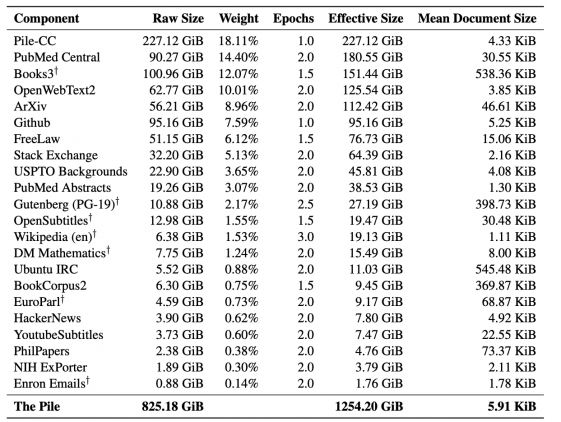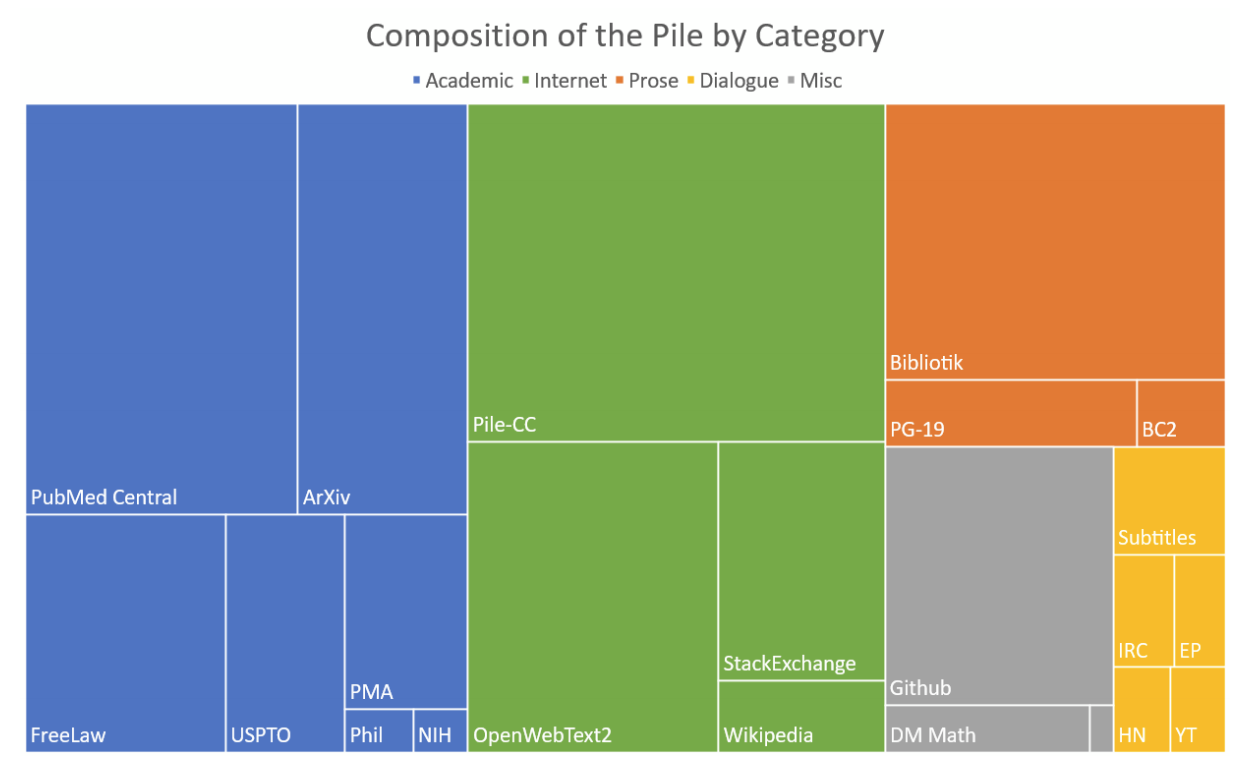
Pile is an 825 gigabyte dataset for teaching language models. The dataset consists of 22 smaller datasets, which are combined into one. In addition to the dataset, the creators published a benchmark for testing language models for the quality of modeling.
Pile benefits
For large state-of-the-art models, the diversity in training data sources improves the overall generalizability of the model. According to the results of experiments, the models that were pre-trained on Pile show better results on the standard benchmarks for language modeling. They also bypass approaches trained on other data on the Pile BPB benchmark.
To get high speed on Pile BPB, the model must understand many different domains, including books, GitHub repos, web pages, chat logs, and mathematical, medical and physics research papers. Pile BPB measures the knowledge of a model across domains and how capable the model is of formulating coherent texts within those domains. This allows for robust evaluation of generative models for text data. Details of the data and benchmark are described in the original article.