От современных автономных мобильных роботов, например, беспилотных автомобилей, требуется глубокое понимание окружения. Полнота и точность модели окружающей среды играют ключевую роль для безопасности и эффективности работы.
Камеры или датчики?
В то время как датчики, такие как LIDAR, Radar, Kinect предоставляют 3D-данные, включая все пространственные размеры, камеры обеспечивают только двумерный вид окружающего. Ранее было сделано много попыток извлечь 3D-данные из 2D-изображений, поступающих с камеры. Зрительная система человека удивительно успешна в решении этой задачи, в то время как алгоритмы часто ошибаются при восстановлении карты глубины изображения.
В новом подходе предлагается использовать глубинное обучение самоконтролируемым (self-supervised) образом для оценки монокулярной глубины. Исследователи из Лондонского университетского колледжа разработали архитектуру для оценки карты глубины, которая превосходит текущую современную (state-of-the-art) оценку глубины на наборе данных KITTI. Утверждая, что больших и разнообразных наборов размеченных данных для обучения недостаточно, они предлагают подход, основанный на самоконтроле с использованием монокулярных видеороликов. Их подход к оценке карты глубины работает одинаково хорошо как с монокулярными видео данными, так и со стереопарами (синхронизированные пары данных со стерео камеры) или даже их комбинацией.

Метод оценки глубины
Простой способ решения проблемы оценки глубины с точки зрения deep learning заключается в обучении сети с использованием размеченных данных, а именно карт глубины в качестве меток. Однако получение достаточного количества размеченных данных (в данном случае пар 2D-3D-данных) для обучения большой и глубокой сети представляет собой проблему. Как следствие, авторы исследуют самостоятельный (self-supervised) подход к обучению. Они рассматривают проблему как синтез представлений (view-synthesis), где сеть учится предсказывать целевое изображение с точки зрения другого. Предложенный метод способен дать оценку глубины, учитывая только лишь цвета на изображении.
Важной проблемой, которую необходимо учитывать при оценке глубины, является ego-motion (3D движение камеры в среде). Оценка эго-движения имеет решающее значение для получения хороших результатов. Чтобы компенсировать эго-движение, существующие подходы имеют отдельную сеть оценки позиционирования робота. Задача этой сети состоит в том, чтобы оценить относительное изменение положения камеры между последовательными измерениями датчика.
Архитектура сети
В отличие от ранее современных подходов, которые используют отдельную сеть для оценки положения камеры помимо сети для оценки глубины, новый метод использует кодирующую часть сети (encoder) оценки глубины в качестве трансформера (transformer) в сети для оценки положения.
Сеть, оценивающая положение (на рисунке ниже) объединяет признаки, полученные от кодировщика, вместо объединения необработанных данных. Авторы утверждают, что это значительно улучшает результаты оценки положения при одновременном сокращении числа настраиваемых параметров. Они утверждают, что это происходит из-за абстрактных особенностей кодировщика, которые несут важное понимание геометрии входных изображений. Сеть для оценки глубины, предложенная в этой статье, основана на архитектуре U-net (encoder-decoder U-образной сети со skip connections) и функцией активации ELU вместе с сигмоидами. Кодировщик (encoder) в сети является предварительно обученным ResNet 18.
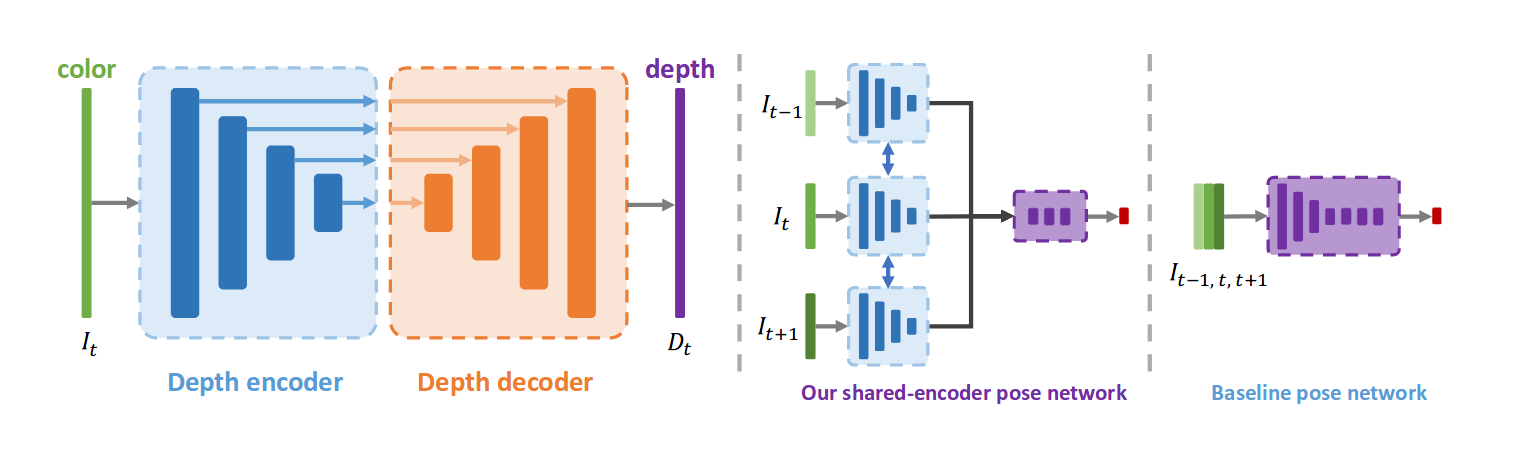
Помимо новой архитектуры было предложено несколько улучшений. Во-первых, авторы используют специально разработанную функцию потерь, включающую как L1, так и SSIM (индекс структурного сходства). Во-вторых, представили интересный подход; они вычисляют фотометрическую ошибку изображения с более высоким разрешением путем up-sampling карты глубины изображения с низким разрешением. Интуитивно это позволяет избежать проблемы получения “дыр” в некоторых частях изображения из-за вычислительных ошибок при down-sampling карты глубины. Наконец, они добавляют сглаживающий член к своей функции потерь.
Эксперименты
Сеть реализована на Pytorch и обучена с использованием набора данных KITTI (разрешение входного изображения 128 x 416). Размер выборки около 39 000 триплетов для обучения и тестирования, а аугментация широко использована в виде горизонтального зеркального отображения, изменения яркости, контраста, насыщенности и так далее. Некоторые из полученных результатов приведены в таблице ниже
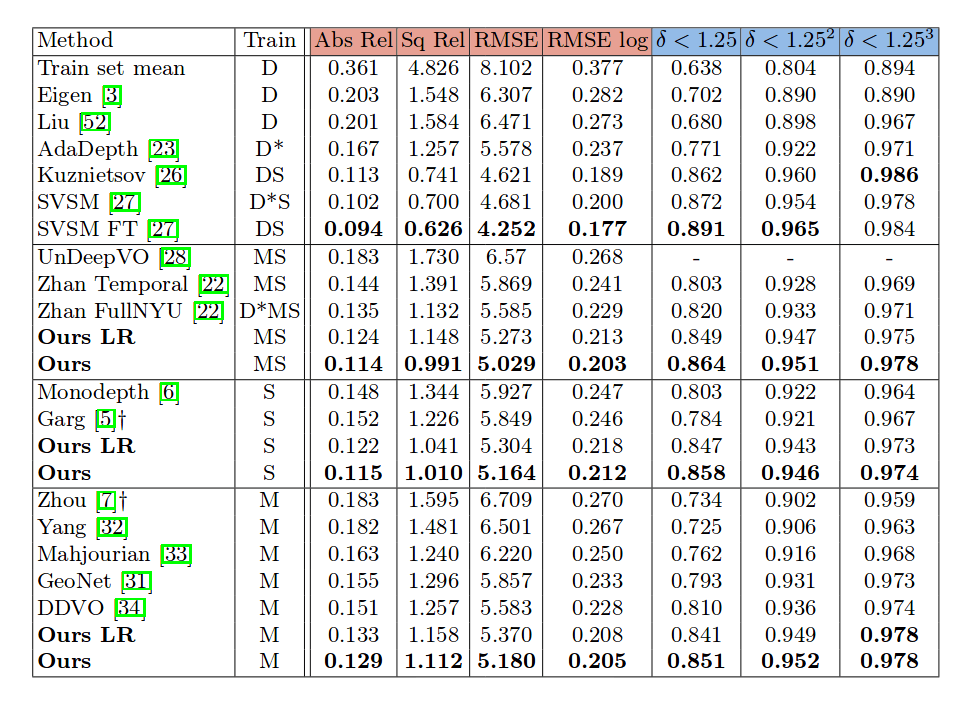
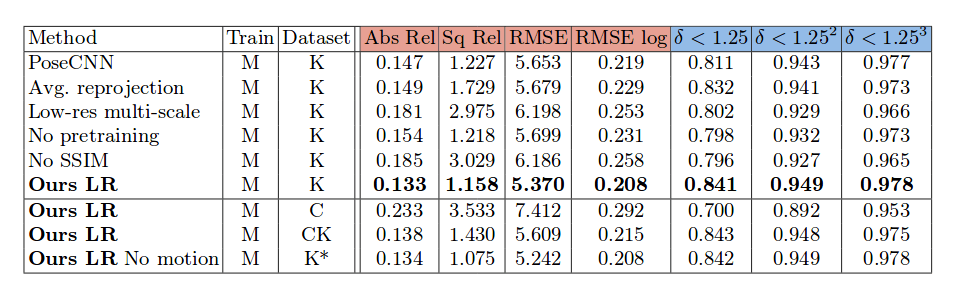
Подход показывает многообещающие результаты в оценке глубины изображений. 3D оценка глубины получает все больше и больше внимания, что поднимает вопрос, действительно ли у нас есть потребность в 3D-датчиках (часто дорогостоящих и сложных). Точная оценка глубины может иметь много приложений: от простого редактирования до полного понимания изображений. И последнее, но не менее важное: этот подход вновь подтверждает мощь глубокого обучения, особенно силу сверточных encoder-decoder сетей в широком спектре задач.