Point-E: нейросеть для создания облаков точек от OpenAI
21 декабря 2022
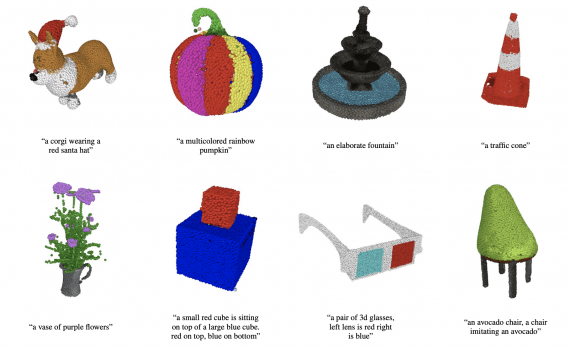
Point-E: нейросеть для создания облаков точек от OpenAI
Исследователи OpenAI опубликовали новую модель для генерации 3D-объектов POINT-E, с помощью которой облака точек создаются на основе текстовых подсказок. Новый метод не превосходит state-of-the-art модели с точки зрения качества создаваемых…

