
In images, almost always the main objects within the depth-of-field are in focus and all other objects including the background are blurred, at least to some extent. This happens due to the natural limitations of optical lenses and it is a difficult task to produce an image with all objects in focus.
To tackle exactly this problem, researchers from the University of Science and Technology Beijing and the Norwegian University of Science and Technology proposed a new deep neural network that fuses a set of different images and produces a single, all-in-focus image. Their network called Gradient Aware Cascade Network (GACN) simultaneously generates a fused image as a result of end-to-end training. In addition to the novel network, researchers also proposed a novel loss function that is supposed to “preserve” the gradient information in the output image.
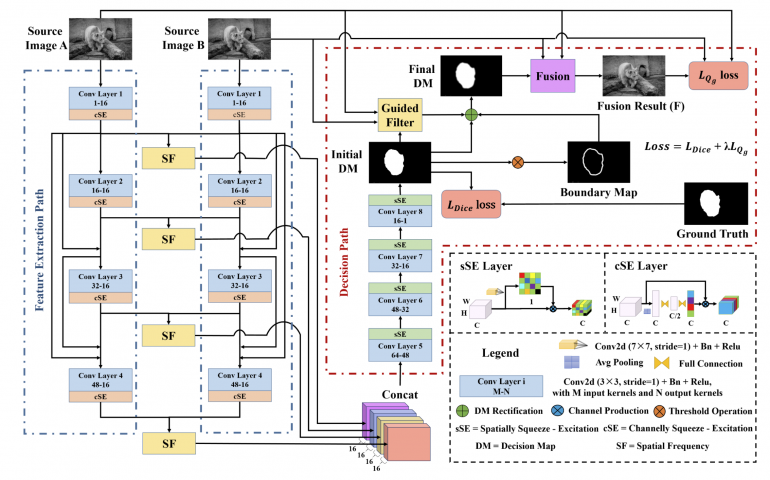
The complex proposed architecture consists of two main paths: the feature extraction path and the decision path. The feature extraction part of the model tries to extract multi-scale features from each of the sets of images and uses dense connections to fuse the output of each layer to the other layers. Researchers do not employ pooling layers in the feature extraction network in order to avoid loss of details. Then, from the extracted features, researchers compute multi-scale activity level maps for each scale. These concatenated paths are given to the decision path module, which is responsible for deciding which parts of which images should be fused.
The decision path module calculates a so-called decision map, which basically tells which pixels from which image is more clear than the rest of its correspondents. This decision map is iteratively updated and boundaries are smoothed applying some threshold operations on the initial decision maps. In the end, the initial decision map is fused with a smoothed decision map to generate the fused output using the source images.
Researchers conducted extensive experiments comparing the proposed method with recent state-of-the-art image fusion methods. For the training and experimentation, researchers generated a multi-source image dataset from the popular MS-COCO dataset. According to researchers, the experiments showed that the method is able to successfully fuse an all-in-focus image and increase the image quality over existing baselines, while at the same time improving the implementation efficiency.
The paper was published on arxiv. Researchers open-sourced the implementation of GACN network and it can be found on Github.


