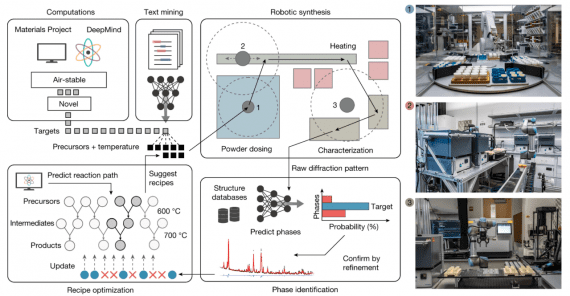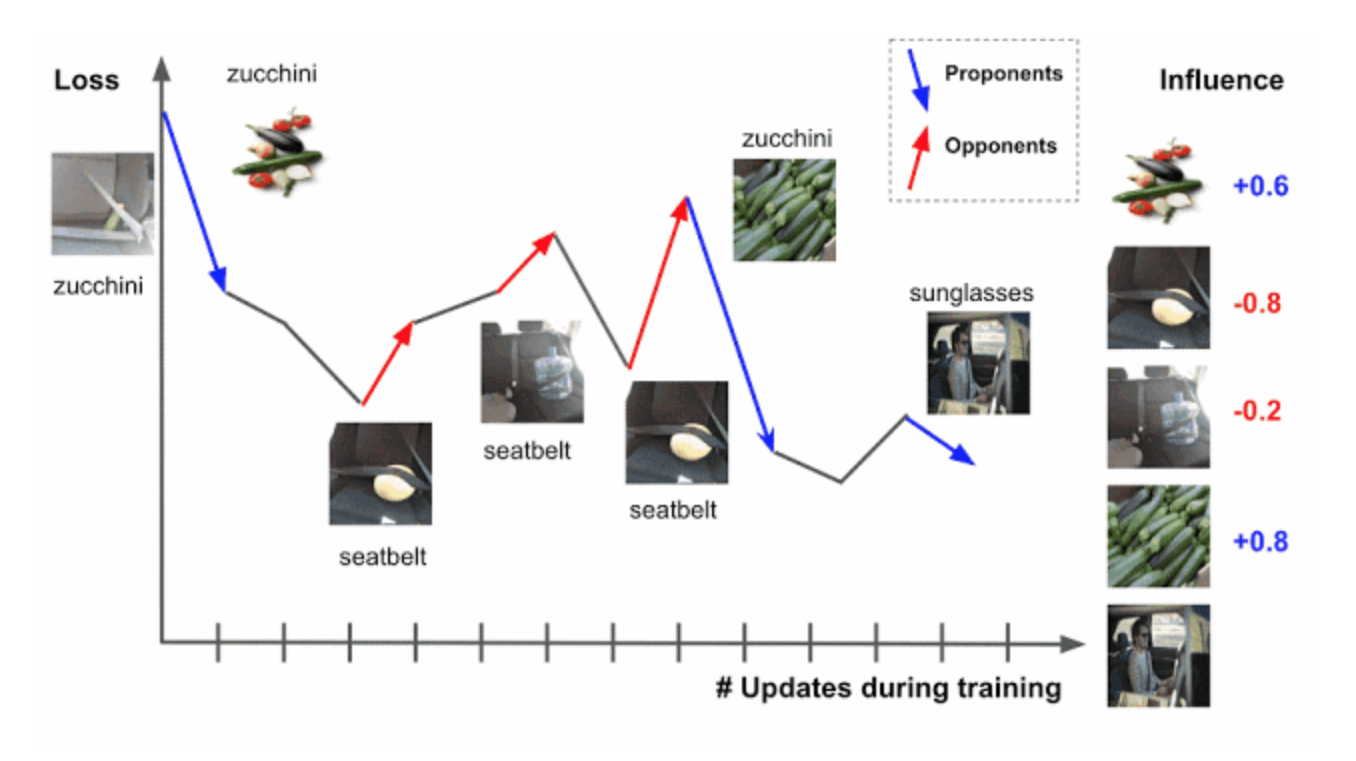
TracIn is a scalable method for assessing the impact of individual features in data on predictions. The idea behind TracIn is to track the learning process of the model to detect changes in predictions as we move from one data object to another. With TracIn, you can find data markup errors and outliers. The method allows one to explain predictions using the example of objects from the training sample. The approach was suggested by researchers at Google AI.
The quality of the data for training ML models significantly affects the predictive power of the models. One metric of data quality is the impact of the specific data on model predictions. The calculation of such a metric for neural network models is complicated by the growing size of the models, features, and datasets.
Previous approaches to calculating the impact metric were based on:
- changes in the accuracy of the model, if you train it again without one or more objects from the training set;
- statistical methods (functions of influence);
- on presentation methods that decompose prediction into a weighted combination of training examples.
These methods do not scale to large-scale neural network models. TracIn solves scaling limitations.
More about the algorithm of TracIN
TraceIn is the scalar product of the gradients of the loss function on the training example and on the test case, weighted by the learning rate parameter at different stages of model training and summed up. The method does not use the stochastic gradient descent. TraceIn is adaptable to any dataset and neural network architecture.