Microsoft ViSNet: предсказание активности молекул
3 марта 2024
Microsoft ViSNet: предсказание активности молекул
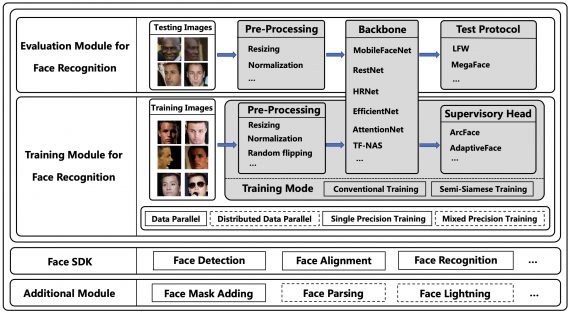
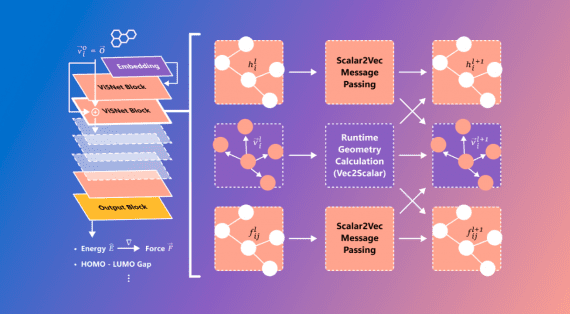
Microsoft опубликовала ViSNet – графовую нейросеть, моделирующую геометрию сложных молекул для предсказания их активности. ViSNet может значительно ускорить поиск и изучение новых лекарств. Моделирование молекулярной геометрии позволяет предсказывать, как молекулярные…