон? Простыми словами, он считает взвешенную сумму на своих входах, добавляет смещение (bias) и решает, следует это значение исключать или использовать дальше (да, функция активации так и…