Mathematical reasoning stands as a crucial benchmark for artificial intelligence systems, requiring logical deduction, symbolic manipulation, and multi-step problem-solving. Recent breakthroughs in AI reasoning have been significantly driven by reinforcement learning (RL) techniques applied to large language models (LLMs). However, this progress faces a critical bottleneck: the scarcity of suitable training data.
The Data Gap in Mathematical Reasoning
While reinforcement learning methods like RL-Zero have demonstrated remarkable potential in enhancing mathematical reasoning capabilities in LLMs, their advancement has been hampered by several critical limitations in available datasets. Existing collections often lack problems challenging enough to push current models to their limits. Many don’t provide standardized answer formats needed for rule-based reinforcement learning. Data frequently overlaps with evaluation benchmarks, compromising assessment integrity. Perhaps most importantly, there’s a significant shortage of high-difficulty problems at scale, which are essential for training advanced reasoning capabilities.
DeepMath-103K Key Characteristics
To address these constraints, researchers from Tencent and Shanghai Jiao Tong University have developed DeepMath-103K, a large-scale mathematical dataset specifically engineered to accelerate the development of advanced reasoning models via reinforcement learning.
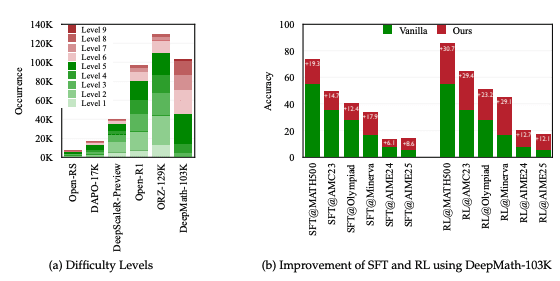
DeepMath-103K distinguishes itself through several critical features that address the limitations of existing datasets. The dataset contains approximately 103K mathematical problems, with 95K specifically curated challenging examples (Levels 5-10) and 8K supplementary problems (Levels 3-5), providing the high-difficulty focus needed to push reasoning boundaries. Every problem includes a verifiable final answer, enabling the direct application of rule-based reward functions essential for RL frameworks.
What further sets this dataset apart is that each problem comes with three distinct R1-generated solutions, supporting diverse training paradigms including supervised fine-tuning, reward modeling, and model distillation. The dataset underwent comprehensive decontamination against standard benchmarks like MATH, AIME, AMC, Minerva Math, and OlympiadBench, ensuring evaluation integrity. Problems span a broad spectrum of mathematical domains from foundational concepts to advanced subjects, promoting generalizable reasoning abilities across different mathematical areas.

Dataset Construction Process
The DeepMath-103K dataset was constructed through a meticulous four-stage curation process. Initially, researchers conducted thorough source analysis, analyzing difficulty distributions across existing open datasets and selecting those with higher concentrations of challenging problems, primarily MMIQC and WebInstructSub. This was followed by comprehensive data decontamination, where a rigorous process using embedding similarity search and LLM-based comparison identified and removed potential paraphrases of benchmark questions.
The third stage involved difficulty filtering, where problems were classified using the Art of Problem Solving (AoPS) guidelines, with researchers retaining only those at difficulty level 5 or higher. Finally, an answer verification stage employed a two-stage process to ensure each problem possessed a consistently verifiable final answer across multiple solution paths, critical for enabling rule-based reinforcement learning approaches.
Impressive Performance Gains
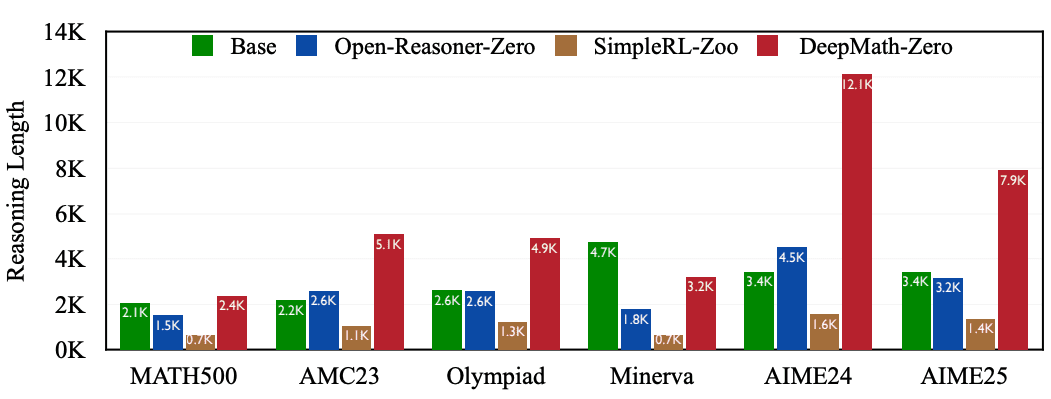
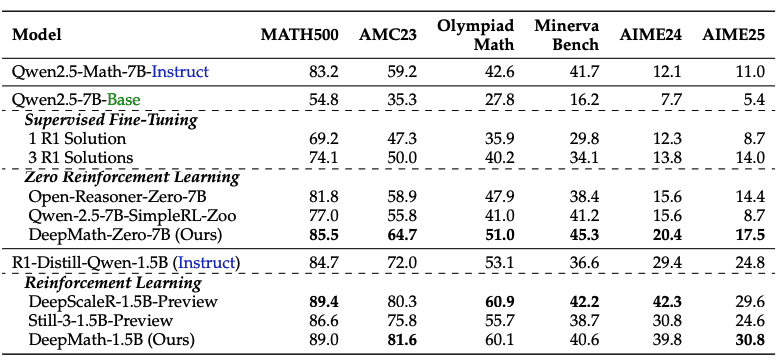
The impact of DeepMath-103K on model performance is remarkable. Models trained using this dataset achieved substantial improvements across challenging mathematical benchmarks. On MATH500, a model trained with DeepMath-103K through RL-Zero improved from 54.8% to 85.5% accuracy—a 30.7 percentage point gain. For the notoriously difficult AIME24 benchmark, the improvement was from 7.7% to 20.4%, representing a 2.6x increase in performance.
The dataset’s effectiveness extends across multiple benchmarks: AMC23 saw accuracy improvements from 35.3% to 64.7% (+29.4 points), while Olympiad Math tasks improved from 27.8% to 51.0% (+23.2 points). When applied to models already supervised fine-tuned for mathematical reasoning, DeepMath-103K still delivered significant gains, with AIME25 accuracy rising from 24.8% to 30.8%.
The construction process itself was computationally intensive, requiring an expenditure of 138,000 US dollars in GPT-4o API fees and a total of 127,000 H20 GPU hours — demonstrating the significant investment needed to create such a high-quality resource.
Application Versatility
DeepMath-103K’s design enables remarkable versatility across multiple training paradigms. In supervised fine-tuning scenarios, the multiple solution paths enable models to learn diverse problem-solving strategies, moving beyond single-path approaches that limit generalization. For model distillation, the various solution trajectories facilitate effective knowledge transfer from larger teacher models to smaller student models, enhancing efficiency while preserving reasoning capabilities.
The dataset particularly shines in rule-based reinforcement learning contexts, where verifiable answers allow straightforward reward assignment critical for methods like RL-Zero. Additionally, researchers working on reward modeling benefit from the multiple valid solutions, which enable differentiation between high and low-quality reasoning steps, supporting more nuanced training signals.
Significance for AI Research
The release of DeepMath-103K represents a significant contribution to the AI research community, addressing a critical resource gap in mathematical reasoning development. By providing a large-scale dataset of challenging, verifiable, and decontaminated problems, it enables researchers to train more powerful reasoning models and advance the field toward more robust mathematical capabilities.
The dataset demonstrates the value of carefully curated training data in pushing the boundaries of LLM reasoning abilities, showing that exposure to appropriately challenging problems with verifiable answers can significantly enhance performance on complex mathematical tasks.