
The deep learning prerequisites: The NumPy stack in Python course from The Lazy Programmer is a course offered on Udemy. It is the first course in a long series of courses that are focussed on teaching Deep Learning using python. This series (especially the first few courses) goes through the main libraries used in data science to do most of the basic work (data wrangling, exploratory data analysis, simulations, etc.). The NumPy course goes through NumPy, Pandas, Matplotlib and SciPy, all of which you will be using every day if working in data science or machine learning.
Requirements
The NumPy stack in Python course has pretty low requirements, as it is the first or one of the first courses of the deep learning series. You need to understand basic Python syntax, as well as basic linear algebra and statistics. Other than being able to perform basic Python commands, the other requirements are pretty soft requirements. For the rest of the Deep learning series, those requirements are more and more important, but if you only plan on doing this course, you can get by without them.
Contents of the course
As said previously, the course goes through 4 of the well-known python data libraries.
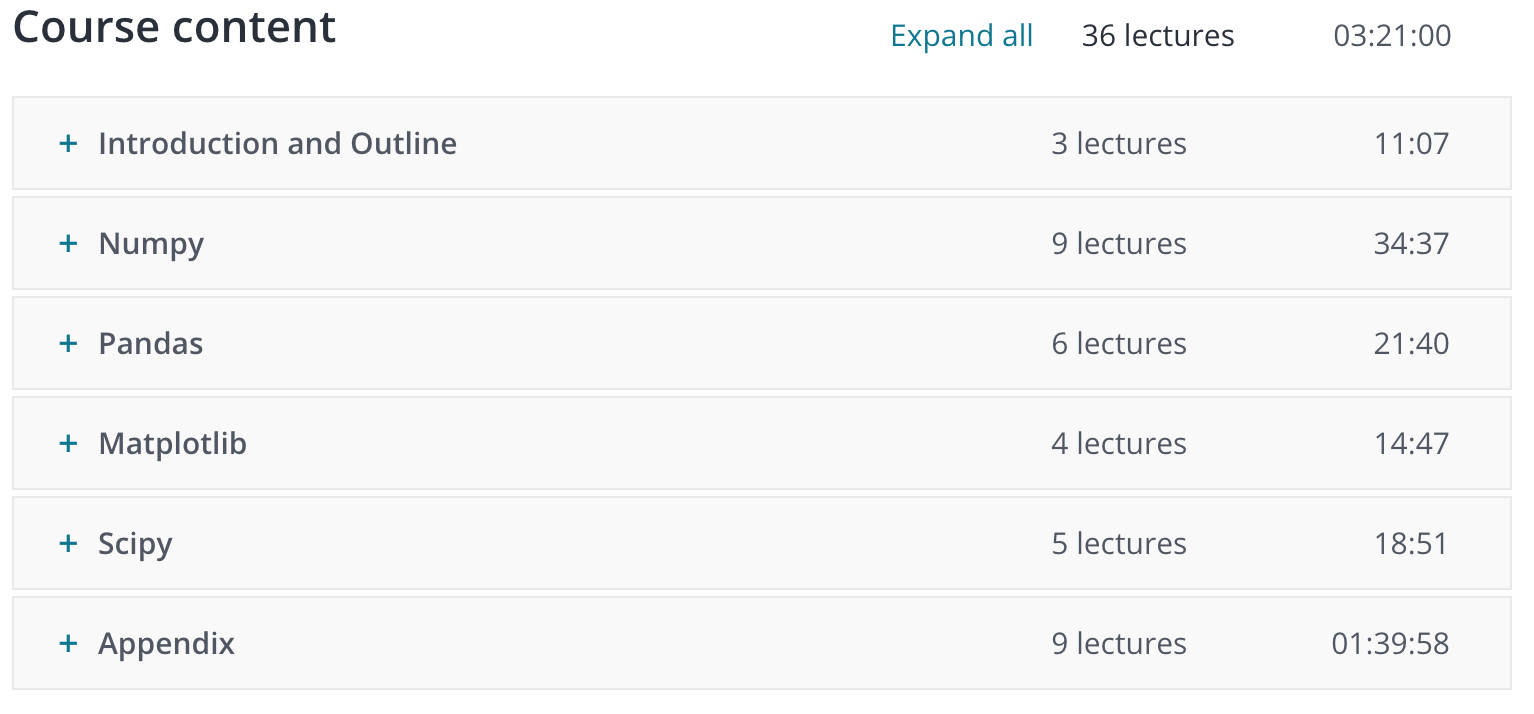
NumPy
First, The Lazy Programmer teaches NumPy, which is a scientific computing library used to perform various linear algebra operations, like dot product, matrix inversion, data slicing, and others. The teaching of the NumPy stack is quite linear and robotic. It goes through every single useful function for machine learning, gives an example and moves on. The examples are very dry and only contain numbers out of context. It feels like you are listening to an audio-book of NumPy’s documentation. Nonetheless, even for seasoned NumPy users, it can be useful to have a refresher on all of the functions offered, since you can always write cleaner or faster running code.
Pandas
The course then moves on to Pandas, a very popular library which provides data structures and tools for data analysis. The data frame is a data structure that can manipulate data (add or remove columns, apply functions to columns, merge data frames and others). Pandas can also be used to scrape tables from the web and transform them into data frames. This part of the course is very similar to the NumPy section, in that examples are quite cut and dry. It is still insightful and an excellent review for any serious Pandas user.
Matblotlib
The next library is matplotlib, a simple graphing library. This section is a very brief introduction to matplotlib, as in it only teaches 3 types of graphs (line, scatter and histogram). This section leaves out some of the more confusing concepts, like multiple axis graphs, or multiple graphs on a single panel. It can be argued that those concepts are not as useful as part of the deep learning series. However, a quick introduction would have been nice.
SciPy
The final section looks through a small portion of the SciPy library. The SciPy library is a package for scientific computing for mathematicians, engineers, and data analysts. The SciPy stack is built on top of the previous 3 packages, as well as others. This course teaches statistical distributions in SciPy, which is a small part of the package. The teacher goes through gaussian distribution, how to simulate data given distribution and how to find the probability of an event given a distribution.
Price and certificate
The NumPy stack in Python course does not offer any certificate, and the advertised price is around 200$. However, there is always a discount going on, and you can expect to pay around 10-20$.
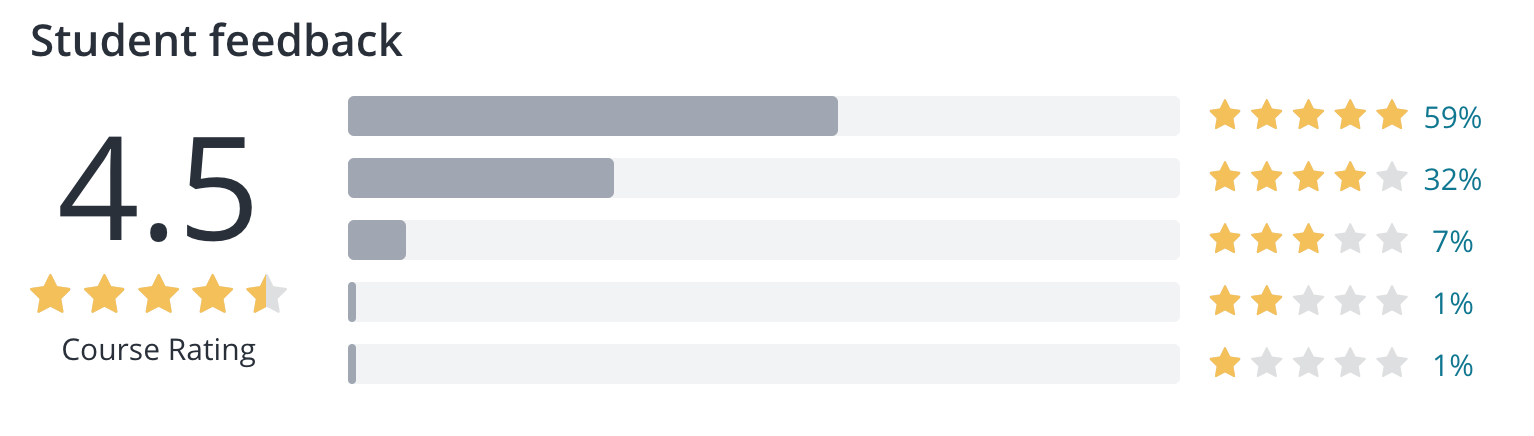
Overall, this is an excellent introduction to popular scientific libraries used for data manipulation and analysis. It is not the most engaging course; however, the material needs to be learned for anyone looking to work in the field or continue through the rest of the deep learning series.



