Как предсказать то, что скрыто? Исследователи из Google предложили любопытный подход к рендерингу трехмерного пространства (оценки глубины сцены) по одному 2D изображению, основанный на многоуровневом обучении. Цель — получить информацию о текстурах окклюдированных (невидимых) частях изображения и о расстоянии до них.
Чтобы решить главную проблему — недостаток тренировочных данных исследователи опирались на multi-view подход, который позволил изучить многоуровневое представление 3D сцены. Они использовали представление, известное как многослойное изображение глубины (англ. layered depth image — LDI), и предложенный метод позволяет построить такое представление трехмерного пространства из одного данного изображения

Читайте также: Оценка глубины при помощи encoder-decoder сетей
Большинство соверменных методов предсказывают одно значение глубины на писксель (расстояние до пикселя) на видео и изображениях. В отличие от этих подходов, цель исследователей — получить представление с информацией о нескольких слоях. Таким образом, один пиксель изображения содержит несколько значений глубины, что и позволяет сделать представление LDI.
Метод
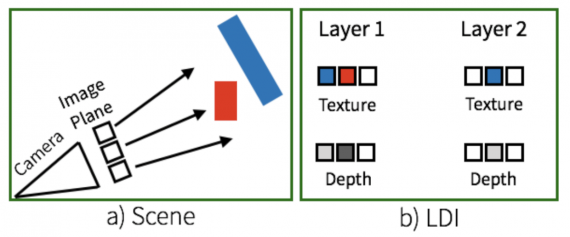
3D-рендеринг изображения предскаывает ту часть пространства, которая не видна с имеющейся точки наблюдения (т. е. закрыта объектами), для этого определяют его окклюзивную часть. Карты глубины отвечает на вопрос: «насколько далеко от камеры находится точка на этом пикселе?». Представление LDI отвечает также на вопрос: «что скрывается за видимым содержимым пикселя?», что еще больше увеличивает ценность метода, позволяя выходить за пределы прогноза в 2.5D.

Датасет
Представление LDI специфично и представляет собой трехмерную структуру в виде слоев глубины и цветных слоев. Cлои 3D-пространства определяются поверхностью, т. е. видимой частью с точки зрения камеры. Изображение LDI содержит L кортежей цветных (texture) и глубинных (depth) слоев (см. рисунок ниже).

Для обучения сети исследователи использовали датасет, который состоит из N пар изображений, каждое из которых представлено исходным и целевым изображениями (Is, It), внутренними характеристиками камеры (Ks, Kt), а также хакарактеристиками камеры — углом поворота и вносимыми преобразования (R , t).
Синтез представлений как сигнал контроля
Имея исходное изображение Is, метод вычисляет представление LDI при помощи сверточной нейронной сети. Сигнал контроля поступает с целевого изображения (плоского изображения с другого ракурса). С учетом оценки LDI и точки обзора данные обощаются и приводятся к соответствию между целевым и визуализированным изображениями.
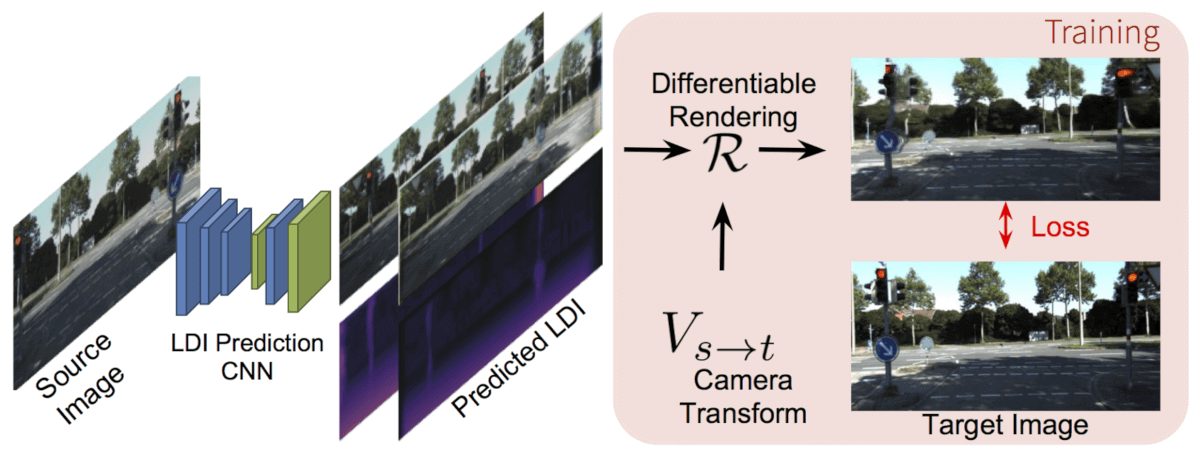
Рендеринг изображения выполняется с использованием геометрически определенной функции рендеринга и преобразованием камеры (метод предполагает, что оно заранее известно). Для рендеринга изображение LDI рассматривается как текстурированное облако точек. Затем каждая точка источника проецируется на целевой кадр. После этого окклюзия обрабатывается «мягким z-буфером» для отображения целевого образа на средневзвешенное значение цветов проецируемых точек.
Архитектура сети
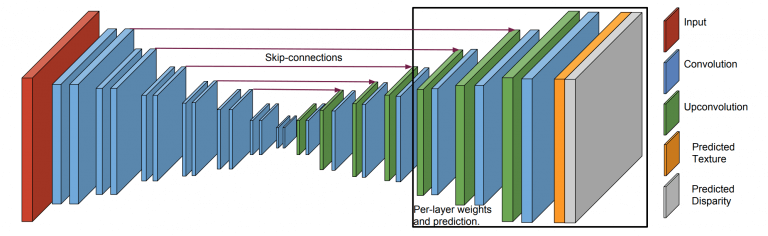
Архитектура сети, используемая для оценки LDI, представляет собой сверточную сеть DispNet, которая по цветному изображению вычисляет пространственные функции при различных разрешениях и производит декодировку к исходному разрешению. Пропущенные соединения также добавляется в сеть. Чтобы использовать тот факт, что не все слои получают одинаковый обучающий сигнал, авторы добавляют отдельные блоки предсказания (последняя часть сети) для каждого слоя. Цель обучения — получить схожесть исходного и целевого изображений с заданной точки наблюдения.
Оценки и выводы
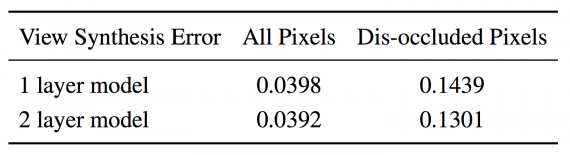
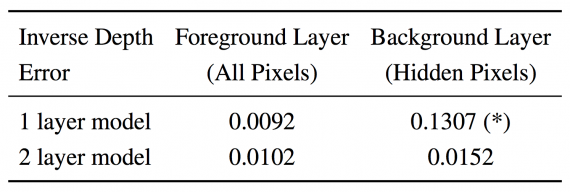
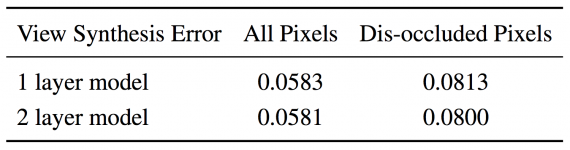
Для оценки разработанного метода исследователи использовали как искусственные данные, так и датасет с реального вождения автомобиля. Оценивая отдельные модули и решение в целом как количественно, так и качественно, ученые заключают, что данный способ успешно описывает окклюдированное пространство.

Хотя мы все еще далеки от полного восстановления трехмерного пространства, рассмотренный способ доказал, что методы глубокого обучения могут быть успешно применены для 3D-рендеринга (даже по одному изображению). Метод выходит за рамки 2.5D-рендеринга, расширяя наши представления об обработке изображений.
Код на Гитхаб — https://shubhtuls.github.io/lsi/