
A group of researchers from the University of UT Austin and Intel Labs have proposed a new model that learns how to perform urban driving by “cheating”.
In their latest paper named “Learning by Cheating”, researchers explore an interesting idea where they train an agent to drive by giving it access to some “privileged” information. As the name suggests, the agent is “cheating” in some way, since it is not supposed to have this kind of information from the environment. This information is, in fact, a partial ground truth information about the state of the environment.
The framework that researchers proposed is a student-teacher framework, where a “privileged” agent is used to teach a new purely vision-based agent. Within this framework, there are two stages: the first one where an agent is trained with access to privileged information and the second where this agent is used to teach a new agent. The second or the student agent does not cheat as it is not given any access to privileged information.
According to researchers, this approach has a number of advantages and it actually outperforms the direct imitation learning approach. In their paper, they mention that this decomposition of the problem in a two-stage learning process is more effective due to the division of tasks between these two stages or agents. The first, “privileged” agent has perception already solved by being provided the exact state of the environment and is focusing on learning the actions, while for the second agent the primary responsibility is to see (focus on its perception) and the acting is solved by the available supervision from its teacher.
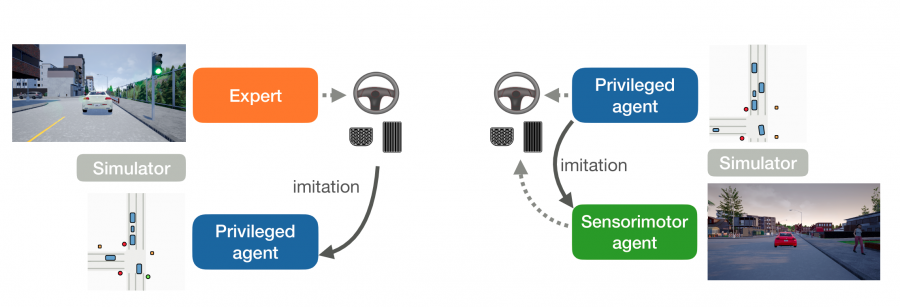
Researchers implemented and evaluated the proposed using the CARLA simulator. They built the two agents as separate neural networks which had ResNet as a backbone and different heads. The agents were trained to output one of the four high-level driving commands: “follow lane”, “turn left”, “turn right” and “go straight”.
The evaluations showed that the method achieves 100% success on all tasks in the CARLA benchmark and sets a new record on the NoCrash benchmark. The method outperformed existing state-of-the-art methods on the CARLA and NoCrash benchmarks.
Researchers open-sourced the implementation of the method and it can be found here. More details about the agents and the evaluation can be read in the paper published on arxiv.


