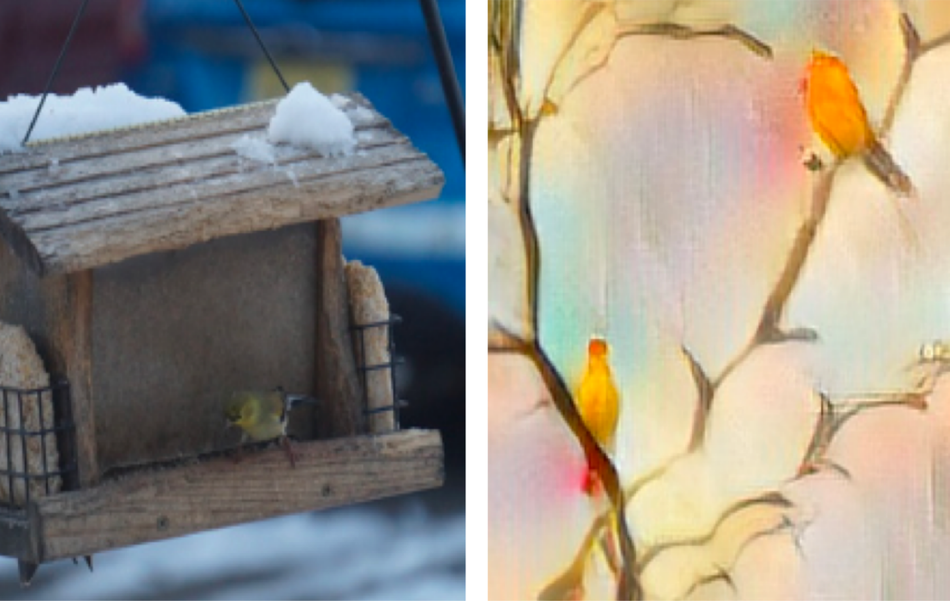
Adversarial examples are instances with small, intentional feature perturbations that cause a machine learning model to make a false prediction. A number of methods for generating but also defending from adversarial attacks have been proposed in the past.
A group of researchers from Google has explored a different idea where adversarial examples are actually used to improve image recognition models. They published a paper “Adversarial Examples Improve Image Recognition”, in which they propose a new training method that considers adversarial samples to additionally improve robustness.
The key idea behind the method is the use of a separate batch norm for adversarial examples. The reason behind this is the hypothesis that adversarial examples as such have different underlying distribution than normal examples.
Researchers argue that batch normalization behavior can be problematic if the mini-batch contains samples from different distributions. To incorporate adversarial examples and overcome this problem they decided to add a different batch normalization for adversarial examples. In the paper, they note that this concept can be generalized to multiple auxiliary batch normalization layers in the case of having several different distributions in the training set.
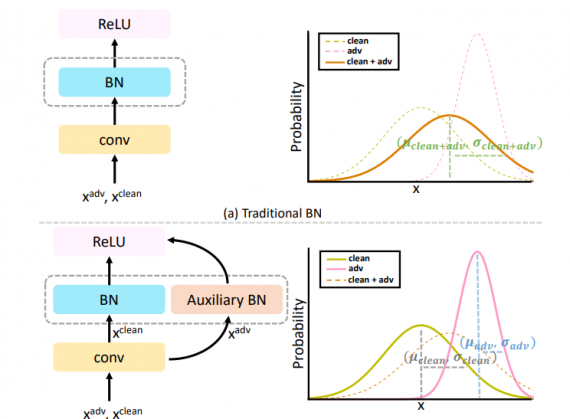
Evaluations showed that the proposed method – AdvProp improves the image recognition accuracy of a wide range of models and the improvement is more significant in bigger models. More details about the implementation and the evaluation of the method can be read in the paper published on arxiv. The models are available on Github.


