С тех пор как Джерри Ли, автор этой статьи, начал смотреть аниме, одна мысль не давала ему покоя: он просто не умеет рисовать. После многочисленных попыток, которые закончились “уничтожением” любимых персонажей, он сдался… пока не начал заниматься машинным обучением. В наше время ИИ играет в “go” (хорошо), управляет машинами (не очень хорошо), пишет стихи, которые никто не понимает, даже кажется возможным одолжить ему кисточку и надеяться, что он что-то сделает. Как же превратить все человеческие портреты в персонажей аниме с помощью ИИ? С помощью TwinGAN, это последний проект автора.
На самом деле было много попыток научить ИИ рисовать. Автор представил два из них в прошлом: Neural Style Transfer и раскрашивание эскиза с использованием Generative Adversarial Networks(GAN), оба из которых тесно связаны с этим проектом.
Neural Style Transfer
Проще говоря, Style transfer — это перенос стиля одного изображения на другое. Стиль включает мазки кисти, выбор цвета, света и тени, объект, к которому применяется стиль. После того как Gatys изобрел метод переноса стиля с использованием нейронных сетей в 2015 году, возникла проблема, которая пугает некоторых исследователей.

Neural style transfer требует предварительно обученной сети для сегментации, а большинство таких сетей обучаются на реальных объектах. Таким образом, когда дело доходит до стилей, которые придают объектам реальной жизни совсем другой вид — например, удлиненные ноги, огромные глаза и вообще почти всё, что вы можете получить от аниме-изображения — neural style работает не очень хорошо.
Есть одно простое решение: деньги. Попросите кого-то пометить все части лица: нос, рот, глаза и все остальное, что у вас есть в конкретном наборе данных. Но до сих пор никто не подписался на эту утомительную задачу, поэтому проблема остается.
GANы
Если перенос стиля является одним из путей в мир аниме, то другой путь — это Generative Adversarial Network, или GAN. Еще в 2014 году знаменитый Ян Гудфеллоу (Ian Goodfellow) придумал GAN — пару конкурирующих нейронных сетей, которые могут имитировать любые данные, если дано достаточное количество образцов, достаточно хорошая сеть и достаточно времени для обучения. Некоторые недавние довольно известные приложения, включая MakeGirlsMoe и PGGAN, о котором мы подробно писали ранее.

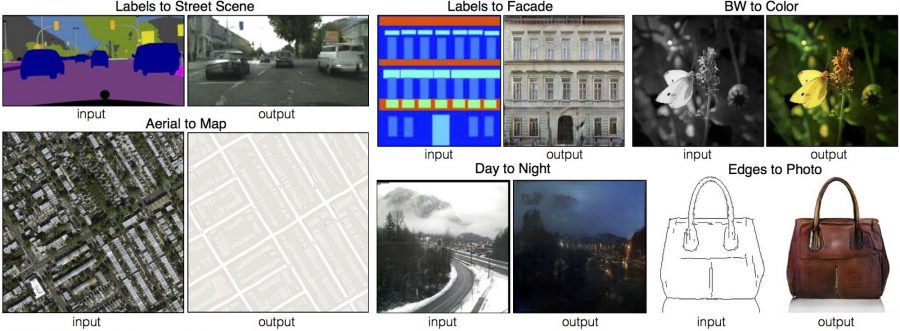
Последние GAN модели могут генерировать довольно высокое качество изображения, и это не всё. GAN также способен “переводить” один тип изображений в другой. К концу 2016 года модель под названием pix2pix была изобретена Phillip Isola и др. Изображения из двух разных доменов (например. карты и спутниковые изображения), pix2pix способен переводить с одного в другое. Тем временем, Taizan Yonetsuji из Preferred Networks представил PaintsChainer, основанную на Unet GAN модель, которая автоматически раскрашивает аниме-эскизы. Оба идеально подходят для нашего проекта. Однако оба требуют “парных данных” (по одному изображению из каждого домена). Из-за стоимости никто не публиковал парный набор данных о портретах людей и аниме.
Смотреть: Сделайте Фото на документы из селфи прямо сейчас
Непарный междоменный GAN
Когда дело доходит до непарных данных, уровень сложности совершенно другой. Это похоже на изучение нового языка без словаря. К счастью, автор не единственный исследователь, увязший в высокой стоимости парных данных. В 2016 году FAIR опубликовал документ под названием “Unsupervised Cross-Domain Image Generation”, в котором показано, как переводить два типа изображений, когда только один тип имеет метки, без парных данных. Вскоре после этого в 2017, Jun-Yan Zhu и др. ввели похожую модель под названием CycleGan, которая работает на немаркированных непарных наборах данных.

Для решения проблемы непарного набора данных обе модели делают предположение, что при переводе изображения типа A в изображение типа B и обратно в A результирующее изображение после двух переводов не должно сильно отличаться от исходного входного изображения. Используя пример текстового переводчика, когда вы переводите с английского на испанский и обратно на английский, предложение, которое получилось, не должно слишком отличаться от того, с которого вы начали. Разница между ними называется потерей согласованности циклов, которую можно использовать для обучения модели преобразования изображений, такой как CycleGAN.
Пробуем CycleGAN
Хорошая новость: у CycleGAN открытый исходный код. После клонирования репозитория git автор начал собирать тренировочные данные. Он взял 200k изображений из CelebA в качестве человеческих портретов. Затем он использовал метод, упомянутый в техническом отчете MakeGirlsMoe и насобирал около 30к аниме картинок на сайте Getchu.

После двух дней тренировок, результат выглядит так:

Выглядит нормально, но что-то не так… Оказывается, у CycleGAN есть свои ограничения. Сеть вынуждена найти взаимно однозначное сопоставление для всей информации от ввода до целевого домена, поскольку это минимизирует потерю согласованности цикла. Тем не менее, реальные и аниме изображения иногда не имеют биективного (one-to-one) отображения. Например, у людей нет волос или глаз со всеми видами цветов, и в реальной жизни лицо гораздо более подробно, чем в аниме. При выполнении преобразования изображений между ними неразумно просить сеть найти биективное сопоставление, поскольку, вероятно, такого сопоставления нет. Форсирование такой потери в сети, вероятно, не даст хороших результатов.
Вопрос заключается в следующем: как найти соответствующие части из двух доменов без помеченных данных, немного изменяя остальные?
Попробуй Еще Раз! Но с помощью другого подхода
К счастью, когда существующие методы GAN не работают, мы все еще можем отталкиваться от Style Transfer. В начале 2016 года Винсент Дюмулен (Vincent Dumoulin) из Google Brain, изучая только две переменные в Batch Normalization, обнаружил, что они могут использовать одну и ту же сеть для вывода изображений с широким диапазоном стилей. Они могут даже смешивать и соответствовать стилю, смешивая эти параметры. Их статья “A Learned Respresentation For Artistic Style” показывает, что Batch Normalization — метод, первоначально изобретенный для стабилизации обучения нейронной сети — имеет больший потенциал, чем предполагалось.
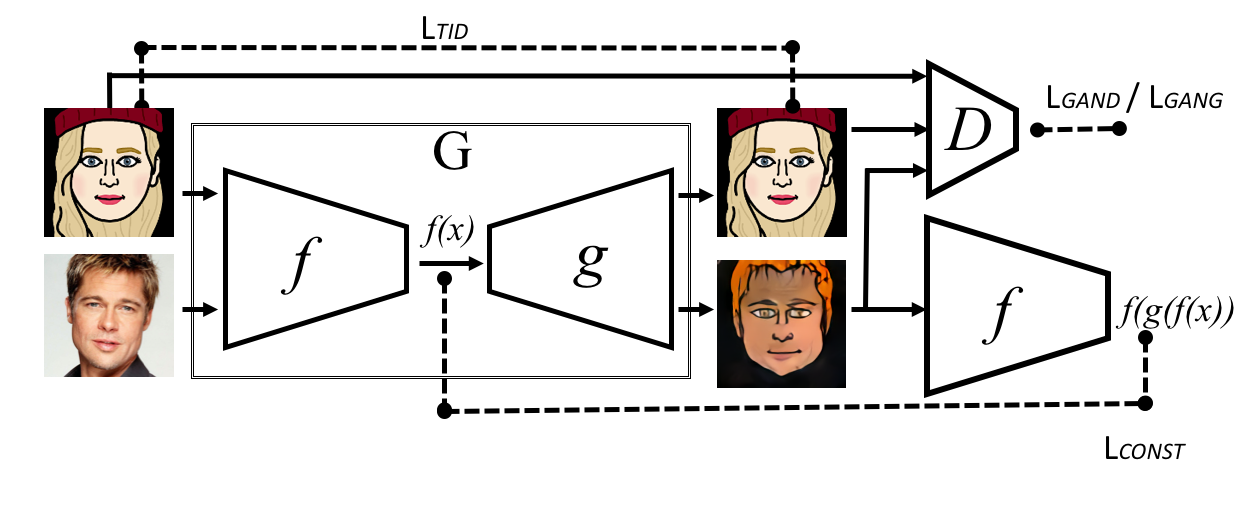
Вдохновленный методами, упомянутыми выше, автор назвал свою сеть Twin-GAN и завершил ее структуру.
Технические детали TwinGAN
Автор использовал PGGAN — передовую модель в создании изображений — в качестве генератора. Поскольку PGGAN принимает высокоразмерный вектор в качестве входных данных, а в модели входные данные — это изображения, он использовал кодировщик с структурой симметричной PGGAN для кодирования изображения в высокоразмерный вектор.
Кроме того, чтобы сохранить детали входного изображения, он использовал структуру UNet для соединения сверточных слоев в кодировщике с соответствующими слоями в генераторе. Входные и выходные данные делятся на три категории:
- Человеческий портрет → кодировщик → высокоразмерный вектор → генератор PGGAN + человеческие параметры нормализации→ человеческий портрет
- Аниме портрет → кодировщик→ высокоразмерный вектор->PGGAN генератор + аниме параметры нормализации → аниме портрет
- Человеческий портрет → кодировщик → высокоразмерный вектор→ PGGAN генератор + аниме параметры нормализации→ аниме портрет
Позволение портретам людей и аниме использовать одну и ту же сеть, помогает сети понять, что хотя они выглядят немного по-разному, портреты людей и аниме описывают лицо. Это очень важно для переноса изображений. Переключатель, который решает, выводить портрет человека или аниме, находится в параметрах нормализации.
Что касается функции потерь, автор использовал следующие четыре потери:
- Потеря реконструкции человеческого портрета;
- Потеря реконструкции портрета аниме;
- Человек к аниме Ган потеря;
- Человек к потере последовательности цикла аниме.
Результаты
После обучения результат выглядит следующим образом:

Неплохо, правда?
Twin-GAN может больше. Поскольку аниме и реальные человеческие портреты имеют одно и то же скрытое вложение, мы можем извлечь это вложение и выполнить поиск ближайшего соседа в обоих доменах. То есть для данного изображения мы можем найти наиболее близкого и в аниме и в реальных изображениях.

Большинство из них выглядят довольно точными, и мы можем объяснить работу нейронной сети. В её понимании светлые волосы девушки все еще должны быть светлыми, если они живут в мире аниме, но каштановые волосы были слишком распространены в реальном мире, поэтому она решила покрасить волосы в другие цвета. Обратите внимание на женщину посередине справа, одетую в русскую зимнюю шапку— этой шапки нет в обучающей выборке. Но обученная сеть проявляет творчество и просто думает о шапке как о другом аксессуаре для волос.
Недостатки сети также довольно очевидны из этого образа. Иногда она принимает цвет фона в качестве цвета волос, а в других случаях она отражает людей в противоположных направлениях. Такие случаи ошибок также можно увидеть на переносе изображений во время тренировки.
На самом деле, эта сеть может быть применена ко многим другим задачам. Например, что произойдет, если обучить её на изображениях кошек?

Да! Это весело. Тем не менее, во многих случаях, нельзя быть абсолютно удовлетворенным результатами работы сети. Например, если на входном изображении есть каштановые волосы, а хочется, чтобы на выходе были ярко-зеленые волосы. Модель не поддерживает прямую модификацию таких функций. Автор использовал illust2vec для извлечения характеристик, таких как цвет волос и глаз. Затем он получил некоторые идеи из Conditional generative adversarial nets и предоставил эти характеристики в качестве вложений в генератор. Теперь, когда создается изображение, оно использует дополнительного персонажа аниме в качестве входных данных, и переданный результат должен выглядеть так, как этот персонаж, с положением и выражением лица (TODO) человеческого портрета, сохраненным нетронутым. Результат следующий:

Результат пока не идеален. Но можно потратить еще немного времени на его улучшение в будущем. Самое главное: теперь есть удивительный ИИ, который может превратить человеческий портрет в кошачью морду, оригинального персонажа аниме или любого персонажа, данного на вход пользователем, поэтому больше не нужно учиться живописи.
P. S.
Одна из самых больших проблем текущего алгоритма по-прежнему лежит в обучающей выборке. Например, лица аниме, которые собрал автор, в основном женские персонажи. Нейронная сеть склонна переводить мужских персонажей в женские, потому что она их чаще видит. Она также может ошибиться с цветом фона по цвету волос, игнорировать важные характеристики и/или ошибаться в них. Случай ошибки показан ниже:

Но помимо улучшения сети, предстоит еще много новых задач. Например, как развернуть алгоритм, чтобы генерировать больше, чем человеческие лица. Как динамически изменить вывод с помощью более подробных подсказок? Или как адаптировать этот алгоритм на видео? Все это важные, но пока безответные вопросы.
Еще две вещи, которые стоит упомянуть: несколько месяцев назад Шуан Ма(Shuang Ma) предложил сеть под названием DA-GAN, которая использует карту внимания для перевода изображений, и также получил хорошие результаты. И только недавно (2018/4/15) Nvidia раскрыла фреймворк, который превращает кошек в собак. И то, и другое заставляет надеяться на более интересные будущие события в этой области.
P. P. S. Некоторые моменты в статье чрезмерно упрощены для облегчения понимания.