
That comes as no surprise that many discoveries and inventions in any domain come out of the researchers’ personal interests. This new approach to translation of human portraits is also one of these inspiring personal projects. The author of Twin-GAN, Jerry Li, was interested in anime, but not satisfied with his attempts to draw his favorite characters. So, when he started doing machine learning, he arrived at the question: “How to turn human portraits into anime characters using AI?”. And voila, now we have a tool that can turn a human portrait into an original anime character, a cat face or any character given by the user.
But let’s, first, check the previous attempts at teaching AI how to draw.
Neural Style Transfer. Within this approach, the style of one image is applied to another, as you can see below. The important notion is that style transfer method requires a trained object detection network. Most such networks are trained on real-life objects. So, this solution is not likely to help with anime style, unless you create a new dataset manually by hiring labelers to label all the noses, mouths, eyes, hair and other specific features. But that’s going to cost you LOTS of money.

Generative Adversarial Network (GAN) is another way to the anime world. GAN includes a pair of competing for neural networks that can mimic any data given enough samples, good enough network, and enough time for training. Below you can see incredibly realistic faces generated using progressive growing of GANs (PGGAN).

Besides generating pretty high-quality images, GAN is also capable of translating one type of images into another. However, this approach requires paired data (one image from each domain), but unfortunately, there is no paired datasets on human and anime portraits.
Unpaired cross-domain GAN and CycleGAN. Luckily, FAIR in 2016 (Unsupervised Cross-Domain Image Generation) and Jun-Yan Zhu et.al. in 2017 (CycleGAN) introduced quite similar approaches on how to translate two type of images, with one type having labels, without paired data. Both of the models assume: when translating image type A to image type B, and translate B back to A, the resulting image after two translations should not be too different from the original input image. This difference, that anyway occurs, is called the cycle consistency loss, and it can be used for training an image translation model.
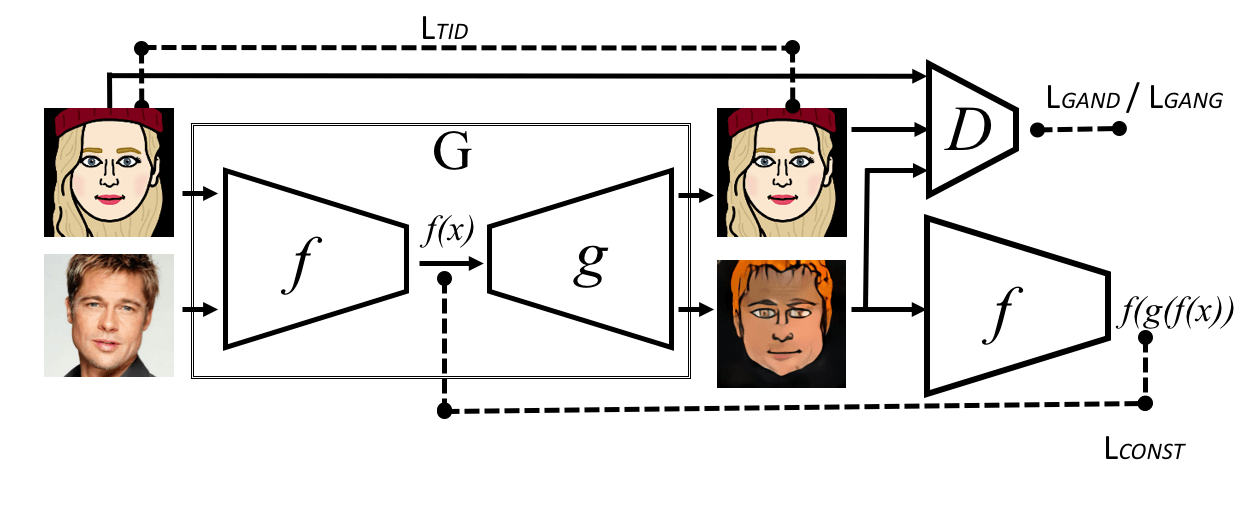
So, before creating Twin-GAN, Jerry Li tried to use CycleGAN for translation of human portraits into anime characters. He took 200K images from CelebA dataset as human portraits and around 30K anime figures from Getchu website. Two days of training and he got the results depicted below.

The results are not bad, but they reveal some limitations of CycleGAN. This network is minimizing the cycle consistency loss, and hence, it is forced to find a one-to-one mapping for all information from the input to the target domain. However, this is not always possible between human portraits and anime characters: people usually don’t have purple or green hair color and their faces are much more detailed than in anime. Forcing the network to find a one-to-one mapping in such circumstances will probably not yield good results.
So, the question was: without labeled data, how to find the matching parts from the two domains and innovate a little bit on the rest?
To solve this issue, Jerry Li looked for some inspirations from Style Transfer. He refers to Vincent Dumoulin from Google Brain, who has found that by only learning two variables in Batch Normalization, it is possible to use the same network to output images with a wide range of styles. Moreover, it is even possible to mix and match the style by mixing those parameters.
With these ideas in mind, the structure of Twin-GAN was finally created. PGGAN was chosen as a generator. This network takes a high dimensional vector as its input, and in our case, an image is an input. Thus, the researcher used an encoder with structure symmetric to PGGAN to encode the image into the high dimensional vector. Next, in order to keep the details of the input image, he used the UNet structure for connecting the convolutional layers in the encoder with the corresponding layers in the generator.
The input and output fall into the following three categories:
1. Human Portrait->Encoder->High Dimensional Vector->PGGAN Generator + human-specific-batch-norm->Human Portrait
2. Anime Portrait->Encoder->High Dimensional Vector->PGGAN Generator + anime-specific-batch-norm->Anime Portrait
3. Human Portrait->Encoder->High Dimensional Vector->PGGAN Generator + anime-specific-batch-norm->Anime Portrait
The idea behind this structure is that letting the human and anime portraits share the same network will help the network realize that although they look different, both human and anime portraits are describing a face. This is crucial to image translation. The switch that decides whether to output human or anime portrait lies in the batch norm parameters.
Regarding the loss function, the following four losses were used: 1) human portrait reconstruction loss; 2) anime portrait reconstruction loss; 3) human to anime GAN loss; 4) human to anime cycle consistency loss.
Here are the results of translating human portraits into anime characters using Twin-GAN.

The results are quite impressive. But it turned out that Twin-GAN can do even more. Since anime and real human portraits share the same latent embedding, it is possible to extract that embedding and do the nearest neighbor search in both domains. To put it simply, given an image, we can find who looks the closest in both real and anime images! See the results below.

Although the results are quite good with only a few error cases, sometimes you might not be satisfied with the image translation result due to some personal preferences or requests. For example, if the input image has brown hair and you want the anime character to have bright green hair, the model won’t allow you to make direct modifications of such features.
In these cases, you can use illust2vec to extract character features that you wish to copy, supply those features as embeddings to the generator, and then, when generating an image, add an additional anime character as input. The final result should look like that additional character, with the position and facial expression of the human portrait. See some examples below:

Twin-GAN can turn a human portrait into an original anime character, cat face or any character given by the user, and the algorithm demonstrates quite a good performance when completing these tasks. However, it is also prone to some errors like mistaking the background color for hair color, ignoring important features and/or misrecognizing them. When considering anime characters generation, the problem is also with the availability of well-balanced dataset: most of the anime faces collected by the researcher are female, and so the network is prone to translating male human portraits into female anime characters, like on the image below.

To sum up, this is a great start, but some more work needs to be done to improve the performance of this budding approach.








